A Practical Guide to Building an Online Recommendation System


Have you ever wondered how TikTok can recommend videos to you that were uploaded minutes ago? Or how YouTube can pick up on your brand-new interest immediately after you watched one video about it? Or how Amazon can recommend products based on what you currently have in your shopping cart?
The answer is online recommendation systems (or recommender systems or recsys). These systems can generate recommendations for users based on real-time contextual information, such as the latest item catalog, user behaviors, and session context. If you’re interested in building an online recommendation system or trying to take your existing system to the next level, then this blog post is for you.
I worked as a tech lead on the YouTube Homepage Recommendations team from 2018 to 2021, focusing on long-term user satisfaction metrics. While at YouTube, I learned from some of the best minds in the business, who had been building and refining the world’s largest recommendation engine for close to a decade. Since 2021, I’ve been with Tecton and have worked with many smaller companies building and refining their search and recommendation systems.
In this blog post, I will give an overview of online recommendation systems, the various approaches for building different subcomponents, and offer some guidance to help you reduce costs, manage complexity, and enable your team to ship ideas.
Overview
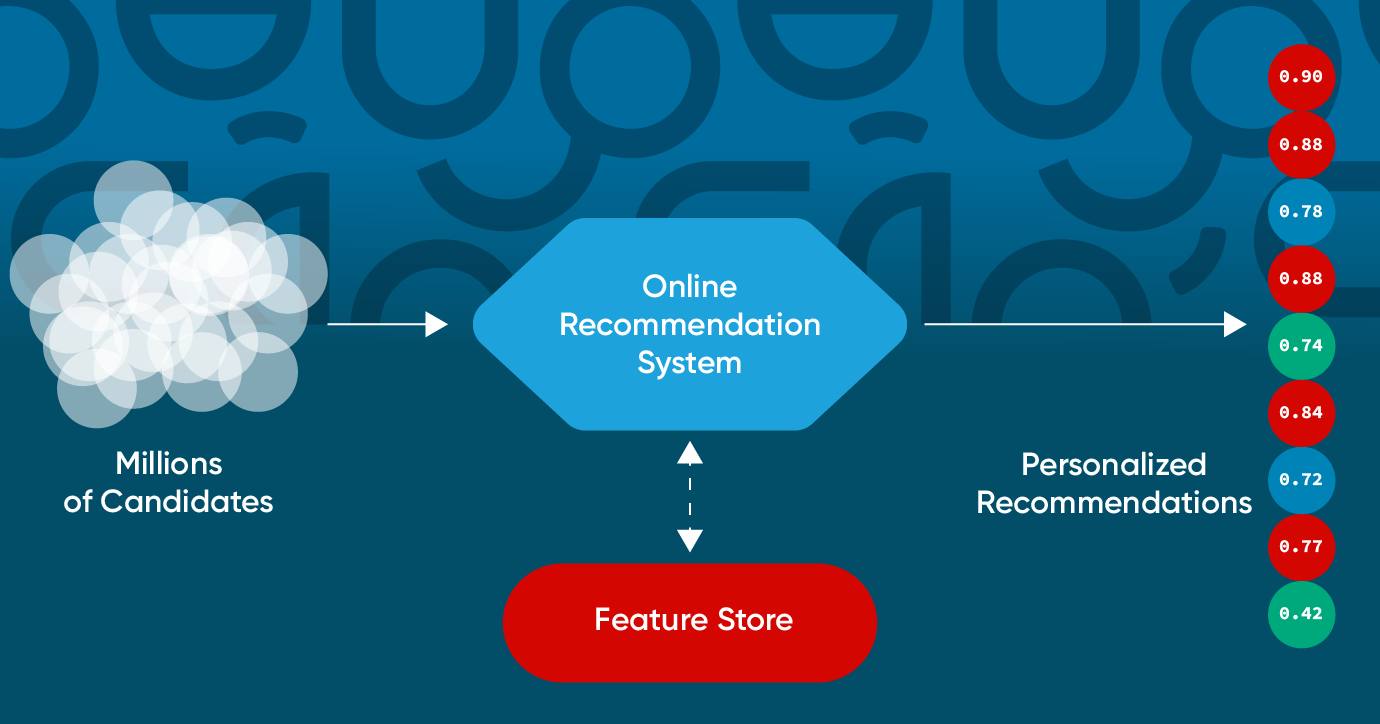
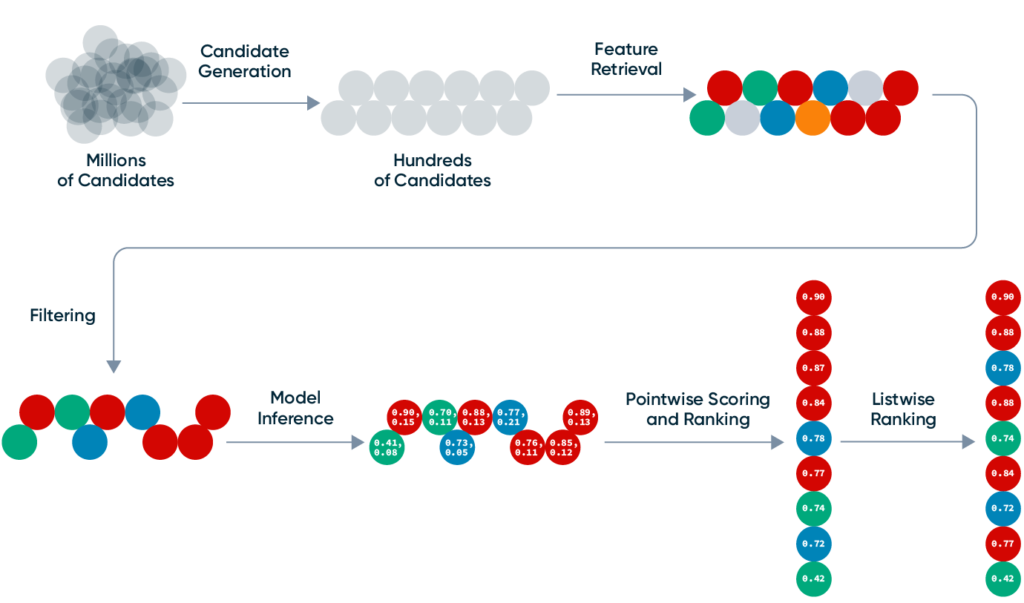
While online recommendation systems can vary substantially, they are all generally composed of the same high-level components. Those are:
- Candidate generation
- Feature retrieval
- Filtering
- Model inference
- Pointwise scoring and ranking
- Listwise ranking
Candidate generation
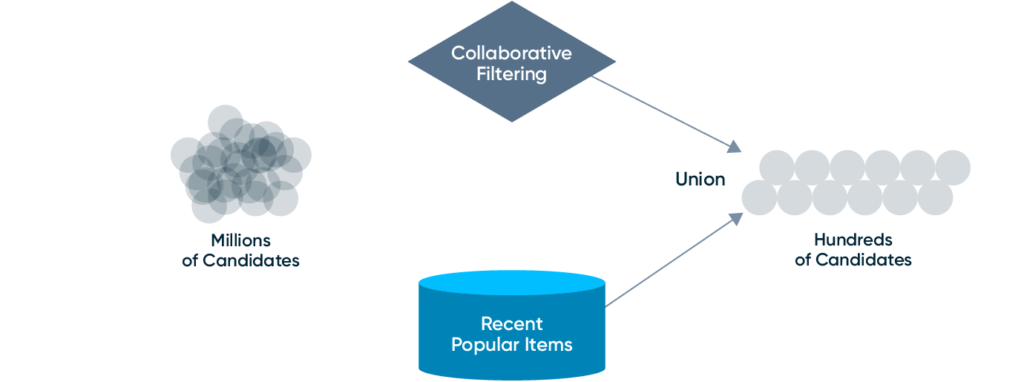
Candidate generation is responsible for quickly and cheaply narrowing the set of possible candidates down to a small enough set that can be ranked. For example, narrowing a billion possible YouTube videos down to ~hundreds based on a user’s subscriptions and recent interests. A good candidate generation system produces a relatively small number of diverse, high-quality candidates for the rest of the system.
