Drift-Aware ML Systems




Predictive models are used to detect some pretty important stuff, like whether a credit card transaction is legitimate or not. But your models are only as good as the data you’re feeding them with – and your data can change over time, or even be broken upstream of your model. How can you ensure that the online feature values used during inference remain consistent with the features that were used to train your models?
To explore this idea, let’s build a straightforward ML application designed to evaluate a credit card transaction for fraud risk, and then look at how we can guarantee input accuracy over time using a drift detection technique.
A transaction app with built-in fraud detection
To keep things simple, let’s imagine a trivial payment app, built in python in a notebook environment, that can run a credit card transaction.
Let’s assume that our imaginary app exists, is wired up to a payment API like Stripe, etc. At a specific point in the app flow, we’ll have a transaction ID, a user ID, and an amount of the potential transaction:
current_transaction = {
"transaction_id": "57c9e62fb54b692e78377ab54e9d7387",
"user_id": "user_1939957235",
"timestamp": "2025-04-08 10:57:34+00:00"
"amount": 500.00
}
We want to add a prediction step before we run the transaction; something that looks about like this:
# inference
prediction = {"predicted_fraud": model.predict(features).astype(float)[0]}We’ll need a couple things to make this deceptively simple line of python code actually work: obviously, we’ll need a model; we’ll also need training data, and we’ll need a way to serve feature values to that model at inference time. Sounds like a job for a feature store!
For transaction fraud detection, we would expect to use historical data to train our model – something like this:
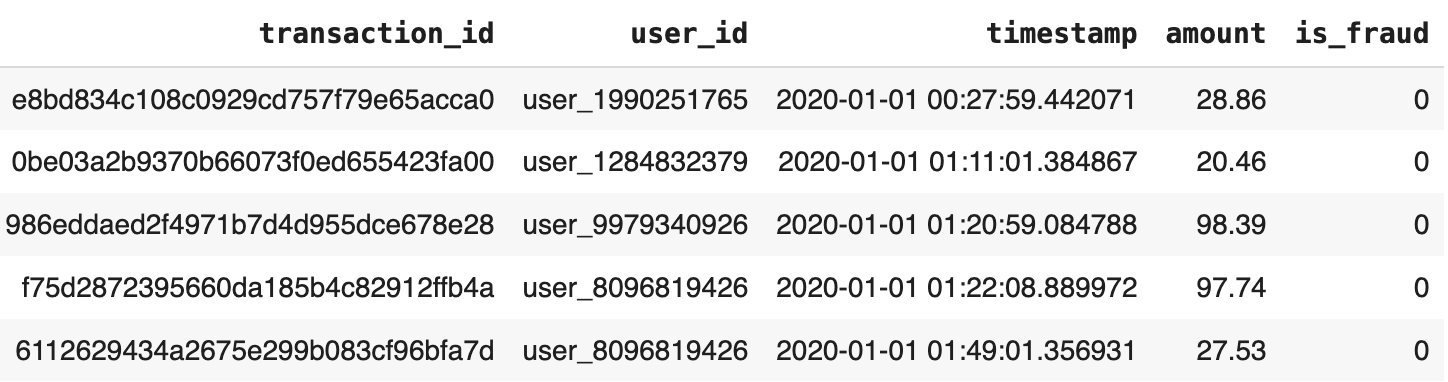
We can use this labeled, historical event data—in this fraud detection use case, the label “is_fraud” indicates whether the transaction was fraudulent—as a training data set. But just having a training dataset isn’t nearly enough. We need to set up a feature data pipeline to compute and serve this data to our model, since we’ll want to serve fresh features at inference time and update historical data as new events come in.
This is where our feature store comes into play. Tecton lets us define feature views that convert raw data from streaming, batch, and real-time sources into features that support both model training and online serving – and it will ensure that the same transforms are used in both cases. In fact, Tecton is going to create and manage all our data pipelines for us – so we can focus on selecting the most useful features.
We’ll begin by creating a streaming feature view that captures recent account activity patterns.
In Tecton, features are defined as Python code modules, typically developed in interactive notebooks. When this code is deployed to Tecton, it automatically generates data pipelines that continuously update feature values for training and serving purposes, ensuring models are always ready for training, retraining, or production deployment.
