
Create robust data pipelines from just a few lines of code to power one model or thousands simultaneously—Tecton automatically compiles, orchestrates, and maintains them for you

Unify your ML data workflows on a single platform, fostering feature reusability, swift iteration in complex production environments, and accelerating deployment across various use cases

No data left behind: Capitalize on all data types for current batch use cases and effortlessly evolve to real-time ones, cementing enduring value for your evolving ML platform

Serve features at extreme scale, mitigate infrastructure overhead, and optimize cloud spend with the confidence that systems will always be up and running




With Tecton, anyone on the team can discover and use existing features, all while monitoring associated data pipelines, serving latencies, processing costs, and underlying systems of their machine learning applications.

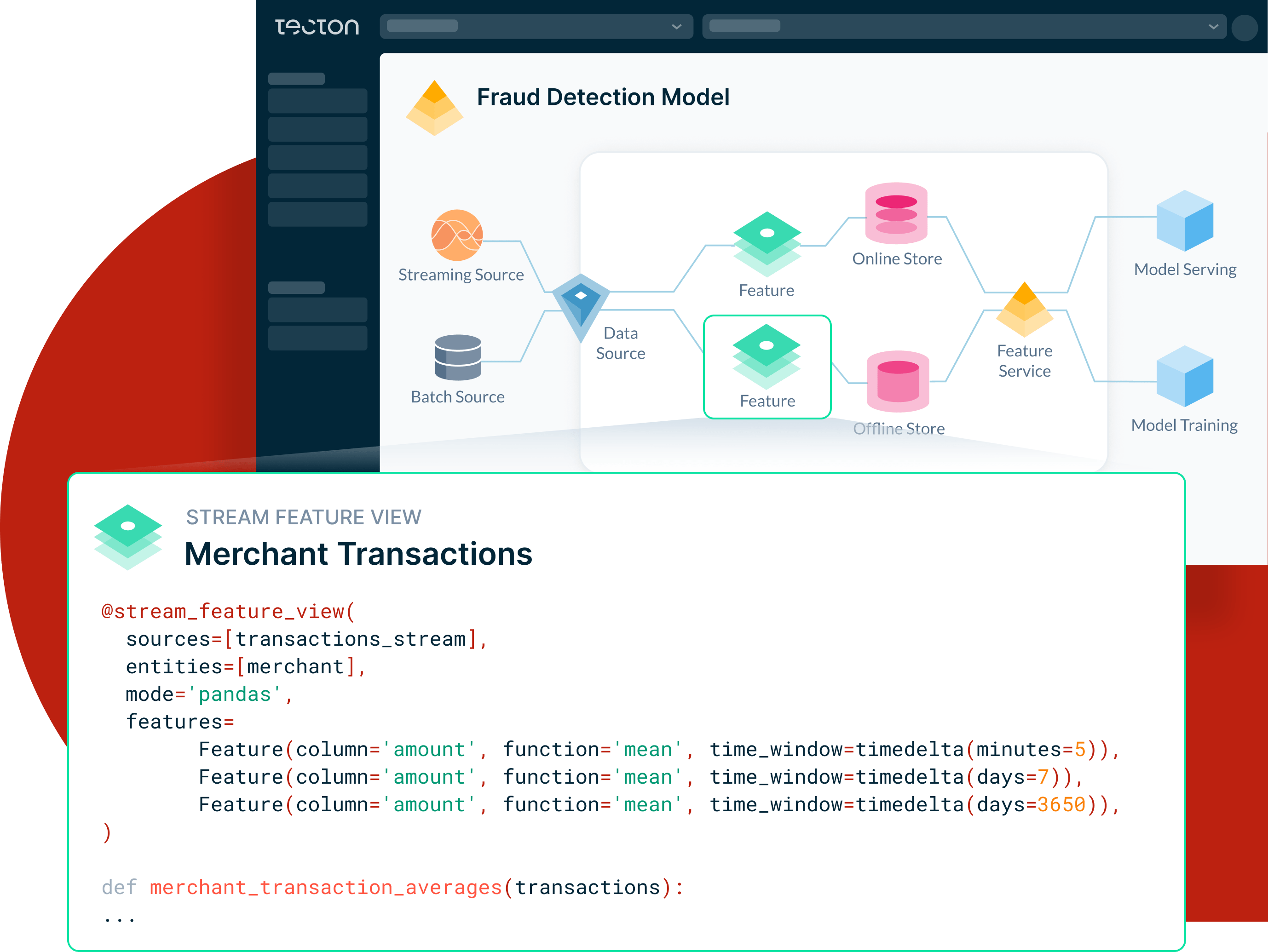
By using the SDK in a notebook or any other Python environment, users can define feature logic in Python, SQL or Spark, and rely on Tecton to execute complex data transformations like time-window aggregations or generate training data with accurate backfills.
Tecton’s feature repository lets users manage feature definitions as files in a git-like repository. With Tecton, users define features in code, version control them in git, unit test them, and roll them out safely using Continuous Delivery pipelines. With Tecton, bring battle-tested DevOps software practices to feature engineering.

Tecton integrates with existing data processing and storage infrastructures to automatically compile the underlying data pipelines that compute batch, streaming, or real-time features, insulating the end user from their complexity.

Based on a user’s pre-defined requirements, Tecton helps organizations scale compute, storage, and serving independently to adjust to usage patterns, and leverages an offline store for large-scale and low-cost retrieval (training) and an online store for low-latency retrieval (online serving). Tecton's feature store provides uninterrupted access to fresh features on demand.



Tecton makes it easy to deploy and operate machine learning with a managed, cloud-native service.

Tecton is built for scale, delivering median latencies of ~5ms and supporting over 100,000 of requests per second.

Tecton is not a database or a processing engine. It plugs into and orchestrates on top of your existing storage and processing infrastructure.

Tecton authenticates users via SSO and includes support for access control lists. We support GDPR compliance in your ML applications, and are SOC2 Type 2 certified.


