How Features as Code Unifies Data Science and Engineering



Feature engineering is a critical part of machine learning but it is frequently overlooked as a complex aspect of building successful models. Features are the lifeblood that ML models use to make predictions or decisions. Creating high-quality features requires domain expertise, data wrangling skills, and close collaboration between data scientists, data engineers, and ML engineers. However, the process of feature engineering is often fraught with challenges, such as:
- Difficulty in building and maintaining feature pipelines.
- Inconsistency between training and production features.
- Lack of reusability and shareability of features across teams and projects.
- Scalability and performance issues when calculating and serving features in real-time.
The following diagram lists much of the work that ML teams must undertake to build and deploy ML models in production:
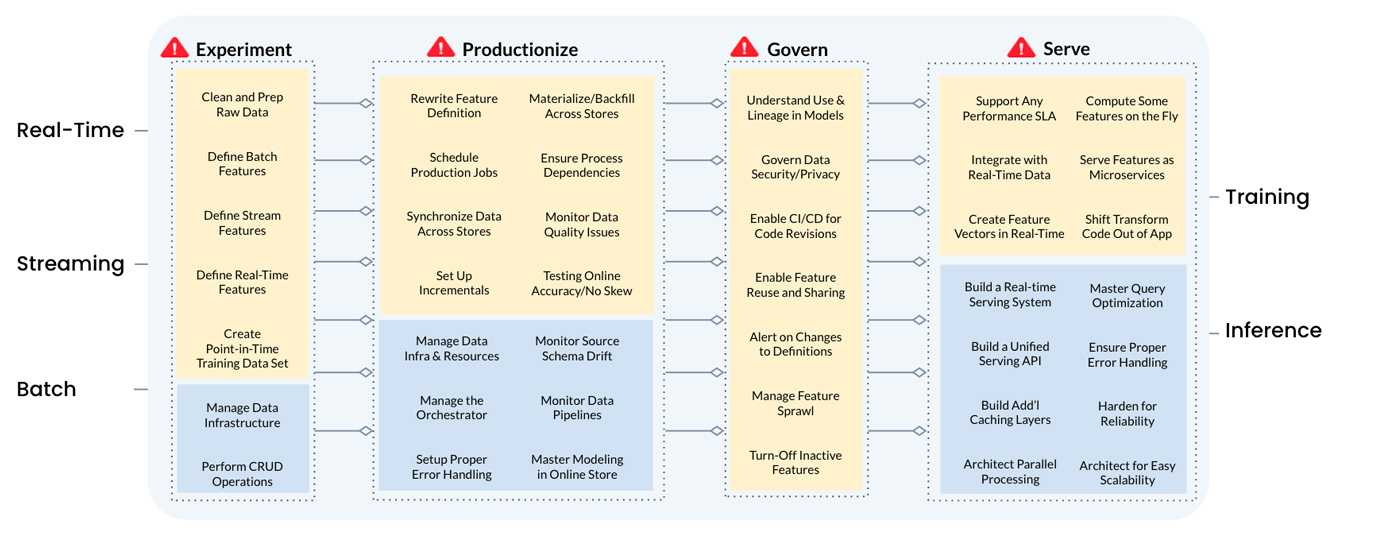
These challenges can lead to delays in model deployment, suboptimal model performance, and increased technical debt.
Feature Pipelines vs Data Pipelines
One of the key distinctions in feature engineering is the difference between feature pipelines and data pipelines. Data pipelines are responsible for moving and transforming raw data from source systems to data warehouses or data lakes. They focus on data ingestion, cleansing, and integration. Feature pipelines, on the other hand, are responsible for transforming raw data into features that are consumable by ML models. Raw data transformed into features are often needed with data freshness of minutes, seconds or even subsecond to fit within the span of each user interaction, so the challenges are more complex.
Data pipelines are usually well-established in organizations, mostly batch, with well controlled workflows. Feature pipelines, on the other hand, tend to be more ad-hoc, project-specific and much more dynamic as new features are added or old ones retired. The pressure to create or adjust feature pipelines in a timely fashion is tremendous. A lack of automation and standardization lead to inefficiencies and inconsistencies in the feature engineering process.
The Data Engineering Bottleneck in AI
The data engineering bottleneck is a common problem in AI projects. Data scientists often spend a significant amount of time on feature engineering, which can take away from their core responsibilities of model development and experimentation. On the other hand, data engineers are tasked with building and maintaining the infrastructure for data pipelines, which can be complex and time-consuming.