Fresh Features from Streaming Events
This streaming feature example for fraud detection computes recent spending totals along with 30-day rolling averages and standard deviations:
@stream_feature_view(
source=transactions_stream,
entities=[user],
mode="pandas",
timestamp_field="timestamp",
features = [
Aggregate( name="sum_amount_10min", function="sum",
input_column=Field("amount", Float64),
time_window=timedelta(minutes=10)),
Aggregate( name="sum_amount_last_24h",function="sum",
input_column=Field("amount", Float64),
time_window=timedelta(hours=24)),
Aggregate( name = "amount_mean_30d",function="mean",
input_column=Field("amount", Float64),
time_window=timedelta(days=30)),
Aggregate( name = "amount_count_30d",function="count",
input_column=Field("amount", Float64),
time_window=timedelta(days=30)),
Aggregate( name = "amount_stddev_30d",function="stddev_samp",
input_column=Field("amount", Float64),
time_window=timedelta(days=30)),
],
)
def user_txn_recent_activity(transactions_stream):
return transactions_stream[["user_id", "timestamp", "amount"]]Features Calculated in Real-time
We’ll need to detect outliers for incoming transactions, so we’ll implement a real-time feature view that computes a z-score, using the fresh amount and the statistics for last 30 days:
request_ds = RequestSource(
name = "request_ds",
schema = [Field("amount", Float64)]
)
request_time_features = RealtimeFeatureView(
name="request_time_features",
sources=[request_ds, user_txn_recent_activity],
features = [
Calculation(
name="amount_zscore_30d",
expr="""
( request_ds.amount -
user_txn_recent_activity.amount_mean_30d
)
/ user_txn_recent_activity.amount_stddev_30d
""",
),
],
)
Finally, we’ll combine both feature views into a feature service that delivers point-in-time correct training data and provides live features to the fraud detection model in production:
from tecton import FeatureService
fraud_detection_feature_service = FeatureService(
name="fraud_detection_feature_service",
features = [ user_txn_recent_activity, request_time_features]
)
tecton apply
The ‘tecton apply’ command deploys the data sources, feature views, and feature services defined in the Python modules to the platform and launches the data processing jobs that populate the offline training data and online serving stores:
> tecton apply
Using workspace "fraud_detection" on cluster https://fintech.tecton.ai
✅ Imported 1 Python module from the feature repository
✅ Imported 1 Python module from the feature repository
⚠️ Running Tests: No tests found.
✅ Collecting local feature declarations
✅ Performing server-side feature validation: Initializing.
↓↓↓↓↓↓↓↓↓↓↓↓ Plan Start ↓↓↓↓↓↓↓↓↓↓
+ Create Stream Data Source
name: transactions_stream
+ Create Entity
name: user
+ Create Transformation
name: user_txn_recent_activity
+ Create Stream Feature View
name: user_txn_recent_activity
materialization: 11 backfills, 1 recurring batch job
> backfill: 10 Backfill jobs from 2023-12-02 00:00:00 UTC to 2025-03-25 00:00:00 UTC writing to the Offline Store
1 Backfill job from 2025-03-25 00:00:00 UTC to 2025-04-24 00:00:00 UTC writing to both the Online and Offline Store
> incremental: 1 Recurring Batch job scheduled every 1 day writing to both the Online and Offline Store
+ Create Realtime (On-Demand) Feature View
name: request_time_features
+ Create Feature Service
name: fraud_detection_feature_serviceGreat! Now we can query the feature service to get a training dataset (and at inference time as well).
Logging Training Data
Data scientists use the get_features_for_events method from feature services to pull time-aligned training data directly from their notebooks. They can choose to use local compute for small datasets or distributed systems like Spark and EMR for handling larger training data.
By using a dataframe of training events as input, get_features_for_events augments each record with historically accurate feature values. Using time-aligned feature values in training data is crucial for preventing initial model drift when models reach production.
training_data = fraud_detection_feature_service.get_features_for_events(training_events)
Here’s a sample of the resulting training_data:
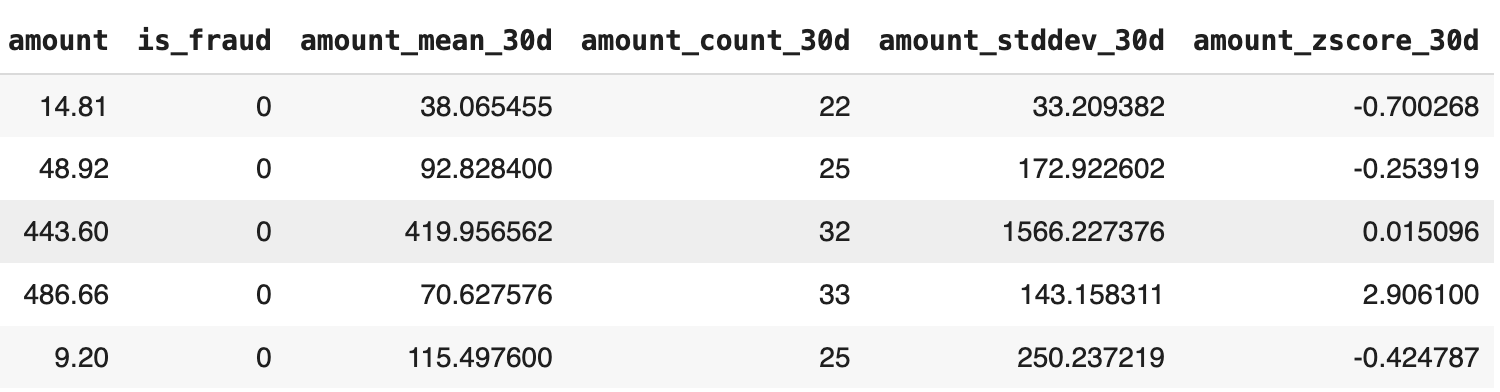
Why do we need to monitor our feature values for drift?
