Deploying Real-Time Machine Learning Applications with Databricks



We are thrilled to announce our partnership with Databricks, the Data and AI Company and pioneer of the data lakehouse paradigm, to help organizations build and automate their machine learning feature pipelines from prototype to production.
Available to all Databricks customers on AWS, Tecton acts as the central source of truth for machine learning (ML) features. By automatically orchestrating, managing, and maintaining the data pipelines that generate features, the integration enables data engineers and data scientists to build production-ready feature pipelines across batch, streaming, and request-time data, and serve them at scale across teams, systems, and models, with only a few lines of code.
Databricks and Tecton
Sitting on top of Databricks Delta Lake and leveraging the elastic scalability and power of the Databricks processing engine, Tecton’s feature platform allows users to define features as code using Python and SQL, track and share features with a version-control repository, and process these features using real-time and streaming data from a myriad of data sources.
Tecton then automates and orchestrates production-grade ML data pipelines that materialize feature values in a centralized repository. Under the hood, Tecton abstracts and automates the complex process that transforms raw data from batch or real-time sources into features used to train ML models and feed predictive applications in production.
This process ensures data scientists can train models using historical features without worrying about point-in-time correctness or consistency with model serving. To run models in production, data engineers can rest assured that Tecton will serve only the latest features while maintaining high scale, high freshness, and low latency.
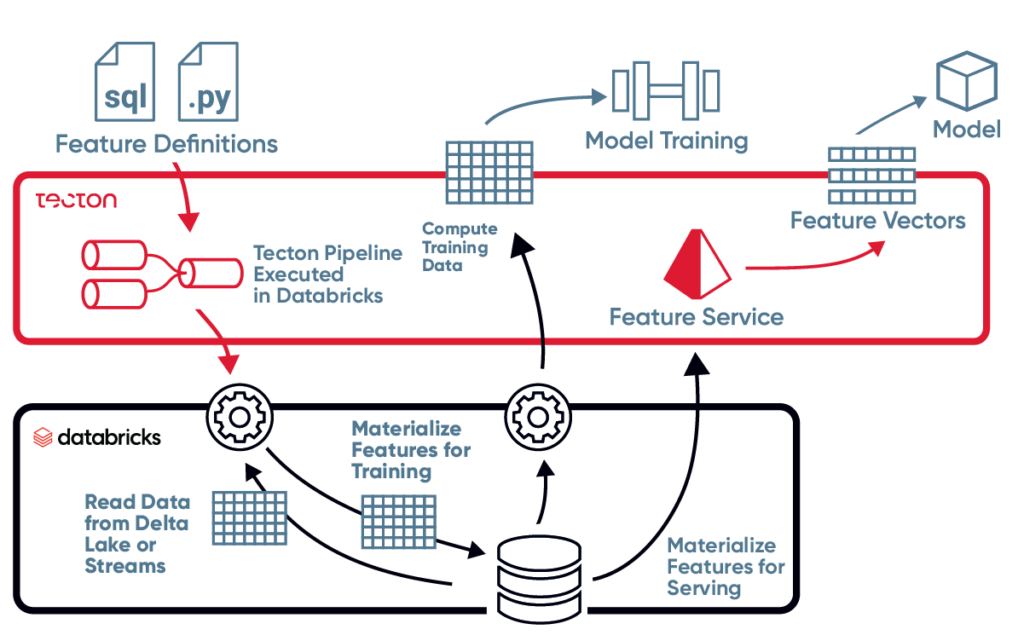
Managing the ML feature lifecycle with Tecton and Databricks not only ensures that feature materializations are always consistent, offline for training and online for inference, but that they are also stored in a searchable repository for easy sharing and re-use across teams and use cases. The ability to explore, share, and serve features for offline training or online inference without worrying about extensive engineering support drastically shortens time-to-production all the while improving model performance, accuracy, and outcome.
Get Started
To learn more about how you can use Tecton with Databricks, check out this Databricks’ guest blog by David Hershey, Senior Solutions Architect at Tecton, and sign-up for a free trial:


