How Coinbase Builds Sequence Features for Machine Learning




This post originally appeared on the Coinbase blog. We’re excited to cross-post it here to highlight how Coinbase uses Tecton to build and productionize features that power real-time ML applications like fraud detection and recommendations.
TL;DR: Coinbase has developed a framework to rapidly develop and productionize user sequence features, improving model performance for both fraud detection and recommender systems.
At Coinbase, we use machine learning for a diverse set of applications, from intelligent notifications to fraud detection. Each of these use cases depends on a variety of numerical, text and categorical features, but we have also invested heavily in better supporting sequence modeling, which enables models to learn directly from sequences of user actions.
Productionizing robust sequence learning models required changes to our streaming infrastructure and new observability methods. Early results have improved model performance for both fraud detection and recommender systems and delivered tens of millions of dollars in impact on key business metrics over the past year. For many critical models, there are several sequence features in the top 10 global feature importance.
Traditional feature engineering for predictive ML
Predictive ML systems typically leverage hundreds to thousands of hand-crafted features. These features are often long-running aggregations developed by domain experts that are updated daily (batch) or near-realtime (streaming). For example, one feature used in a recommender system at Coinbase could be a batch feature representing “how many times has the user purchased a digital asset in the last 30 days.” This simple integer feature can then be used by many different models regardless of their architecture. At Coinbase, we have over 5,000 of these features managed by our ML Platform.
One challenge with traditional features is that they rely heavily on domain expertise and discard potentially useful information. For example, the feature above does not contain any information on
- Which digital assets (BTC, ETH, etc.) the user purchased
- How much of each asset the user purchased
- At what time the user made each purchase
Crafting additional features to capture this information would be time-consuming and may not necessarily improve model performance.
Sequence features
An alternative approach is to skip hand-crafted feature engineering entirely and learn directly from sequence data. For example, we might choose to build a sequence like below:

Certain model architectures can then learn directly from these rich sequences, with deep learning techniques such as Transformers and LSTMs being especially popular.
In the next section on sequence learning, we discuss the design considerations and tradeoffs for building and serving this kind of sequence feature for hundreds of millions users.
Designing sequence features
Sequence semantics
When designing a sequence features, we need to consider semantics of the user sequence:
- Event selection: which events and metadata are included in the sequence
- Sequence length: how many events can be included in a user’s sequence
- Lookback window: what time range do we consider (e.g. user lifetime, last 6 months, 1 day etc.)
- Freshness: how soon after an event is produced is it servable in the sequence
- Offline read-time latency: how long does it take to generate large training datasets or for batch prediction workloads
- Online read-time latency: what is the latency for fetching the sequence during online inference, typically for a single user
Each of the choices in semantics has major implications for the infrastructure needed for computing and serving the sequence. While we need the framework to be flexible, we have found the following requirements are common across all our use-cases:
- Event selection: <100 event types per sequence
- Sequence length: up to 1000 most recent events at read-time
- Lookback window: highly dependent on use-case, ranges from hours to lifetime
- Freshness: 1-2 second freshness
- Offline read-time latency: <1 day, ideally 1-2 hours
- Online read-time latency: <100ms p99 latency
Computing and serving sequence features
To meet the requirements above, we have implemented our framework on top of Tecton and Databricks Spark.
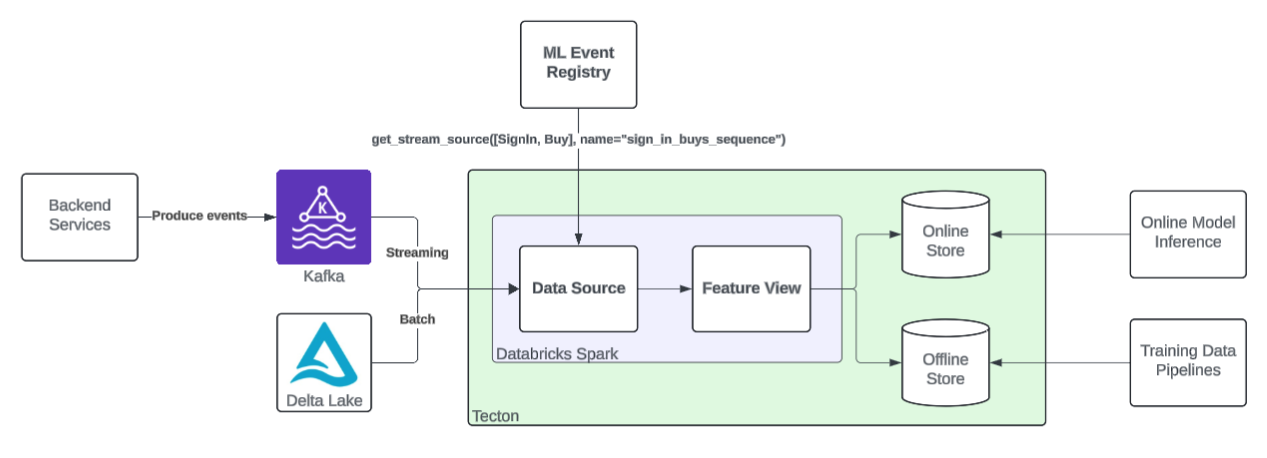
Framework
Our goal for the sequence framework is for Machine Learning Engineers (MLEs) to simply declare their desired topic, event schema, and sequence semantics. The framework then automatically creates the data sources and Tecton feature views that implement the desired sequence semantics in a cost-efficient way and with out-of-the-box observability.
ML Event Registry
At Coinbase, there are thousands of different events across hundreds of Kafka topics that may be useful for ML applications, each with their own schema. For our framework to support an evolving set of events, we explicitly register each event that will be consumed by an ML application.