Feature drift happens when the statistical distribution of the inputs your model relies on shifts over time, causing the model’s assumptions and decision boundaries to become invalid. If it’s not addressed, you get degraded accuracy, hidden failure modes, and potential fairness issues as different subpopulations drift unequally. But it’s not easy to spot by hand – detecting drift requires continuous monitoring of feature and output distributions, alerting on significant changes, and maintaining automated retraining pipelines to keep the model aligned with current data.
A feature store like Tecton ensures consistency between offline training and online serving by using unified feature definitions, eliminating the risk of training/serving misalignment. The feature store manages data pipelines and maintains fresh, inference-ready features continuously – and it’s the perfect place to check on feature value drift.
However, although feature platforms typically provide basic data quality metrics and validation capabilities, they generally lack comprehensive model performance monitoring and feature drift detection functionality.
For machine learning applications, Arize delivers a comprehensive monitoring solution that tracks model performance in production environments. It monitors data quality, performance metrics, and drift across both model outputs and input features. Arize functions as an early warning system that completes the ML lifecycle feedback loop, enabling continuous model enhancement.
Combining feature platforms with Arize’s monitoring capabilities is straightforward. Since feature platforms generate training datasets and serve features for online inference, the same feature values and predictions can be forwarded to Arize for comprehensive logging and monitoring analysis.
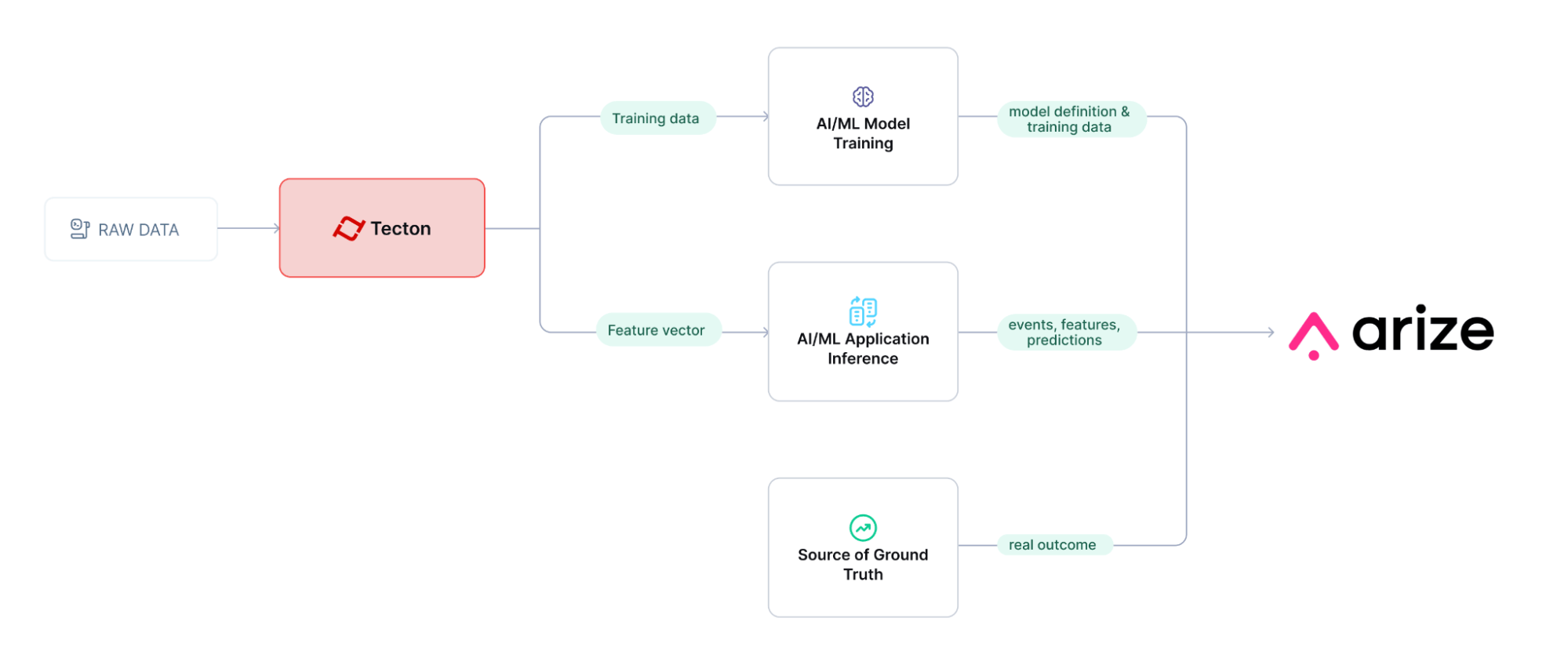
During model development, training data can be uploaded to Arize to establish a training baseline that defines expected distributions for both features and predictions. When a model generates predictions using Tecton features, Arize logs the event identifier, prediction results, and input features. And, once events are labeled with ground truth, this data is also uploaded to Arize. This process enables Arize to monitor feature and model drift by comparing current values against the established training baseline.