There are many different options that can make effective candidate generators:
- Query your existing operational database
- E.g., query Postgres for a user’s recently purchased items.
- Create a dedicated “candidate database” in a key-value store.
- E.g., use Redis sorted sets to track popular items in a given locale, or
- run a daily batch job to generate a list of 500 candidates for every user and load those candidates into DynamoDB.
- Vector/Embedding similarity-based approaches
- Many different ML approaches that can learn “embeddings” for users and items. These approaches can be combined with vector search technologies like Faiss, Annoy, Milvus, and Elasticsearch to scale to online serving.
- See this blog post for an excellent discussion on the state of the art using approximate nearest neighbor search in conjunction with a two-tower deep neural network.
- Collaborative Filtering/Matrix Factorization also falls into this category. For lower scale or less mature systems, a basic collaborative filtering model may also be used directly in production.
Every approach will have its pros and cons with respect to complexity, freshness, candidate diversity, candidate quality, and cost. A good practice is to use a combination of approaches and then “union” the results in the online system. For example, collaborative filtering models can be used to generate high-quality candidates for learned users and items, but collaborative filtering models suffer from the cold-start problem. Your system could supplement a collaborative filtering model with recently added, popular items fetched from an operational database.
Feature retrieval
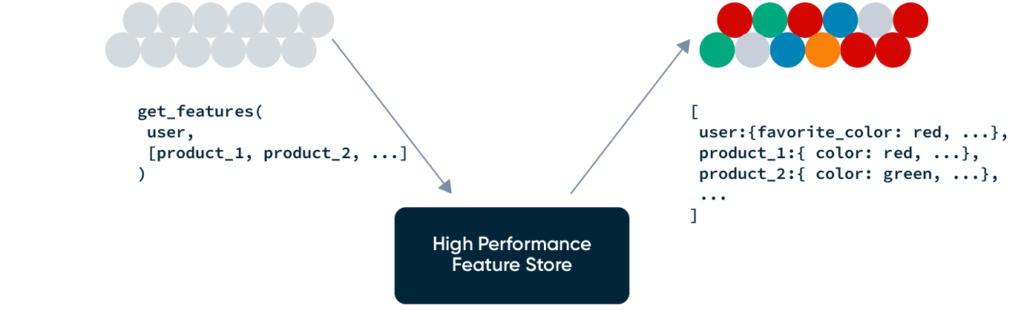
At one or more points, the recommendation system will need to look up or compute data/features for the user and the candidates being considered. This data will fall into three categories:
- Item features
- E.g.,
product_category=clothingoraverage_review_rating_past_24h=4.21
- E.g.,
- User features
- E.g.,
user_favorite_product_categories=[clothing, sporting_goods]oruser_site_spend_past_month=408.10
- E.g.,
- User-Item cross features
- E.g.,
user_has_bought_this_product_before=Falseorproduct_is_in_user_favorite_categories=True - Cross features like these can be very helpful with model performance without requiring the model to spend capacity to learn these relationships.
- E.g.,
Your system does not necessarily need to use a purpose-built “feature store” for feature retrieval, but the data service needs to handle the following:
- Extremely high scale and performance
- Due to the user-to-item fanout, this service may receive 100-1000x the QPS of your recommendations service, and long-tail latency will heavily impact your overall system performance.
- Fortunately, in most recsys cases, query volume and cost can be significantly reduced at the expense of data freshness by caching item features. Item features (as opposed to user features) are usually well suited to caching because of their lower cardinality and looser freshness requirements. (It’s probably not an issue if your
product_average_review_ratingfeature is a minute or two stale.) Feature caching may be done at multiple levels; e.g., a first-level, in-process cache and a second-level, out-of-process cache like Redis.
- Online-offline parity
- Feature data fetched online must be consistent with the feature data that ranking models were trained with. For example, if the feature
user_site_spend_past_monthis pre-tax during offline training and post-tax during online inference, you may get inaccurate online model predictions.
- Feature data fetched online must be consistent with the feature data that ranking models were trained with. For example, if the feature
- Feature and data engineering capabilities
- Your chosen data service should support serving the kinds of features and data that your models and heuristics require. For example, time-windowed aggregates (e.g.,
product_average_review_rating_past_24horuser_recent_purchase_ids) are a popular and powerful class of features, and your data service should have a scalable approach to building and serving them. - If your data service does not support these classes of features, then contributors will look for escape hatches, which may degrade system complexity, reliability, or performance.
