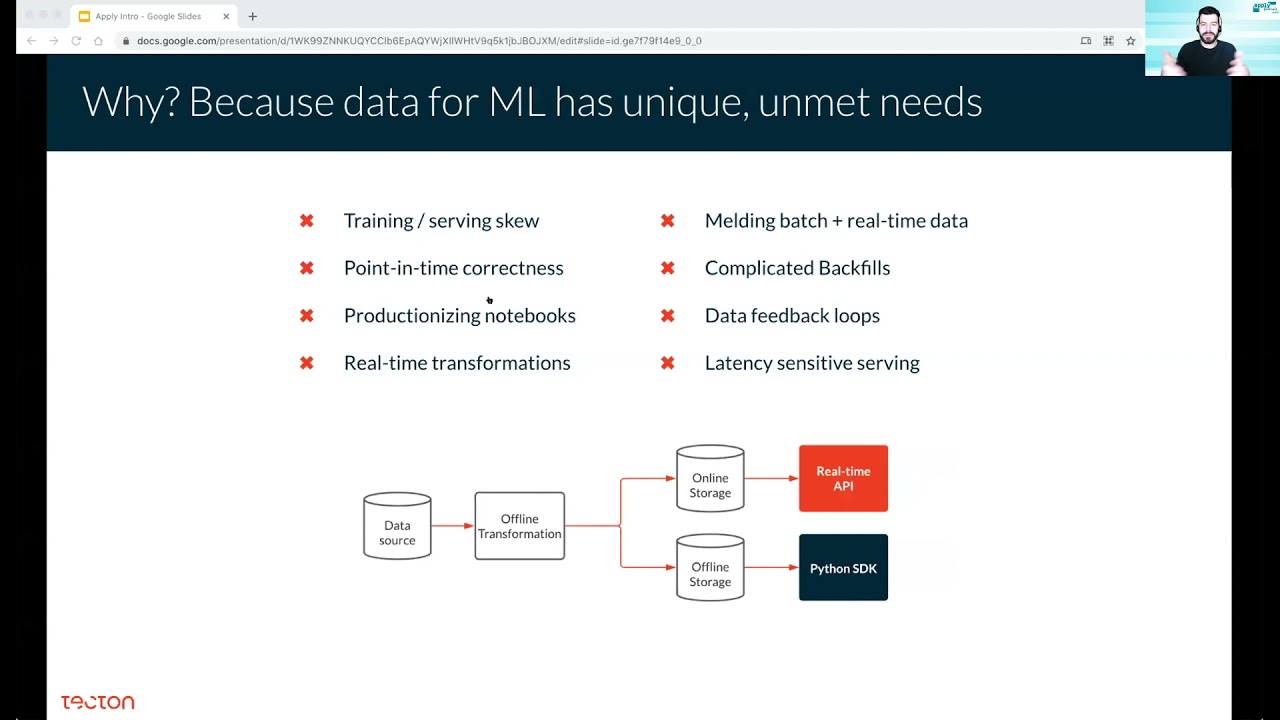
Each of us has a different answer for “why is machine learning so hard.” And how long you have been working on ML will drastically influence your answer. I’ll share what I learned over the past 20 years, implementing everything from scratch …

Streaming is just an implementation detail
Microservices are stream processing; whether you’re using Redis, Kafka, or gRPC, you continuously handle events and manage consistency. And given that these are some of the most challenging problems in databases, you’re probably not doing a very good …

Extending Open Source Feature Stores to Fit Adyen
We walk you through how we adopted Feast at Adyen. We’ll discuss the decisions we made because of infra and tech constraints, and the customizations we added— in particular for our open source project, spark-offline-store, which was adopted into …

Data Observability for Machine Learning Teams
Once models go to production, observability becomes key to ensuring reliable performance over time. But what’s the difference between “ML Observability” and “Data Observability”, and how can ML Engineering teams apply them to maintain model …

Machine Learning Platform for Online Prediction and Continual Learning
This talk breaks down stage-by-stage requirements and challenges for online prediction and fully automated, on-demand continual learning. We’ll also discuss key design decisions a company might face when building or adopting a machine learning …

Managing the Flywheel of ML Data
The ML Engineer’s life has become significantly easier over the past few years, but ML projects are still too tedious and complex. Feature stores have recently emerged as an important product category within the MLOps ecosystem. They solve part of …

[Open Source] Hamilton, a micro framework for creating dataframes, and its application at Stitch Fix
At Stitch Fix, we have 130+ “Full Stack Data Scientists” who, in addition to doing data science work, are also expected to engineer and own data pipelines for their production models. One data science team, the Forecasting, Estimation, and Demand …

The Data Engineering Lifecycle
Data engineering is finally emerging from the shadows as a key driver of data science and analytics. But what is it? This talk covers what modern data engineering is and why it matters. A core concept, the data engineering lifecycle – will be …

A Tour of Features in the Wild and a Modern Solution to Manage Them
Mike will kick off the event and present his views on the different types of features commonly used for Operational ML use cases, and solutions to manage them. Operational ML models rely on several types of features with different characteristics …

What Data Engineers Should Know About Real-Time Analytics
Online Personalization is powered by a real-time feature engineering platform that ingests, processes, and joins millions of events per minute. We present the architecture that manages the real-time feature engineering platform at Personalization. …