There are three things we want out of our feature drift detection:
Model Performance:
Models are generally built using historical datasets. When the characteristics of input features undergo substantial changes, the model may not perform as effectively on new data.
Early Warning System:
Feature drift detection serves as an early warning system. Teams can receive alerts about changes in data distributions and implement preventive actions before observable declines in predictive performance occur.
Data Integrity and Reliability:
Continuous feature drift monitoring measures consistency between incoming data and training data. This becomes essential in regulated sectors or high-stakes environments where critical decisions depend on reliable predictions.
Model Registration and Baselining in Arize
We’ll want to log the model and training data with Arize to create the baseline for the model training data and its outputs.
Arize code embeds seamlessly into your model training workflow and executes whenever your final training process runs. This could be within interactive notebooks during development or as part of automated training pipelines that trigger when models are prepared for production deployment.
First we define the model schema:
# define schema of the training and prediction data
arize_schema = Schema(
actual_label_column_name="is_fraud",
prediction_label_column_name="predicted_fraud",
feature_column_names=input_columns, # model inputs
prediction_id_column_name="transaction_id",
timestamp_column_name="timestamp",
tag_column_names=["user_id"]
)
We then establish a baseline dataset in Arize for this model to provide a reference point against which new feature values can be assessed for drift.
The trained model generates predictions on the baseline training data, and we combine the ground truth (fraud_outcome) with the model’s predictions (predicted_fraud):
input_data = training_data.drop(['transaction_id', 'user_id',
'timestamp', 'amount'], axis=1)
input_data = input_data.drop("is_fraud", axis=1)
input_columns = list(input_data.columns)
#calculate predictions
predictions = model.predict(input_data)
# add prediction to training set
training_data['predicted_fraud']=predictions.astype(float)
# add outcome column
training_data.loc[(training_data["is_fraud"]==0),'fraud_outcome'] = 'Not Fraud'
training_data.loc[(training_data["is_fraud"]==1),'fraud_outcome'] = 'Fraud'
display(training_data.sample(5))The resulting training data:
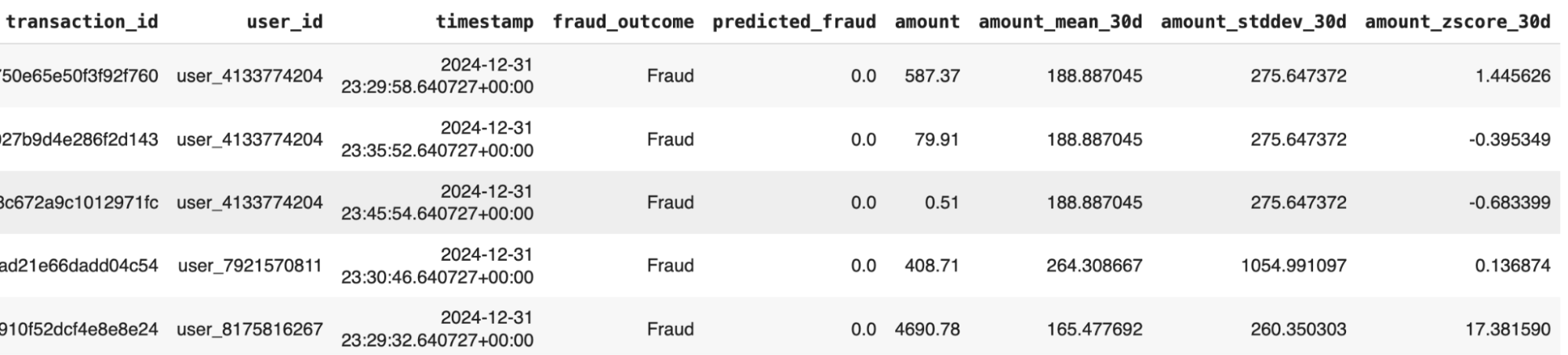
And here’s how the model and training data are logged:
response = arize_client.log(
dataframe=training_data, # includes event columns, training features and outcomes
schema=arize_schema,
model_id='transaction_fraud_detection',
model_version='v1.0',
model_type=ModelTypes.BINARY_CLASSIFICATION,
metrics_validation=[Metrics.CLASSIFICATION],
environment=Environments.TRAINING
)
The environment parameter defines whether this is training, validation or production data. Validation data along with its predictions are also logged in the same fashion.