This bottleneck can be exacerbated by the lack of a clear separation between data pipelines and feature pipelines. Data engineers may not have the domain expertise to create high-quality features, while data scientists may not have the engineering skills to build the scalable and maintainable feature pipelines that deliver the necessary data freshness. They need to work together to get it right.
Abstracting the Feature Pipelines
To address these challenges, you need to abstract the feature pipelines and treat features as first-class citizens in the ML lifecycle. This involves creating a clear separation between the raw data and the features, and providing a standardized way to define, create, and serve features. Data scientists and engineers need a common language and a framework that allows them to work on the same codebase.
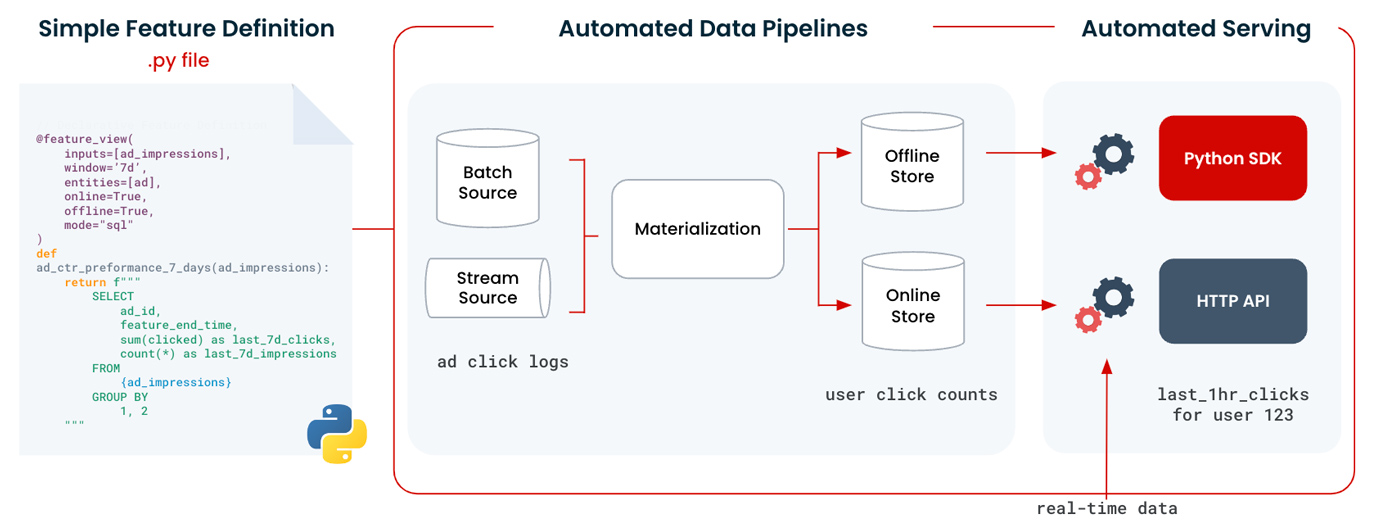
By abstracting the feature pipelines, organizations can achieve several benefits:
- Improved collaboration between data scientists, data engineers, and ML engineers.
- Increased reusability and shareability of features across teams and projects.
- Automate creation, execution and monitoring of feature pipelines.
- Consistent and reliable serving of features in real-time and batch scenarios.
Building the Right Feature Abstraction
To build the right feature abstraction, you need to consider the key components of a feature pipeline:
- Data sources: The raw data that serves as the input to the feature pipeline
- Transformations: The operations that are applied to the raw data to create features, this forms the bulk of the single codebase that is used to calculate features for both training and serving. This is the abstraction that enables training/serving consistency.
- Feature storage: The mechanism for storing and serving the computed features for both serving and training.
- Feature serving: The process of providing features to ML models in real-time or batch scenarios.
A good feature abstraction should provide a declarative way to define these components, using a language that is familiar to data scientists and engineers such as Python or SQL. It should also provide a clear separation between the definition of features and the underlying infrastructure for computing and serving them.
From Abstraction to Automation
By organizing the feature definitions and their serving requirements into a centralized code repository, organizations can use this code to drive the pipeline orchestration and execution mechanisms. A complete feature platform must be able to take these definitions and automate building, backfilling, provisioning and monitoring production ready pipelines that apply best practices. These best practices should be crafted to consider compute & cost efficiency, security, and governance needed to meet business, privacy and regulatory demands.