MLEs then interact with the event registry to generate Tecton data sources by selecting one or more events and their desired metadata.

Under the hood, our framework autogenerates Tecton Spark data source functions that
- Load each event from various Kafka topics (for streaming) and Delta Lake tables (for batch and backfills)
- Transform the unique schema for each event into a standardized schema
- user_id: StringType
- event_name: StringType
- timestamp: TimestampType
- metadata: StructType
- Union the transformed events into a single Spark dataframe for feature computation
By introducing an event registry and simplifying data source generation, we enable MLEs to quickly discover and select useful events. In practice, MLEs have used as many as 50 events in a single sequence feature and dozens of metadata fields.
Spark pipelines
Under-the-hood, each sequence feature maps to a Tecton feature view and Spark job. For most use-cases, feature freshness is critical, so these are typically Tecton streaming feature views that leverage Spark structured streaming.
To achieve second-level freshness, we use Tecton’s “continuous” mode, which tells Spark to run with a micro-batch time interval of 0 seconds. This means that each sequence feature pipeline is stateless: it simply consumes a Kafka event, transforms it to the framework enforced schema, and writes it to the online store (DynamoDB). This gives us the lowest possible Spark processing time between a Kafka event being produced and it being available for online serving. The online serving compute is then responsible for rolling up each event into a full sequence at read-time.
In the diagram below, we can see an average end-to-end latency of <500ms for one of our most demanding streaming jobs consuming ~2k events/second.
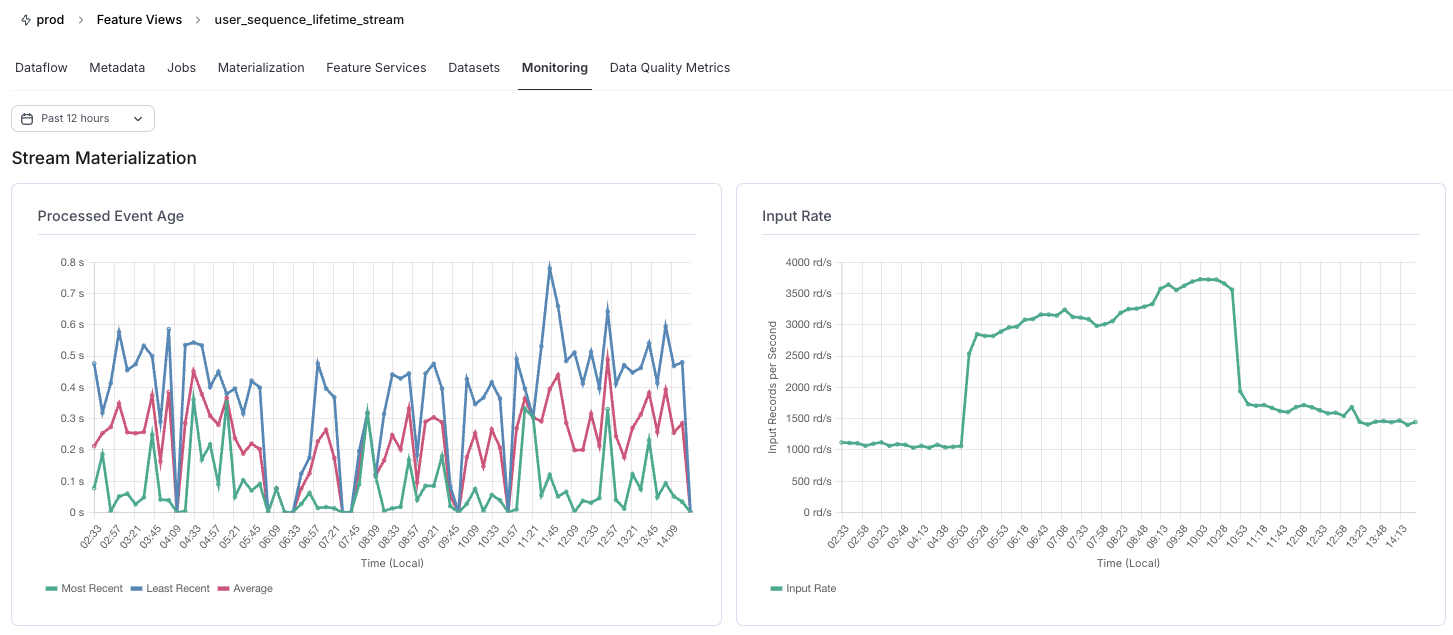
Databricks compute optimizations
While the stateless streaming jobs described above require much less memory intensive than stateful aggregations would, we still needed to optimize the Databricks compute to achieve the best performance at acceptable costs.
By default, Databricks uses a dedicated instance for the driver and each worker node in the Spark cluster. With a hypothesis that our stateless jobs could easily run on a single instance, we experimented with Databricks Single Node clusters. In our Databricks cluster JSON, we simply added the following settings:

By running both the driver and worker on a single machine, we achieved identical or even improved freshness for all our streaming workloads with 20-40% fewer CPUs and compute cost.
Read-time transformations
So far, we have only discussed pipelines transforming raw events into sequences. However, there is a common need for further application-specific transformations. For example, we may want to add a special token to indicate a day passing, ex.
<DAY>, event_1, event_2, <DAY>, <DAY>, event_3, …
With Tecton’s Real Time Feature View, we can achieve this by defining row-level transformations in Python. The example above can then be implemented and used by any model as shown below:

This same pattern can support many other transformations such as filtering certain event types, adding sinusoidal positional encodings, or interleaving several different sequences.
Conclusion
Sequence learning is one of the most promising methods for Coinbase to continue to improve model performance. By creating a simple framework for production-ready sequence feature pipelines, we have streamlined the developer workflow, encouraged feature reuse, and unlocked rapid adoption of sequence learning. We have also abstracted away the complex streaming and operational requirements that make it challenging to productionize sequence learning, shifting Machine Learning Engineers focus to semantics instead of infrastructure details.
Future work
A major challenge with sequence features is their inherent dependency on many upstream producers. In future blogs, we plan to review a collaboration between the Data Platform and ML teams to improve observability and governance of events.
We are also exploring developing “foundation models” that learn broad representations of users from sequence features which can be used in a variety of downstream prediction tasks.
Acknowledgements
The growth of sequence learning at Coinbase has been a collaboration between the ML Platform, ML Risk, Recommendations, and Data Platform team. We would like to specifically thank
- Li Liu and Roman Burakov for their design partnership and for being early adopters
- The ML Leadership team Jordan Steele, Vijay Dialiani, and Rajarshi Gupta
- Eric Sun, Yisheng Liang, and Mingshi Wang on the Data Platform team
- Raymond Yao, Wenyue Liu, Aman Choudhary, and Sepehr Khosravi