Progress so far
Let’s look back at our ML application to see what progress we’ve made. In working backwards from our prediction step, we’ve come up with a way to generate training data to train a model using Tecton’s get_features_for_events method.
Additionally, we have a way to request features at inference time from the feature service we configured, using Tecton’s get_online_features method:
# feature retrieval for the transaction
feature_data = fraud_detection_feature_service.get_online_features(
join_keys = join_keys = {"user_id": current_transaction["user_id"]},
request_data = {"amount": current_transaction["amount"] }
)
# feature vector prep
columns = [ f["name"].replace(".", "__")
for f in feature_data["metadata"]["features"]]
data = [ feature_data["result"]["features"]]
features = pd.DataFrame(data, columns=columns)[X.columns]
# inference
prediction = {"predicted_fraud": model.predict(features).astype(float)[0]}This example is, of course, executing in a notebook, but it’s procedurally equivalent to a production implementation running in a real application. It retrieves fresh features and uses the model to run inference on them and produce a prediction.
Logging Predictions to Arize
When a model makes predictions using features from Tecton, the prediction result along with the input features and event identifiers are logged to Arize as an event. This enables Arize feature and model drift tracking by comparing values to the training and validation baselines.
So we add this code to each prediction:
# we put together the full event
publish_data = [ current_transaction | features.to_dict('records')[0] | prediction ]
# we add the yet unknown actuals as None
publish_data = [ publish_data | {"is_fraud":None, "fraud_outcome":None} ]
# and log it in Arize as production data
response = arize_client.log(
dataframe=pd.DataFrame(publish_data),
schema=arize_schema,
model_id='transaction_fraud_detection',
model_version='v1.3',
model_type=ModelTypes.BINARY_CLASSIFICATION,
metrics_validation=[Metrics.CLASSIFICATION],
environment=Environments.PRODUCTION
)
In this fraud detection scenario, the ground truth is whether a transaction is actually fraudulent. This information is typically unavailable until some future time—such as when cardholders dispute transactions as fraudulent. This delayed labeling is why Arize models specify a prediction_id_column_name that defines the data column that uniquely identifies the event. Arize’s asynchronous logging capability uses this prediction_id_column_name to link previously logged predictions with their eventual ground truth.