As the feature repository grows, it naturally becomes more valuable to the ML team. Work is never repeated if users can view and search features that are already in production. The platform should provide a mechanism to build and use training datasets from existing and new features. The training datasets it produces must incorporate point-in-time accurate feature vectors taken from multiple feature sets with different time aggregation granularities and different entities.
Building such a feature platform from scratch is a huge and complex software engineering project.
How Tecton Enables Features as Code
Tecton is a feature platform that enables organizations to build and manage features as code. It provides a declarative framework for defining features using Python, and automatically generates the necessary infrastructure for computing and serving features.
The Declarative Framework
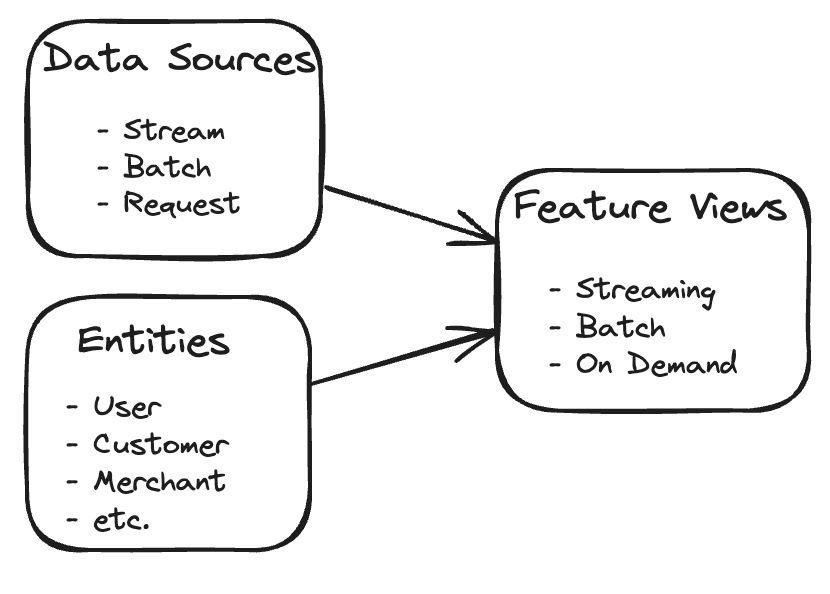
The key components of Tecton’s declarative framework are:
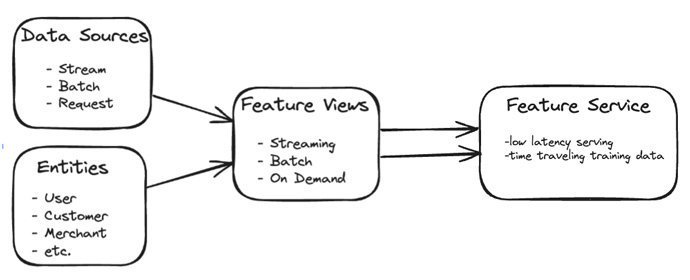
- Data Sources: Tecton supports a wide range of data sources, including batch data from data warehouses, or data lakes, streaming data from Kafka, Kinesis or Tecton managed push API, and request time data sources enable inference time raw data capture. Data sources specify the connection details and data schema they render. Data sources provide opportunity to do some preprocessing at the source for things like data cleansing and conforming either in SQL or Python.
- Entities: Entities are the business concepts that you describe through features, like a product, a customer or a merchant. You provide the primary key columns for each entity which informs Tecton on how to build join operations.
- Feature Views: Feature views define all aspects of a feature pipeline:
- Batch, streaming or request-time processing mode.
- Data sources to read data from.
- The Entity or Entities that the features relate to.
- Raw data transformations in user defined code using Python or SQL.
- Sliding time window aggregations expressed as a list of desired aggregate function, column and time window.
- Backfill horizon to create history for use in training.
- Optionally tune compute capacity to be used.
- Whether to feed the online and/or offline feature stores.
In Tecton, data scientists use the Declarative Framework directly in their notebooks to design and test features. Data engineers can then fine tune feature definitions for the data freshness, latency and scale that the application demands. Feature Views are then deployed to the platform to automatically create feature pipelines that materialize features onto online and offline serving infrastructure.
Tecton Feature Pipelines in Production
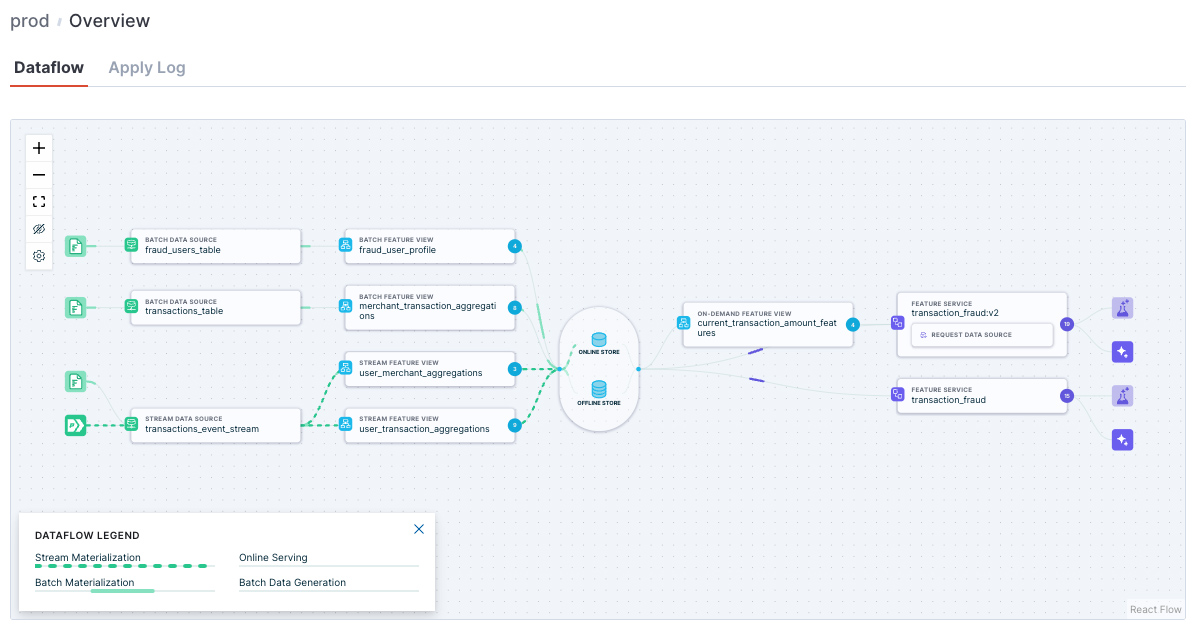
Feature Services are the last component of Tecton’s Declarative framework, they define the endpoints for serving features to ML models at training and inference times. A Feature Service is created to produce the feature vector needed for each ML Model. Feature Services list the Feature Views and features within them that create a feature vector. During experimentation and model development they provide point in time correct training data. At serving time, they provide the low latency and auto-scaling feature vector retrieval that power online inference.
By defining features using this declarative framework, data scientists and engineers can collaborate effectively, using a shared language and a standardized approach to feature engineering. Tecton automatically orchestrates the necessary infrastructure for computing and serving features, based solely on the declarative definitions. This includes data ingestion pipelines, feature transformation jobs, stream processing and request time feature calculations. Best practices are already incorporated for reliability, cost optimization and workflow orchestration while provisioning and de-provisioning infrastructure as needed.
Tecton also provides a rich set of tools for monitoring and debugging feature pipelines, including data lineage, data quality checks, and feature drift detection. This helps ensure that features are consistent and reliable across training and production environments. The platform also provides enterprise grade security, audit logging, and governance out of the box.
Conclusion
Feature engineering is a critical aspect of building successful ML models, but it is often fraught with challenges and inefficiencies. By abstracting the feature pipelines and treating features as first-class citizens in the ML lifecycle, organizations can streamline the feature engineering process and unlock the full potential of their data and their people.
Tecton’s declarative framework provides a powerful and intuitive way to define features as code, using Python and SQL. It uses the resulting code to automatically orchestrate the necessary infrastructure for computing and serving features. This enables data scientists and engineers to collaborate more effectively, and ensures that features are consistent and reliable across training and production environments.
With Tecton, organizations can accelerate the development and deployment of ML models, reduce technical debt, and drive innovation and business value. By empowering data scientists, data engineers, and ML engineers to build and manage features as code, Tecton is helping organizations unlock the full potential of AI and ML.
In the next post we delve deeper into Tecton’s Declarative Framework and how it is used to automatically bring feature pipelines into production with reliability and scalability.