Create Amazing Customer Experiences With LLMs & Real-Time ML Features


We know that a customer’s satisfaction level has an immense influence on a buying decision—and having real-time insight on your customers’ sentiment towards your product or business at scale can be invaluable.
By connecting large language models (LLMs) to a centralized feature platform, you can extract powerful insights from customer events as they unfold in real time and make those insights available to downstream models or business processes.
Consider customer sentiment in a support chat, for example. It would be useful to understand how the sentiment of that customer is evolving from message to message, as well as understand the customer’s historic sentiment over recent time windows. If you knew a customer’s mood was declining over time, you might intervene and save that relationship. If the mood was improving, you could use that insight to identify and reinforce positive behaviors from your support team.
But how can we extract those insights from customer chats without spending months developing a chat sentiment analyzer and standing up our own feature serving infrastructure? In this post, I’ll cover how you can easily fit LLMs into production pipelines and empower downstream systems to take action in real time to help increase customer satisfaction and drive increased revenue.
The benefits of large language models
LLMs excel at subjective tasks like sentiment analysis and natural language understanding. With a simple prompt, we can ask LLMs like GPT or PaLM to extract features from a chat log. If we integrate an LLM inference into a feature pipeline that populates an online and offline store, we can make those features available for both real-time analysis and batch training for additional ML models.
Recipe ingredients for example LLM feature pipeline
- Tecton Stream Feature View
- Large language model (like GPT or PaLM)
- Streaming chat data source (Tecton PushSource)
In our demo, we stream chat messages into Tecton’s Ingest API. Tecton supports Kinesis, Pub/Sub, and Kafka streams, but the Ingest API makes it easy to stream data into the feature platform via JSON without setting up additional streaming infrastructure.
Next, we’ll include a sentiment function that instructs an LLM to analyze the sentiment of a message and return the results in JSON. You could have this code run prior to your feature platform (and simply load the inferences as a feature table), or you could incorporate the code directly in a feature pipeline without much adjustment. I prefer the latter, as this allows the feature platform to manage the workload (one less thing for the Data Engineering team to worry about).
It is useful to prompt the LLM to provide us with an easily queryable, JSON response. Here is the template we’ll send to GPT for inference:
'''For the message below, classify sentiment as