Example:
# log ground truth, only include actual label and prediction id columns
arize_schema = Schema(
actual_label_column_name="is_fraud",
prediction_id_column_name="transaction_id",
)
event_update = [
{
'is_fraud': 1.0,
'transaction_id': '57c9e62fb54b692e78377ab54e9d7387',
},
]
response = arize_client.log(
dataframe=pd.DataFrame(event_update),
schema=arize_schema,
model_id='transaction_fraud_detection',
model_version='v1.0',
model_type=ModelTypes.BINARY_CLASSIFICATION,
metrics_validation=[Metrics.CLASSIFICATION],
environment=Environments.PRODUCTION
)
And we can see what this will look like in Arize as we log predictions:
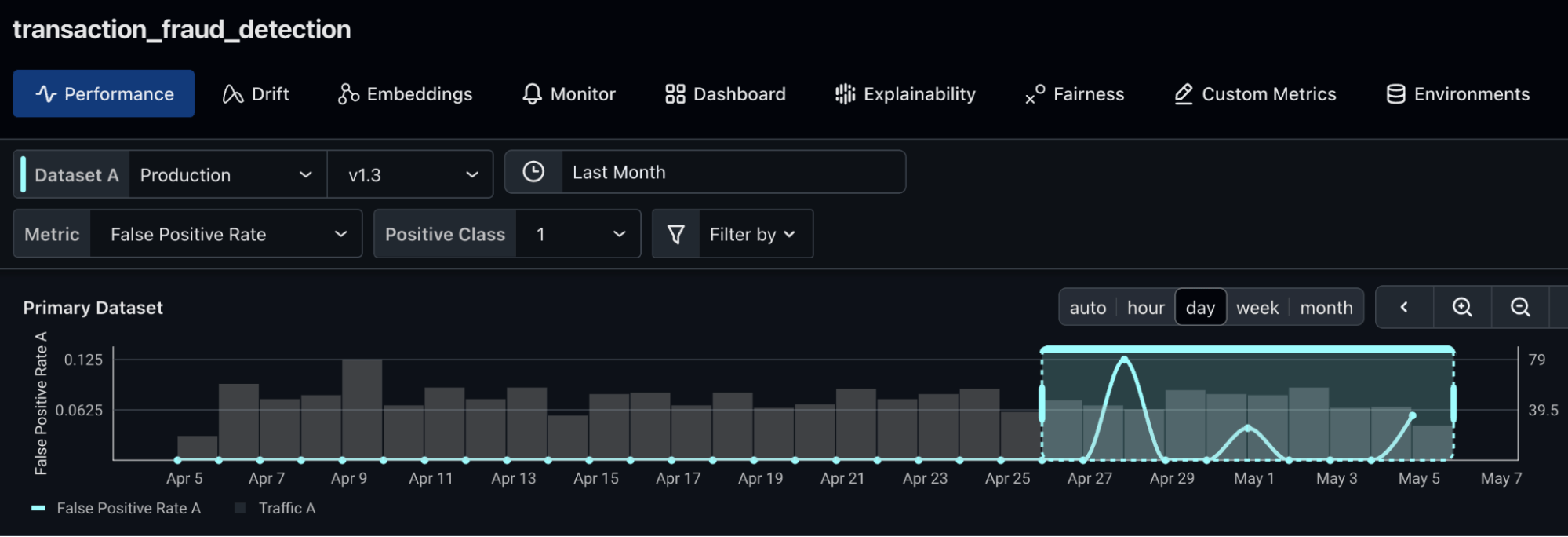
The Value of Drift Analysis