- Your chosen data service should support serving the kinds of features and data that your models and heuristics require. For example, time-windowed aggregates (e.g.,
Filtering
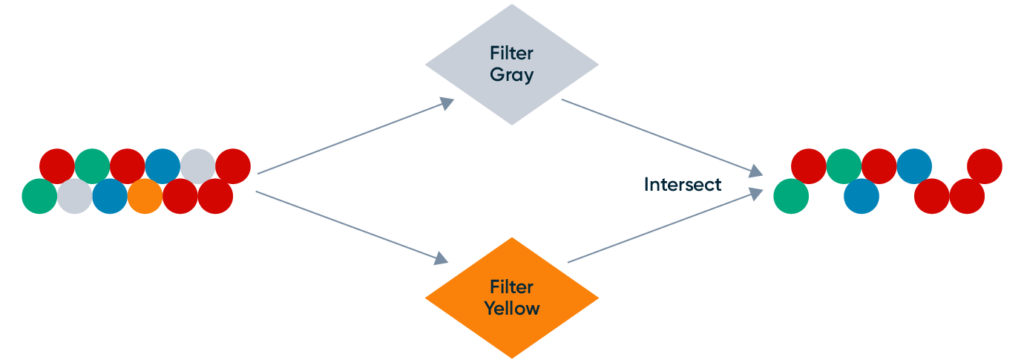
Filtering is the process of removing candidates based on fetched data or model predictions. Filters primarily act as system guardrails for bad user experience. They fall into the following categories:
- Item data filters:
- E.g., an
item_out_of_stock_filterthat filters out-of-stock products.
- E.g., an
- User-Item data filters:
- E.g., a
recently_view_products_filterthat filters out products that the user has viewed in the past day or in the current session.
- E.g., a
- Model-based filters:
- E.g., an
unhelpful_review_filterthat filters out item reviews if a personalized model predicts that the user would rate the review as unhelpful.
- E.g., an
Even though filters act as guardrails and are typically very simple, they themselves may need some guardrails. Here are some recommended practices:
- Filter limits
- Have checks in place to prevent a single filter (or a combination of filters) from filtering out all of the candidates. This is especially important for model-based filters, but even seemingly benign filters, like an
item_out_of_stock_filter, can cause outages if the upstream data service has an outage.
- Have checks in place to prevent a single filter (or a combination of filters) from filtering out all of the candidates. This is especially important for model-based filters, but even seemingly benign filters, like an
- Explainability and monitoring
- Have monitoring and tooling in place to track filters over time and debug changes. Just like model predictions, filter behavior can change based on data drift and will need to be re-tuned.
Model inference
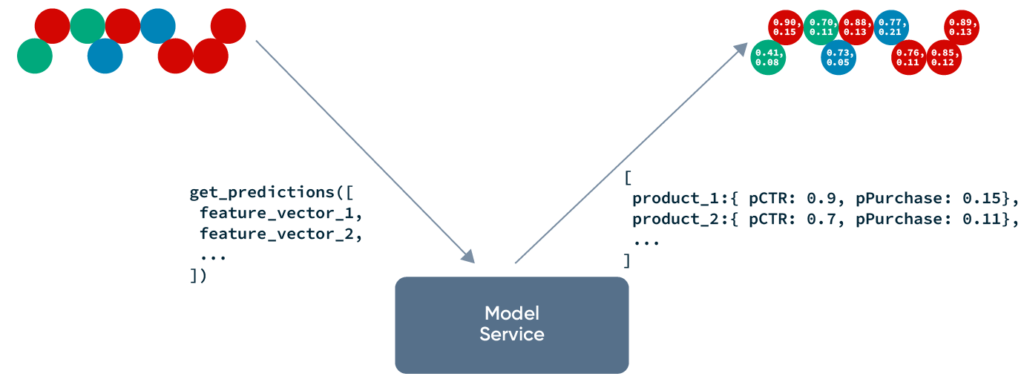
Finally, we get to the “normal” machine learning part of the system: model inference. Like with other ML systems, online model inference boils down to sending feature vectors to a model service to get predictions. Typically these models predict easily measurable downstream events, like Click Through Rate, Probability of a Purchase, Video Watch Time, etc. The exact ML method, model architecture, and feature engineering for these models are huge topics, and fully covering them is outside of the scope of this blog post.
