What is online / offline skew in machine learning?



Real-time machine learning has quickly become an integral part of many modern software applications. The ability to leverage real-time data during model inference can have a dramatic improvement on model quality for use cases like fraud detection, search, and recommendations.
However, making the jump from batch to real-time machine learning systems creates a set of unique challenges that can frequently prevent ML teams from being successful. In this post, I’ll cover one of the primary challenges in real-time machine learning: the online / offline skew.
What is online / offline skew in machine learning?
One of the unique properties of a real-time machine learning system is that it operates across two different environments: online and offline. The online environment is where real-time predictions are made and leveraged in application logic. For example, when a user swipes their credit card at a register, an ML system may predict in real time whether or not that transaction is fraudulent. The application can then decide whether to accept or decline the transaction. The model running in the online environment needs access to real-time feature data such as the user’s recent purchase history in order to make predictions.
In contrast, training a model most commonly happens in the offline environment, where historical datasets are stored in a data lake or warehouse and processed using offline compute (e.g., Python, Spark, Snowflake, etc.). During training time, the model needs access to historical features values for labeled training events. In the credit card example above, these events would be user transactions that have been labeled as fraudulent or non-fraudulent.
This creates one of the primary challenges in real-time ML: If the features used to train the model are not the same as the features used for online model inference then model quality will suffer. Intuitively, this makes sense because a model can’t accurately predict an outcome using information that is different from what it trained on. This issue is commonly referred to as “online / offline skew.”
Sources of online / offline skew
There are three primary sources of online / offline skew in real-time machine learning systems:
1. The online and offline feature logic is different.
When building a real-time ML system, it’s common for teams to first try engineering different online and offline pipelines. A data scientist will compute features to train a model using whatever offline data sources and compute they have available and then iterate until they are happy with model quality.
At this point, they hand off their trained model and feature logic to an engineer who is responsible for productionizing that model. The engineer then needs to re-implement the equivalent feature logic online, using online data sources and compute. This approach introduces significant risk that the features being computed online and offline will not be semantically equivalent. This could be caused either by natural user error or by different online and offline constraints. Because of the high error rates, this approach is commonly considered an anti-pattern in modern real-time ML systems.
2. The offline features aren’t historically accurate.
Naturally, feature values in a real-time ML system change over time. A user’s transaction count in the last 5 days is likely different as of today than it was as of last month. In order to train an accurate model, the feature values we compute for a given training event (e.g., a past transaction) need to represent what the values of those features were at that point in time. This means that they should identically match the values that would’ve been retrieved online at that time. This problem is explored in more detail in our blog post on time travel.
Creating a historically accurate training dataset can be quite tricky since the user needs to write a complex point-in-time feature retrieval query that adequately considers how and when features are being served online. If done improperly, model quality will suffer.
3. The distribution of online feature values has changed.
Not only do feature values for a given entity (e.g., a user or merchant) change over time, but so does the overall distribution of values. The real world is constantly changing and, as a result, so will our features. For example, a market recession may cause a change in user purchasing behavior, which in turn causes a change in the distribution of feature values for user transactions. If a model was trained on data in the past that no longer adequately represents the current state of the world, then online model quality can suffer.
Reducing online / offline skew
Reducing online / offline skew should be a priority in any real-time machine learning system to maintain high model accuracy. However, completely eliminating skew might not be the best goal because it can lead to diminishing returns on model quality in comparison to the complexity introduced into the system.
Feature stores and feature platforms have emerged as primary components in a modern ML stack and serve as key solutions for reducing skew. To be effective, these solutions must address the various sources of skew without adding excessive complexity for the end user.
In the following sections, we will outline approaches for reducing skew in each of the scenarios mentioned above.
1. The online and offline feature logic is different.
The clearest solution for preventing skew from different online and offline feature pipelines is to only use one pipeline for computing a given set of features. If the features depend on data from an offline batch source (e.g., Hive, Snowflake, etc.) and have less strict freshness requirements, then a batch pipeline can compute features on a schedule and publish them to an online and offline store. The online store will contain the latest feature values for online inference and the offline store will contain the historical values for offline training.

On the other hand, if the features need to be computed in real time (either asynchronously against streaming data or synchronously at the time of the prediction request), then those features values can be logged offline for later training.
However, waiting to log features for offline training can slow down experimentation. Users often want to backfill a new value against historical data right away and test it in a training data set. This requires a different batch pipeline.
In this scenario, the best thing to do is to ensure that the same transformation logic is used in both pipelines but against different data sources. For example, we can run a batch Spark pipeline against an offline historical stream source using the same Spark transformation logic that we will run against the online stream source.