We implemented this logging strategy to enable Arize’s capabilities for model performance feedback and early warning alerts on our feature data pipeline. This analysis can then inform adjustments to feature engineering within Tecton and guide decisions about model retraining.
Here’s what Arize is now reporting. We can clearly see prediction drift:
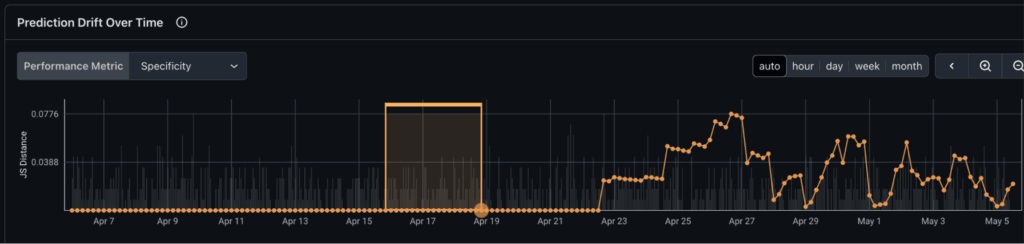
Understand what features are drifting:
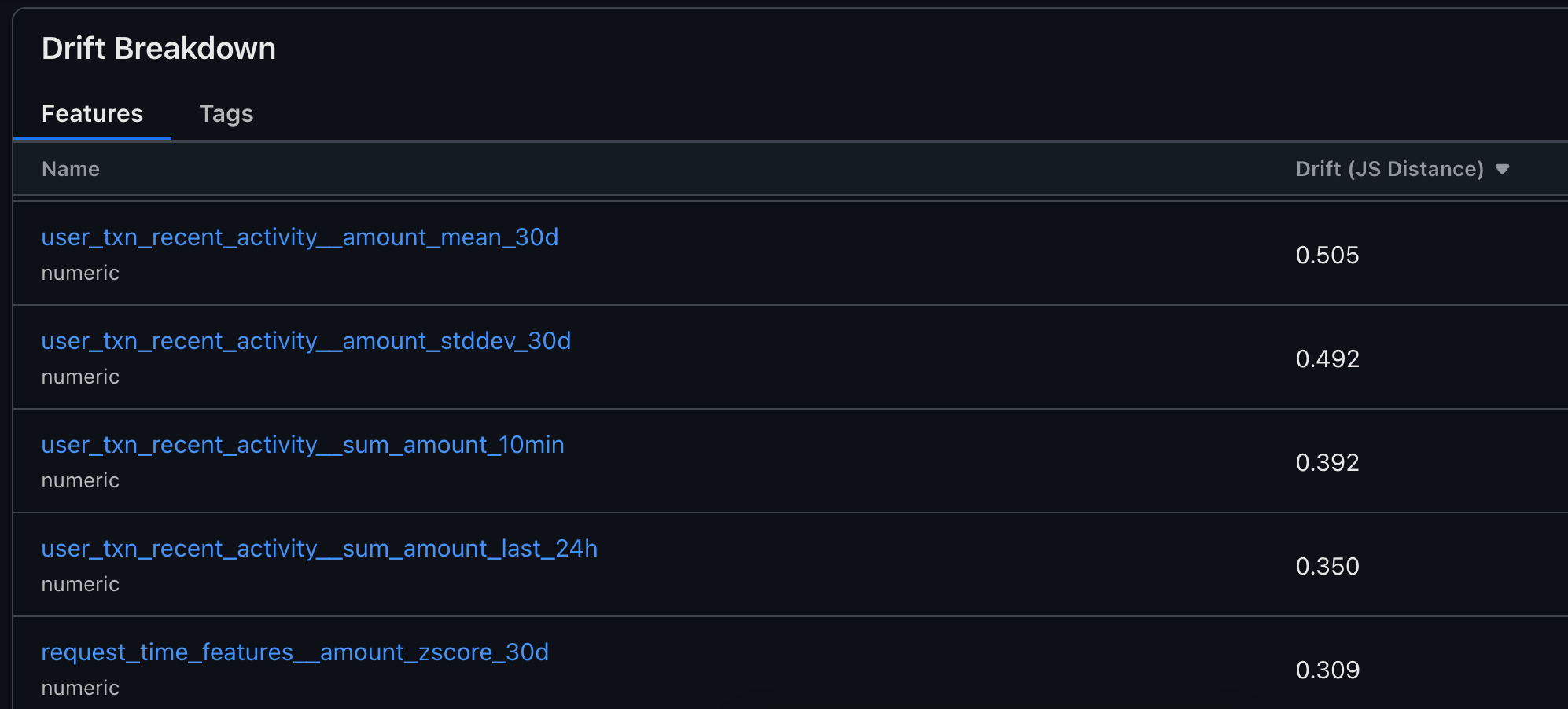
Examine individual feature drift:
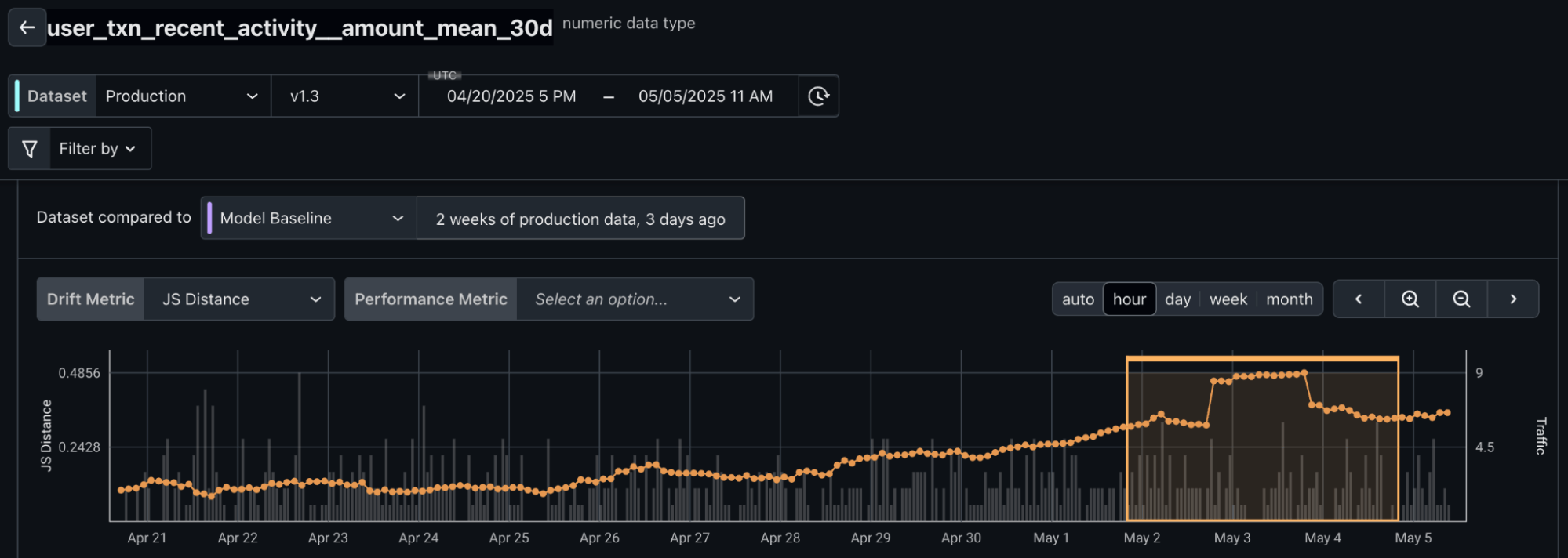
So now we have both a great monitor of model performance – ensuring we don’t get worse at detecting fraud over time – and an early warning system for issues in our upstream data or skew in our features.