["Very Upset", "Upset", "Neutral", "Happy", "Very Happy"].
If the message includes constructive product feedback, set "contains_feedback" to 1, otherwise set it to 0.
Return JSON ONLY. No other text outside the JSON. JSON format:
{"message_sentiment": ,
"contains_feedback": <1 or 0>}
Here is the message to classify: ''' + message_string We’ll send this prompt to GPT via an API call in one of our stream feature views. GPT will send back JSON, and the extracted values will land in our online and offline stores. I also will use a helper method that translates the GPT inference into an integer score from -2 to 2. This makes it easy to calculate numerical aggregations with historic sentiment values (min, max, average, standard deviation, etc.).
Once we construct our feature view with our stream of chat events, Tecton will handle the rest (including backfills for historic chat logs). With every new message, Tecton communicates with GPT to get an inference, aggregates the resulting features over different time windows, and updates the online and offline feature stores.
Here’s an architecture diagram of our example LLM-powered feature pipeline:
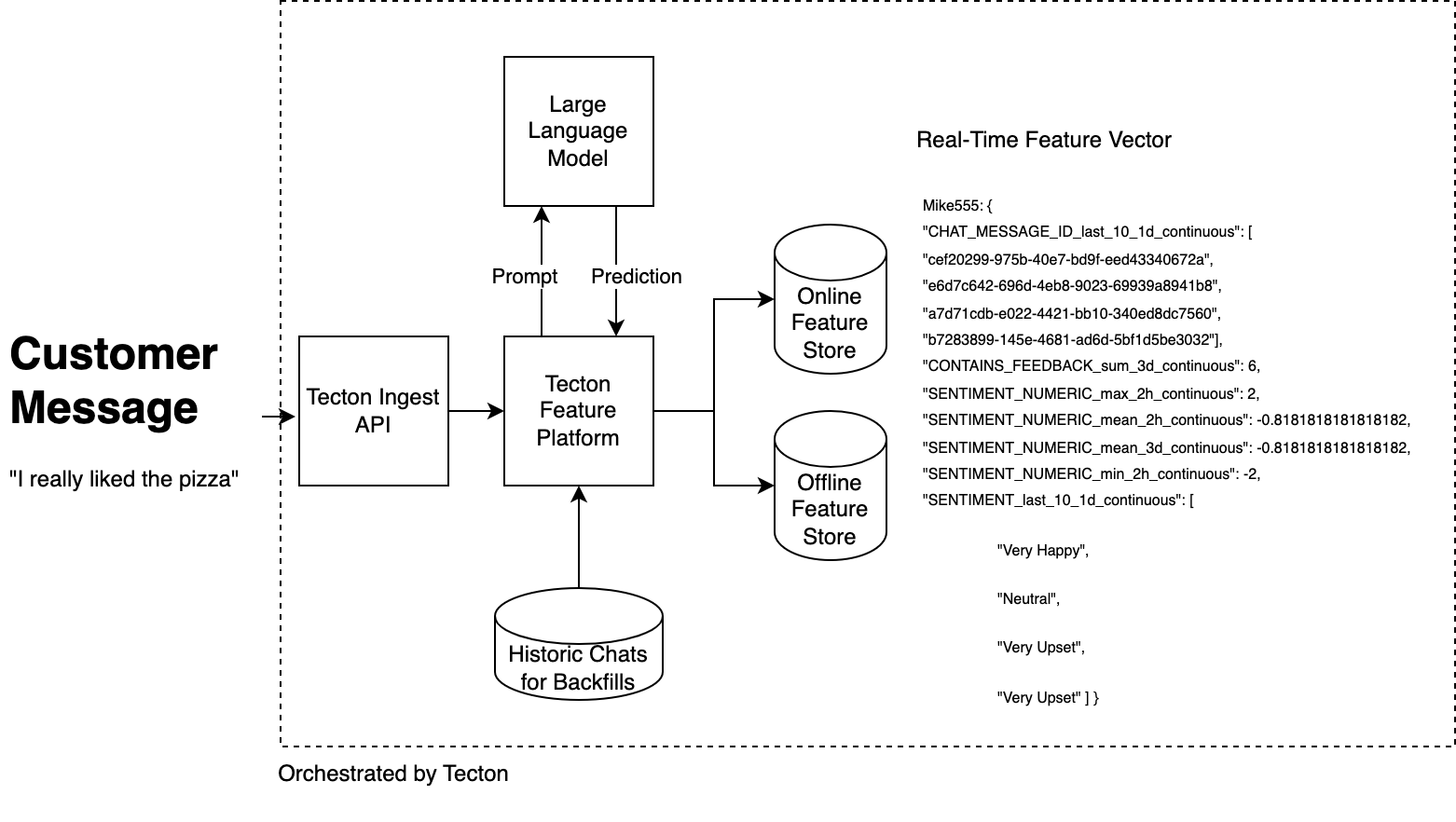
My example features describe the quantity of feedback each customer has given in the last 3 days, and gives us an understanding of the customer’s most recent interactions with our business. I can refer to historical inferences and take preventative action if I see declining sentiment.
In the past, teams would have had to build a custom sentiment model, move inferences into a feature store, and then deploy an endpoint around those features for downstream consumption. Now it’s possible to build this end-to-end pipeline in less than a day by using an LLM with Tecton.
Translating real-time features into business value
How do we translate these real-time features into value for our business? As I mentioned earlier, we know that a customer’s satisfaction level heavily influences their buying decision and that it’s worthwhile to have real-time insight on your customers’ sentiment towards your product or business at scale. Downstream models can act on these insights as early as possible (e.g., rather than waiting days to reach out to an upset customer, you can follow up in seconds).
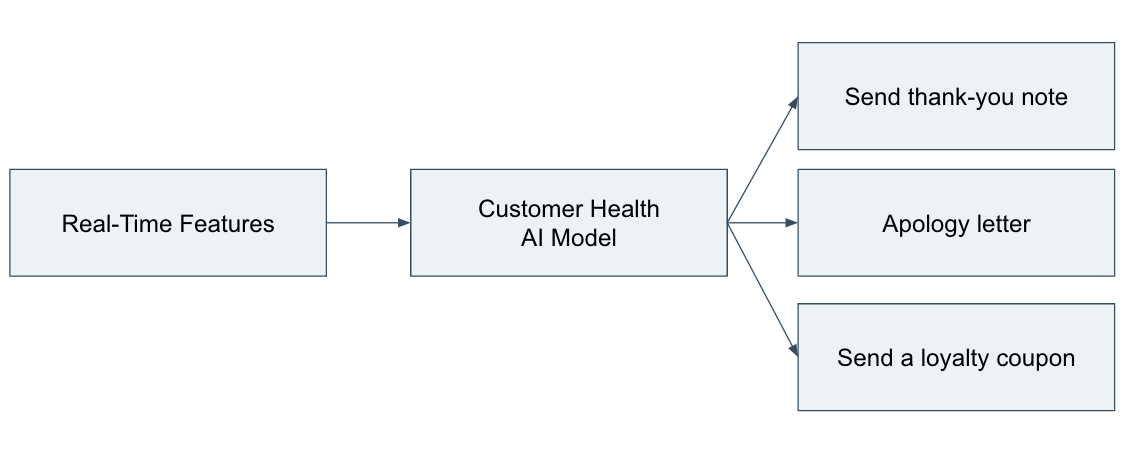
LLMs are incredibly powerful, generalizable AI models. With the right prompts, we can easily fit LLMs into production feature pipelines and empower downstream systems to take action in real time. Teams can also send real-time features from Tecton directly to LLMs, allowing LLMs to make decisions with real-time context. More advanced workflows could even host multiple LLMs acting as data producers and consumers around a centralized, real-time feature store.
Interested in learning more about how LLMs and Tecton can help your team build end-to-end ML feature pipelines faster? Contact us for a personalized demo.