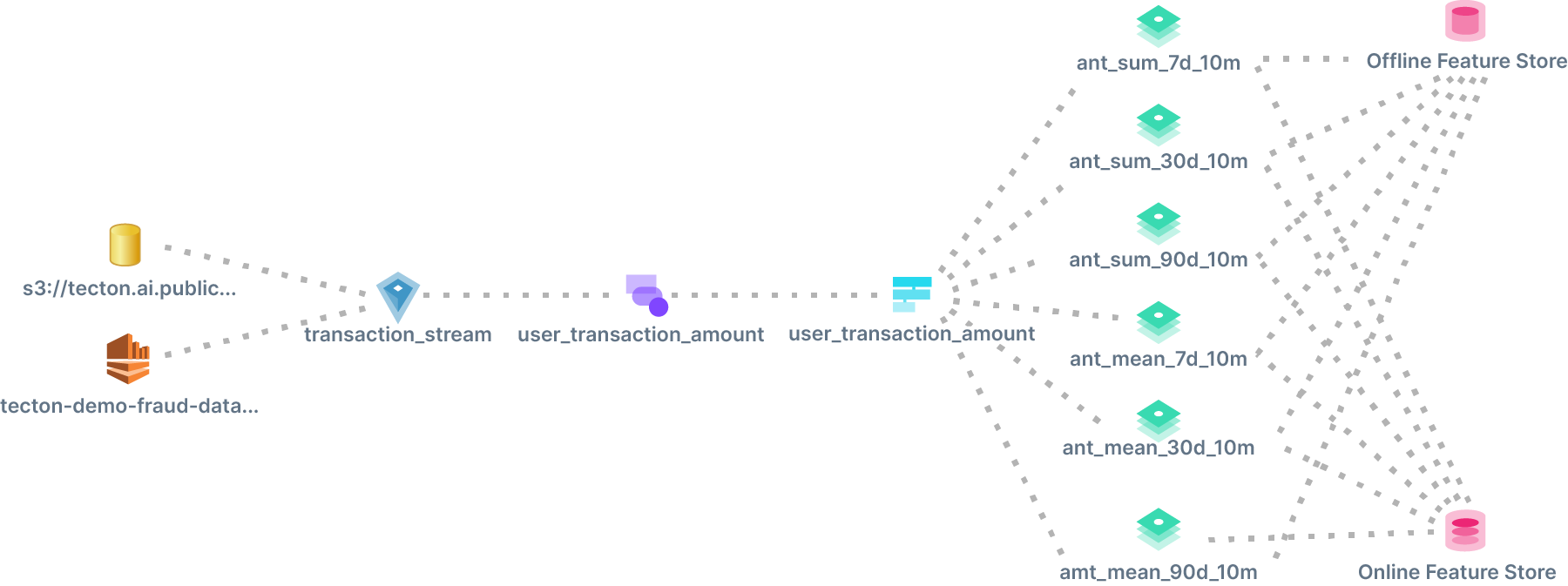
This approach will help ensure that the features being calculated online and offline are the same.
2. The offline features aren’t historically accurate.
Addressing this problem is best tackled using a feature store solution that handles point-in-time training data generation. When incorporating features for a specific training event, the system should automatically choose the latest feature timestamp relative to the event time.
However, this solution is not foolproof because it depends on user-defined feature timestamps without considering when these features would be accessible online. A more comprehensive solution should take the following into account:
- Materialization schedule: The system should assess when the data is published to the online store. For example, if a daily batch pipeline updates the online store, the system should return the feature value that was available in the store at the time of the request, not the most recent one.
- Backfill range: When retrieving features for training, the system should consider the backfill period and disregard earlier feature data that wouldn’t have been online.
- Time-to-Live (TTL): If your feature store solution has a Time-to-Live setting for features in the online store, it should also be considered when looking for historical feature values. Values outside the online TTL range should be filtered out.
Taking these factors into account when fetching historically accurate feature values is essential for reducing skew.
3. The distribution of online feature values has changed.
This issue could be caused either by broken pipelines or by changes in real-world patterns. In both cases, the best option for reducing skew is via data quality monitoring. We want a system that can:
- Compare distributions of online pipelines to offline backfill pipelines
- Compare distributions of feature data over time
- Track when training data was generated and compare distributions of online feature data to the data used to train the last model
Ideally, the system should provide validations and alerts out-of-the-box with zero setup while also allowing users to specify their own alerting rules and thresholds.
Based on the alerts, users can then either:
- Investigate and fix a broken data pipeline
- Retrain a model to use more recent real-world data
Key takeaways
As you can see, reducing online / offline skew can be a nuanced and tricky problem to solve, but if unaddressed it can keep real-time machine learning systems from delivering their intended business value.
A well-designed feature platform can help your team reduce skew without needing to think through and address these nuances yourself. This can help significantly reduce the development and maintenance burden when making the leap to real-time machine learning.
If your team is interested in learning how Tecton can help address these issues and help prevent online / offline skew, reach out to us today to schedule a 1:1 demo.


