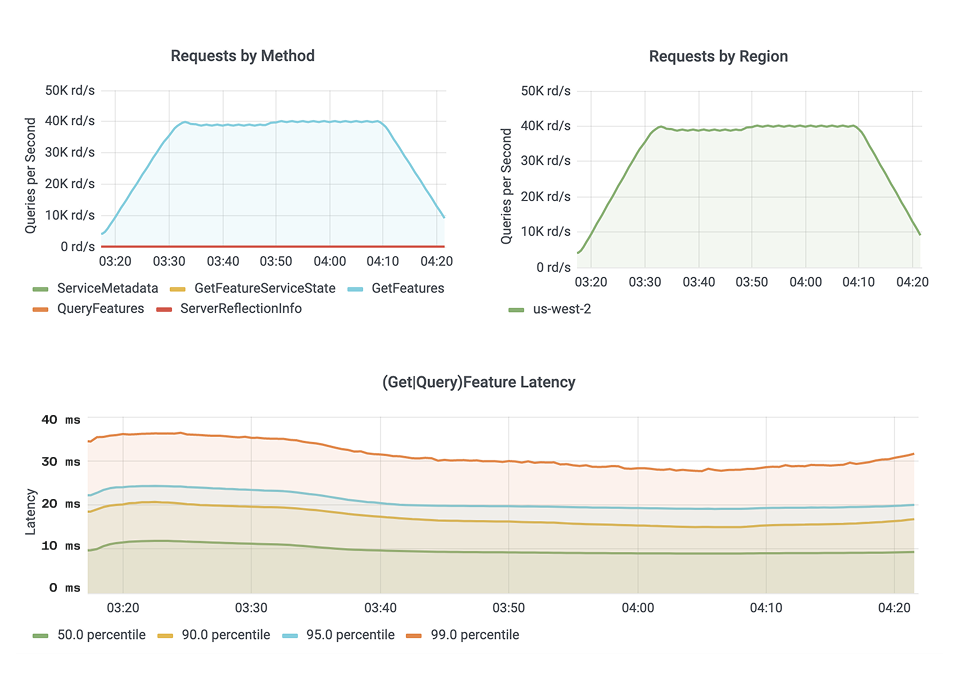
Tecton’s Retrieval System uses advanced parallelization techniques for high-throughput feature and embedding serving. ML applications can access features simultaneously, maintaining rapid response times under heavy loads. Tecton’s infrastructure delivers more than 150k requests per second under 5ms.
Compute features on-the-fly with real-time processing
Unlock the potential of real-time features with Tecton’s on-the-fly compute capabilities. Tecton performs complex calculations and transformations at request time, incorporating up-to-date information into ML models. This supports dynamic decision-making and keeps AI applications responsive to rapid changes, critical for time-sensitive use cases.
Experience predictable low latency
Optimize your AI/ML applications for production environments with Tecton’s low-latency retrieval system. This multi-faceted system ensures that your AI models can make split-second decisions based on the latest data, crucial for time-sensitive applications. Our architecture combines:
Pre-computed features in a fast online store
Efficient read-time aggregations
Intelligent caching to minimize response times
Access features effortlessly through a REST API
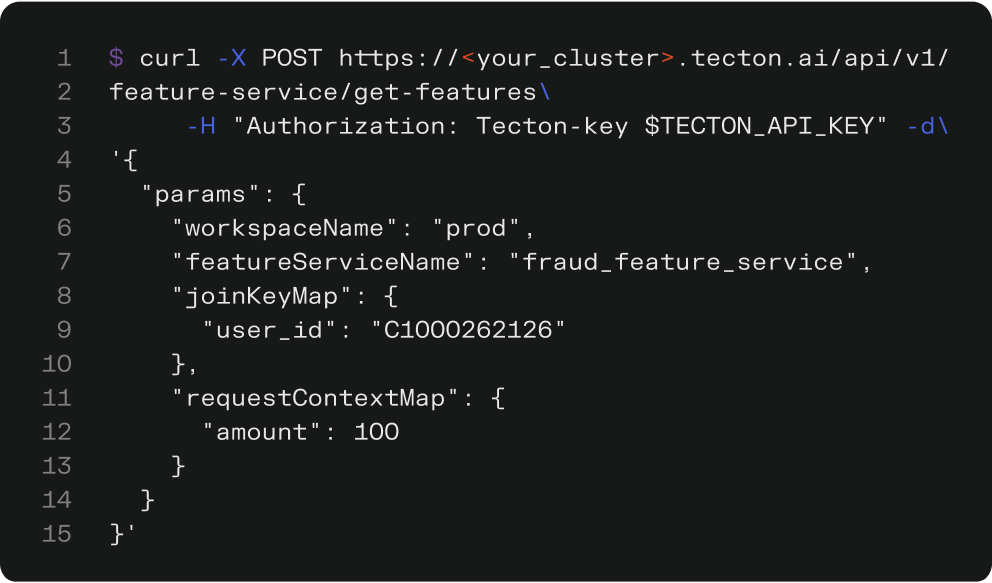
Integrate Tecton’s powerful retrieval capabilities into your applications with ease using our low-latency REST API. This standardized interface provides consistent access to all your AI context, regardless of origin—stream processing, batch computation, or real-time calculations. Simplify application integration overhead with a single, reliable API for all your feature serving needs.