Add Monitors and Alerting
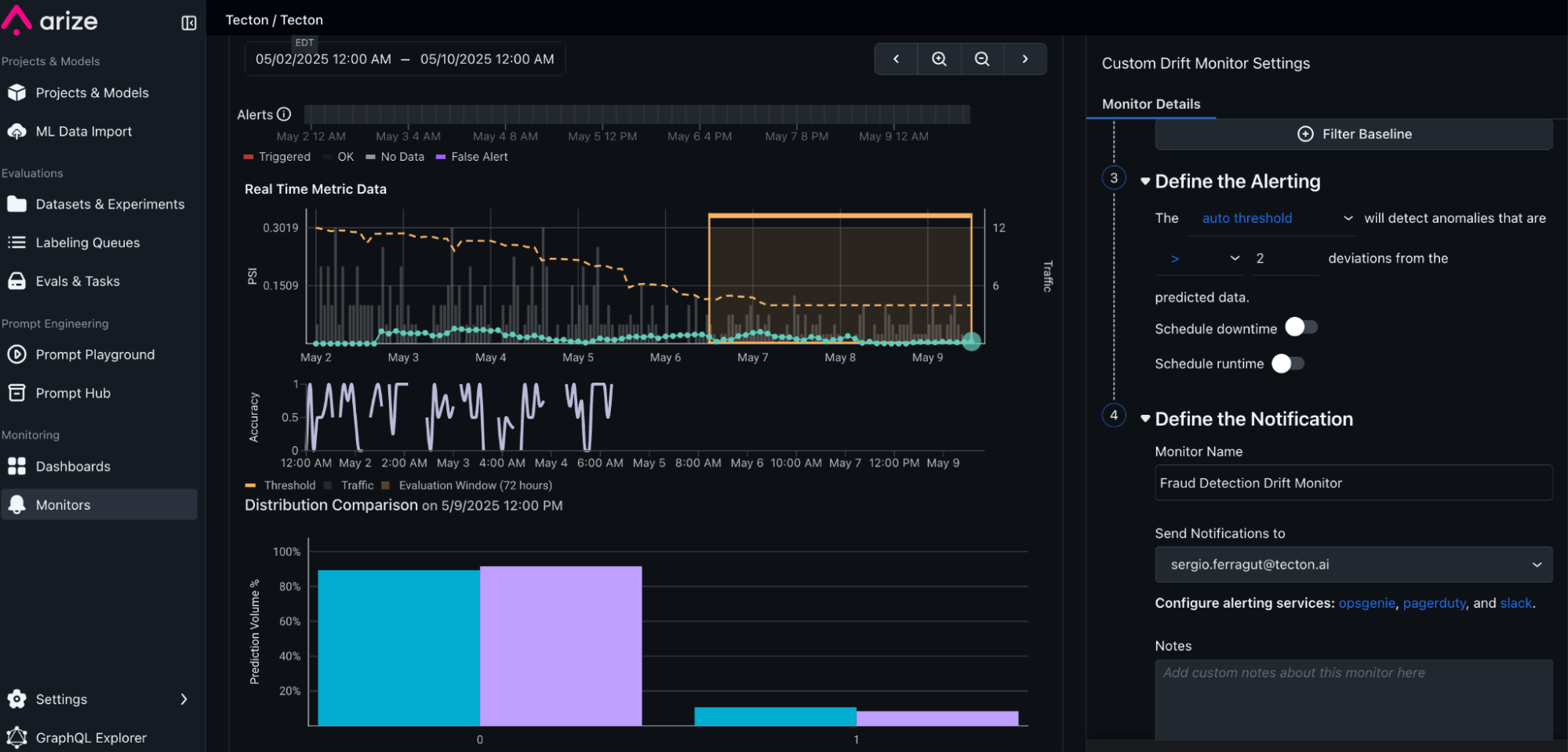
Learn more about Tecton and Arize:


