Hidden Data Engineering Problems in ML and How to Solve Them



Machine learning teams are under constant pressure to embed AI into every customer interaction and experience. The demand for smarter features, personalized recommendations, and real-time decisions at every touchpoint is soaring. Yet, the intricate data engineering required to achieve this can slow projects down or block them entirely.
Transforming raw data into usable features, managing them at scale, and ensuring low-latency serving for real-time inference is an enormous task. Instead of developing innovative AI models, teams get stuck in an endless cycle of building and maintaining data pipelines, managing infrastructure, and ensuring data consistency.
It’s like having a high-performance race car that’s constantly stuck in the pit lane, unable to showcase its true potential on the track.
Core data engineering challenges for ML include:
- Building and orchestrating data pipelines
- Juggling batch, streaming, and real-time processing
- Managing compute and storage infrastructure
- Generating training data in production
- Addressing training/serving skew
- Building reliable, performant serving infrastructure for inference
This is where Tecton comes in. By abstracting away the complexities of data engineering and providing a unified platform for building and serving features, Tecton revolutionizes the way ML teams work with data.
In this blog post, we’ll dive into each of these data engineering challenges. We’ll explore why they exist, how they impact ML projects, and how Tecton completely eliminates them for you.
Building and Orchestrating Data Pipelines
Data engineers often spend more time on infrastructure and tooling than on actual feature development when building and orchestrating data pipelines. While orchestration tools like Apache Airflow exist, they have a steep learning curve and require a significant amount of coding. For example, in Airflow, engineers have to write DAGs (Directed Acyclic Graphs) to define the pipeline’s transformations, dependencies, and workflows.
These tools lack feature-level abstractions, meaning data engineers have to manage tables and schemas manually. This makes it difficult to iterate on features and requires a lot of manual work to ensure data consistency across tables.
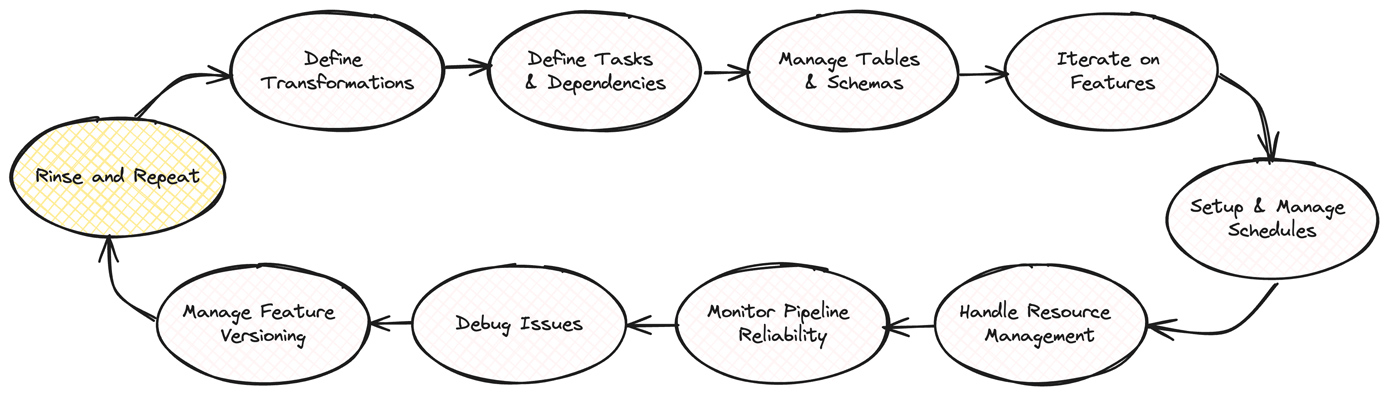
Moreover, using orchestration tools for feature pipelines involves a significant amount of overhead. Data engineers need to manage schedules, define tasks and dependencies, and handle resource management. They also need to constantly monitor the reliability of the pipelines and debug issues as they arise. This can be a time-consuming and frustrating process, especially when dealing with intricate feature dependencies and transformations.
Another challenge with using orchestration tools for feature pipelines is that they often do not have a built-in concept of feature versioning or lifecycle management. Data engineers need to manually manage the creation, updating, and deletion of features, which can quickly become unwieldy as the number of features grows. This lack of feature-level management also makes it difficult to track the lineage of features and understand how they are being used across different models and applications.
With Tecton… The construction and orchestration of data pipelines is completely automated. Instead of managing schedules, tasks, and resources with traditional orchestration tools, you can define features as code. This automation eliminates manual work and ensures data consistency across all stages, significantly reducing the overhead of managing and debugging pipelines.
Juggling Batch, Streaming, and Real-Time Processing
Building features with varying data freshness, especially streaming and real-time data, is challenging due to the complexity and multitude of tools and infrastructure required. Streaming storage systems like Apache Kafka and Amazon Kinesis are often managed by software engineering teams, creating access barriers for data scientists.
Streaming systems have limited data retention, making it difficult to create historical features or backfill data. Integrating streaming data with batch data sources further complicates the feature engineering process.
Processing streaming data is computationally intensive, particularly for tasks like calculating rolling window aggregations. Frameworks such as Apache Spark and Apache Flink require careful tuning and provisioning to handle the incoming data volume. Aggregations and stateful operations are especially challenging, as they require maintaining expensive in-memory state, which can lead to out-of-memory crashes if not properly managed.
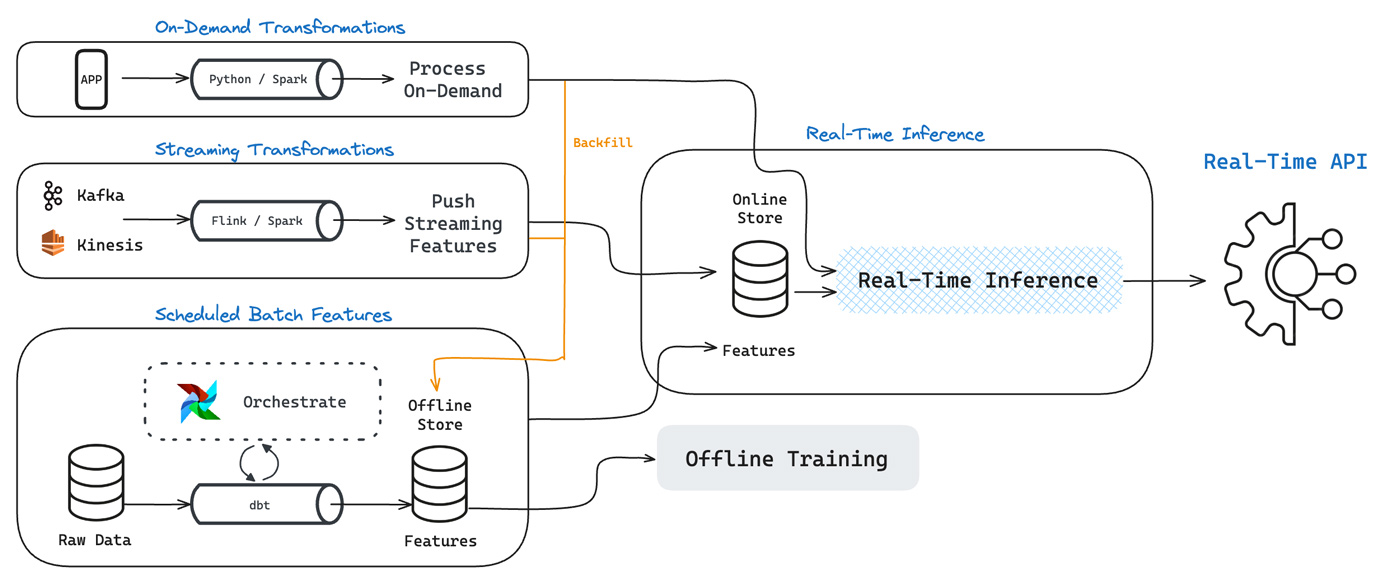
The combination of tool complexity, limited data retention, high computational requirements, and operational overhead makes it difficult for organizations to effectively leverage streaming data for feature engineering. As a result, many ML teams struggle to incorporate real-time data into their models, limiting their ability to deliver up-to-date context.
With Tecton… Batch, streaming, and real-time data processing are seamlessly integrated. Tecton provides built-in support for real-time processing and allows you to define features using Python, regardless of the data source. This enables unified processing and feature definition across batch, streaming, and real-time data. Tecton computes and serves features on the fly, eliminating the need for specialized skills to work with streaming data systems like Apache Kafka or AWS Kinesis.
Managing Compute and Storage Infrastructure
Managing compute and storage infrastructure for feature engineering can quickly become a significant burden for data engineering teams as the number of feature pipelines grows.
Deployment and configuration complexity is a major challenge. Distributed processing frameworks like Apache Spark and Apache Flink are powerful but notoriously difficult to set up and manage. Spark, for example, has hundreds of configuration parameters that require tuning for optimal performance, leading to delays and increased operational costs.
Another challenge is managing and scaling compute clusters. Spark clusters can take 10 minutes or more to start up, creating bottlenecks in the feature development process. Many companies may not have data volumes that justify the cost of maintaining large-scale clusters, resulting in wasted resources and increased operational burden.
On the storage side, data engineers must ensure the underlying infrastructure supports the volume, variety, and velocity of data required for feature materialization. This often involves managing a mix of storage technologies, such as data lakes, data warehouses, and real-time databases, each with its own performance characteristics and operational requirements. Ensuring data consistency and accessibility across these storage layers is a significant challenge that requires careful planning and ongoing maintenance.
With Tecton… The deployment, configuration, and scaling of compute and storage infrastructure is fully managed. Setting up and tuning distributed processing frameworks like Apache Spark becomes effortless. Tecton’s infrastructure scales automatically to meet your data volume needs, optimizing performance and cost.
Generating Training Data in Production
Generating training data in production is a significant hurdle due to the sheer volume of data that needs to be processed, often involving joining a multitude of tables with millions of records. This requires substantial compute resources and can take hours or even days to complete.
Ensuring point-in-time correctness is a major obstacle. To train accurate models, the training data must reflect the state of the world at a specific moment, meaning all features must be calculated based on the data available at that particular time. Achieving this level of temporal consistency is difficult and error-prone, especially when dealing with data from multiple sources that may be updated at different frequencies.
Data engineers often have to manually construct complex ETL (extract, transform, load) pipelines using various tools and frameworks like Apache Spark, Apache Airflow, and different data storage technologies. Even with these tools, building training data pipelines is time-consuming, labor-intensive, and requires significant expertise and ongoing maintenance.
Moreover, the rigid nature of traditional ETL pipelines often conflicts with the iterative nature of feature engineering and model development. Data scientists need flexibility to experiment with different feature transformations and model architectures, but they often have to wait for new features to be engineered and integrated into the pipeline before they can start training their models, leading to unnecessary overhead and delays.
With Tecton… The creation of training datasets is simplified by ensuring point-in-time correctness and automating the ETL process. This approach allows data engineers to build accurate, temporal-consistent training data without writing complex pipelines. Tecton’s platform supports iterative feature engineering and model development, making it easy for data scientists to experiment and integrate new features rapidly.
Addressing Training/Serving Skew
Training/serving skew is a critical issue in machine learning that occurs when there is a discrepancy between the data used to train a model and the data the model encounters in production. This skew can arise due to various reasons, such as differences in data sources, preprocessing steps, or feature engineering pipelines. When left unaddressed, training/serving skew can significantly impact model performance and reliability, leading to suboptimal or even incorrect predictions.
One of the main causes of training/serving skew is the use of different codebases or pipelines for generating features during model development and production. In the development phase, data scientists often work with smaller, curated datasets and use various tools and libraries to explore and engineer features. However, when it comes time to deploy the model, the production pipeline may use different tools, libraries, or even programming languages, leading to subtle differences in how features are calculated and transformed.
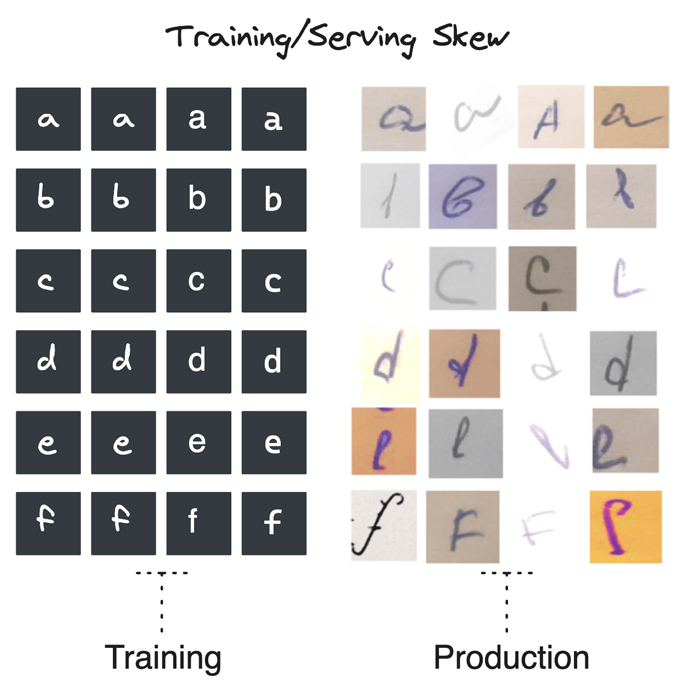
These discrepancies can accumulate over time, resulting in a gradual drift between the training and serving data distributions. As a result, the model may start to perform poorly or make incorrect predictions, as it encounters data that is significantly different from what it was trained on. This can be particularly problematic in applications where the model is making critical decisions, such as fraud detection or insurance underwriting, as incorrect predictions can have serious consequences.
Addressing training/serving skew requires careful coordination between data science and engineering teams to ensure that the same codebase and pipeline are used for feature generation across both development and production environments. This requires a deep understanding of the end-to-end machine learning lifecycle and the ability to build robust, scalable pipelines that can handle the volume and intricacy of production data. Additionally, it requires ongoing monitoring and validation to detect and correct any skews that may arise over time, such as those caused by improper handling of late-arriving data in stream processing.
With Tecton… Training/serving skew is addressed by using the same codebase and pipeline for feature generation across environments. Built-in monitoring and validation detect and alert on any discrepancies that may arise over time.
Building Reliable, Performant Serving Infrastructure for Inference
Building reliable, high-performance serving infrastructure for inference is vital when deploying machine learning models in production. Delivering real-time features with low latency and high throughput is particularly difficult when dealing with streaming data or intricate feature transformations.
Computing real-time features at inference often requires extensive manual coding and optimization, frequently involving custom feature serving logic tightly coupled to the application, making it hard to maintain.
Achieving fast read performance for aggregated values on streaming data at inference time is another significant hurdle. Many use cases require features based on aggregations over sliding time windows, such as recent user logins or average transaction amounts. Computing these aggregations in real-time is daunting, demanding careful design and optimization.
With Tecton… Robust serving infrastructure to deliver real-time features with low latency and high throughput is built-in. Tecton computes real-time aggregations and maintains state efficiently. Its optimized infrastructure mitigates memory issues and reduces read latency, ensuring that your models can deliver fast, accurate predictions.
AI Development with Tecton
Tecton takes care of the heavy lifting of data engineering, addressing both the coding and infrastructure management aspects. When it comes to coding, Tecton provides a unified platform where features can be defined as code, eliminating the need for ML teams to manually develop and maintain complex data pipelines. This abstraction allows data scientists and ML engineers to focus on feature definition and model development, rather than getting bogged down in the intricacies of building, validating, and orchestrating pipelines.
On the infrastructure side, Tecton goes beyond just simplifying the coding process. It takes full responsibility for computing and storing features on robust, scalable infrastructure. ML teams no longer need to worry about provisioning and managing the underlying systems required for feature engineering and serving. Tecton handles the end-to-end management of these systems, ensuring optimal performance and reliability.
Having Tecton is like having a team of expert data engineers building and maintaining a custom data platform tailored for AI/ML. This eliminates the need for your ML team to stitch together and manage multiple systems themselves. Tecton not only handles the underlying infrastructure but also streamlines the operational workflows involved in using the platform, reducing complexity and saving your team valuable time and resources.
Get started with Tecton
Teams at companies like FanDuel, Plaid, and HelloFresh use Tecton to scale more ML applications with fewer engineers and build smarter models, faster.
Interested in learning more about how Tecton can unblock your ML projects? Check out the interactive demo that takes you through our feature engineering to serving experience.
You can also reach out to us or schedule a demo of Tecton—we’d love to help!