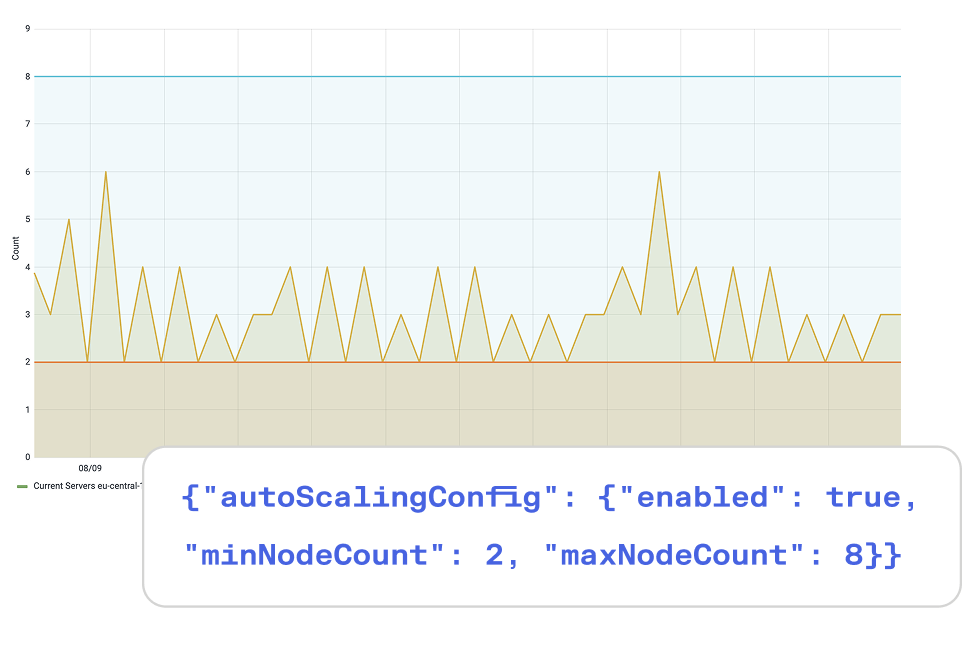
Adapt to changing demands with Tecton’s built-in autoscaling capabilities. Tecton automatically adjusts resources to match your current workload, ensuring optimal performance during traffic spikes and cost efficiency during quieter periods. Intelligent scaling removes the burden of capacity planning, allowing you to focus on building and improving your AI/ML models.
Interested in trying Tecton? Leave us your information below and we’ll be in touch.
Unfortunately, Tecton does not currently support these clouds. We’ll make sure to let you know when this changes!
However, we are currently looking to interview members of the machine learning community to learn more about current trends.
If you’d like to participate, please book a 30-min slot with us here and we’ll send you a $50 amazon gift card in appreciation for your time after the interview.
Interested in trying Tecton? Leave us your information below and we’ll be in touch.
Unfortunately, Tecton does not currently support these clouds. We’ll make sure to let you know when this changes!
However, we are currently looking to interview members of the machine learning community to learn more about current trends.
If you’d like to participate, please book a 30-min slot with us here and we’ll send you a $50 amazon gift card in appreciation for your time after the interview.