Instead, we will focus on a couple of practical topics that are covered less in data science literature.
- Incorporating fresh features into predictions.
- If you’ve decided to build an online recommendation system, then leveraging fresh features (i.e., features based on user or item events from the past several seconds or minutes) is probably a high priority for you.
- Some ML methods, like collaborative filtering, cannot incorporate fresh features like these into predictions. Other approaches, like hybrid content-collaborative filtering (e.g., LightFM) or pure content-based filtering (e.g., built on XGBoost or a neural net) can take advantage of fresh features. Make sure your Data Science team is thinking in terms of online serving and fresh features when choosing ML methods.
- Model calibration
- Model calibration is a technique used to fit the output distribution of an ML model to an empirical distribution. In other words, your model output can be interpreted as a real-world probability, and the outputs of different model versions are roughly comparable.
- To understand what this means, consider two example uncalibrated Click Through Rate models. Due to different training parameters (e.g., negative label dropout), one model’s predictions vary between 0 and 0.2, and the second model’s predictions vary between 0 and 1. Both models have the same test performance (AUC) because their relative ordering of predictions is the same. However, their scores are not directly comparable. A score of 0.2 means a very high CTR for the first model and a relatively low CTR for the second model.
- If production and experimental models are not calibrated to the same distribution, then downstream systems (e.g., filters and ranking functions) that rely on the model score distributions will need to be re-tuned for every experiment, which quickly becomes unsustainable. Conversely, if all of your model versions are calibrated to the same distribution, then model experiments and launches can be decoupled from changes to the rest of the recommendation system.
- See this talk on the topic.
Pointwise scoring and ranking

“Pointwise” ranking is the process of scoring and ranking items in isolation; i.e., without considering other items in the output. The item pointwise score may be as simple as a single model prediction (e.g., the predicted click through rate) or a combination of multiple predictions and heuristics.
For example, at YouTube, the ranking score is a simple algebraic combination of many different predictions, like predicted “click through rate” and predicted “watch time”, and occasionally some heuristics, like a “small creator boost” to slightly bump scores for smaller channels.
ranking_score =
f(pCTR, pWatchTime, isSmallChannel) =
pCTR ^ X * pWatchTime ^ Y * if(isSmallChannel, Z, 1.0)
Tuning the parameters X, Y, and Z will shift the system’s bias from one objective to another. If your model scores are calibrated, then this ranking function can be tuned separately from model launches. The parameters can even be tuned in a personalized way; e.g., new users may use different ranking function parameters than power users.
Listwise ranking

Have you ever noticed that your YouTube feed rarely has two similar videos next to each other? The reason is that item diversity is a major objective of YouTube’s “listwise” ranking. (The intuition being if a user has scrolled past two “soccer” videos, then it’s probably sub-optimal to recommend another “soccer” video in the third position.)
Listwise ranking is the process of ordering items in the context of other items in the list. ML-based and heuristic-based approaches can both be very effective for listwise optimization—YouTube has successfully used both. A simple heuristic approach that YouTube had success with is to greedily rank items based on their pointwise rank but apply a penalty to items that are too similar to the preceding N items.
If item diversity is an objective of your final output, keep in mind that listwise ranking can only be impactful if there are high-quality, diverse candidates in its input. This means that tuning the upstream system, and in particular candidate generation, to source diverse candidates is critical.
Conclusion
This blog post did not cover major recsys topics like feature engineering, experimentation, and metric selection, but I hope that it gave you some ideas about how to build or improve your system. If you’re interested in learning more, I recommend (pun intended) checking out the recordings for apply(recsys), a free, virtual, half-day event focusing on everything recsys, with guest speakers from major recsys powerhouses such as Slack and ByteDance. You can also reach out to me (jake@tecton.ai) in the Tecton/Feast Slack if you want to chat more about recommendation system design.