
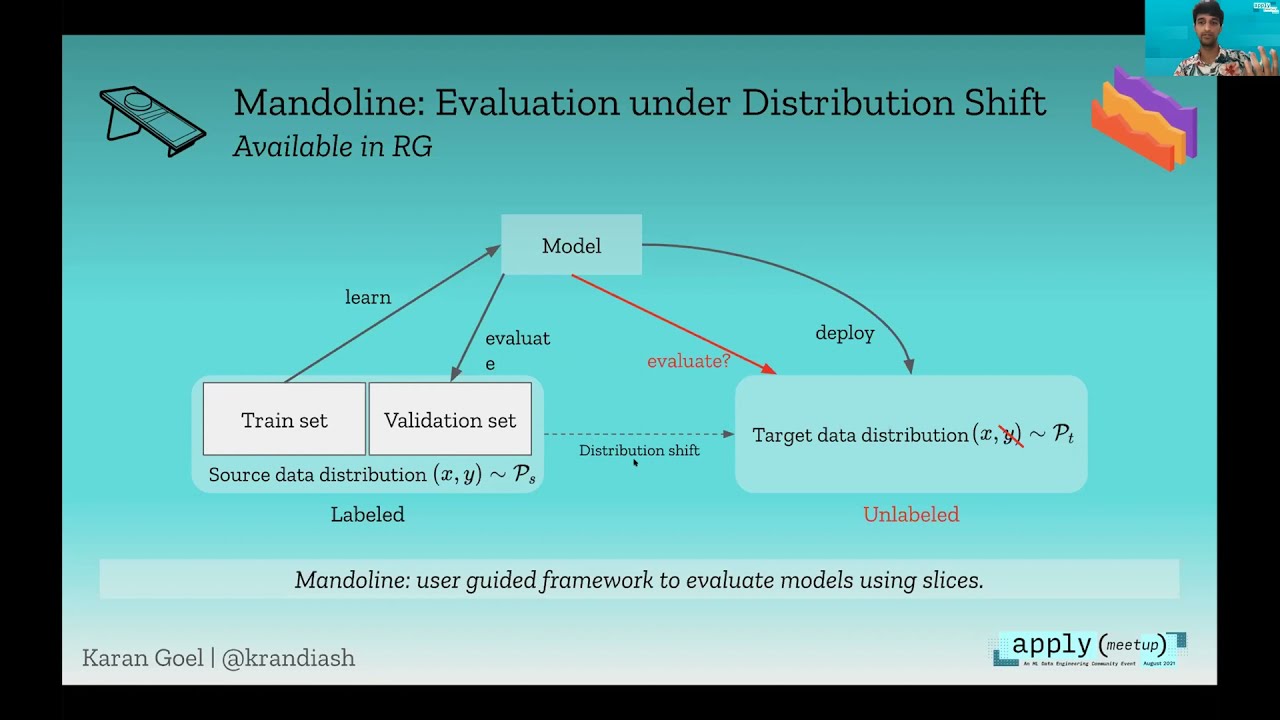
Machine learning systems are now easier to build than ever, but they still don’t perform as well as we would hope on real applications. I’ll explore a simple idea in this talk: if ML systems were more malleable and could be maintained like …

Panel: Building High-Performance ML Teams
As Machine Learning moves to production, ML teams have to evolve into high-performing engineering teams. Data science is still a central role, but no longer sufficient. We now need new functions (e.g. MLOps Engineers) and new processes to bridge the …

Panel: Challenges of Operationalizing ML
Our panel discussion will focus on the main challenges of building and deploying ML applications. We’ll discuss common pitfalls, development best practices, and the latest trends in tooling to effectively operationalize ML

The Only Truly Hard Problem in MLOps
MLOps solutions are often presented as addressing particularly challenging problems. This is mostly untrue. The majority of the problems solved by MLOps solutions have their origins in pre-ML data processing systems and are well addressed by the …

What is the MLOps Community?
The MLOps community started in March 2020 as a place for engineers and practitioners to get together and share their knowledge about operationalizing ML. Since its inception, it has morphed into a community of more than 3k members with an array of …

Supercharging our Data Scientists’ Productivity at Netflix
Netflix’s unique culture affords its data scientists an extraordinary amount of freedom. They are expected to build, deploy, and operate large machine learning workflows autonomously with only limited experience in systems or data engineering. …