How Tecton Helps ML Teams Build Smarter Models, Faster



In the race to infuse intelligence into every product and application, the speed at which machine learning (ML) teams can innovate is not just a metric of efficiency. It’s what sets industry leaders apart, empowering them to constantly improve and deliver models that provide timely, accurate predictions that adapt to evolving data and user needs.
Moving quickly in ML isn’t easy, though. Model development is a fundamentally iterative process that involves engineering and experimenting with new data inputs (features) for models to use. The quality and relevance of features have a direct impact on model performance and accuracy—the more teams can experiment with, perfect, and productionize new features, the better their models will be.
But developing a new feature and deploying it in production can take weeks to months of collaboration between data scientists, ML engineers, and other stakeholders. In fact, these teams often spend upwards of 70% of their time on feature and data engineering.
So, where exactly are the bottlenecks to building and launching new features, and how can they be avoided? Hint: it’s all in the data.
Data challenges in feature development and deployment
More businesses want to productionize ML, or in other words, use ML in customer-facing applications to autonomously and continuously make decisions that impact the business. But those in the earlier stages of ML development may not realize the most difficult part of productionizing ML is managing the data that feeds these applications.
For example, for building a real-time recommendation system, an ML team would have to take raw, messy data, build and experiment with features (which may come from a variety of real-time, streaming, or batch data sources) then get those features to the models for training and inference. Along the way, they would spend countless hours going back and forth to iterate on models and refine features, a process that is not only time-consuming but also requires deep technical expertise in both data engineering and machine learning.
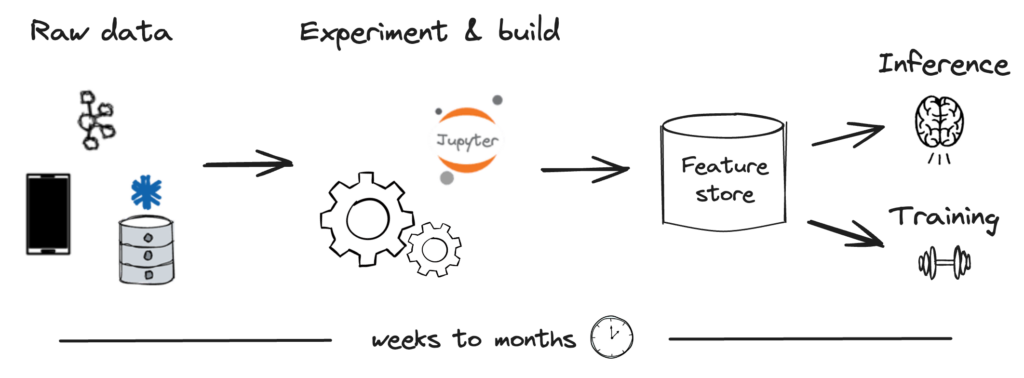
Throughout this process, we see teams experience four major bottlenecks:
- Experimentation: Creating a development environment that empowers data scientists to effortlessly create new features from diverse data sources is a significant challenge, but this flexibility is essential for facilitating quick testing and rapid iteration within ML teams.
- Productionization: Transitioning those defined features into production data pipelines quickly, reliably, and accurately is an even more daunting task. This step is crucial for the real-world application of ML models, requiring a seamless bridge from experimental to operational status.
- Governance: Managing the proliferation of feature pipelines and effectively governing features at scale is another complex issue. As the number of features grows, it becomes increasingly difficult to maintain an organized, efficient system that avoids duplication and ensures consistency.
- Serving: Finally, serving features in a production environment to meet stringent and sometimes diverse requirements for data freshness, throughput, and latency is challenging. This capability is vital for ensuring that ML models perform optimally, providing accurate, timely insights based on the most current data available.
The role of a feature platform
If done manually, managing data for ML is complex and fraught with potential pitfalls. Building and managing systems to support each stage of the development process demands substantial resources, time, and expertise across multiple domains, making it challenging for most organizations to undertake independently.
Enter the feature platform—a game-changer in accelerating the development and deployment of ML models. Some digital-native companies have already taken on the creation of custom platforms to tackle the intricacies of feature management, addressing major pain points in the process of engineering and productionizing features. This has empowered their ML teams to iterate rapidly and bring innovative, ultra-personalized product experiences to market in a fraction of the time.
However, building such a platform from scratch is incredibly difficult and can take years to complete. Ultimately, many organizations still find themselves stuck in the rut of building and maintaining bespoke systems and potentially hundreds to thousands of one-off data pipelines for features, which, despite their efforts, often fall short in scalability and reliability.
Tecton represents the ideal, out-of-the-box feature platform, providing an abstraction that allows engineers to focus on what they do best: building models that deliver value, not wrestling with the underlying infrastructure. Tecton provides ML teams with the self-service experience and infrastructure needed to support experimentation, production, governance, and serving—all within a cohesive and scalable environment—enabling them to operate with a level of speed and efficiency that was previously unattainable.
How Tecton solves ML data challenges
Rather than the typical weeks or months required to create new features and productionize them in models, Tecton provides a self-service environment where these tasks can be executed in just minutes. We improve teams’ development velocity and enable companies to build better models, faster, across every phase of the ML data lifecycle.
Rapidly experiment with new features and models
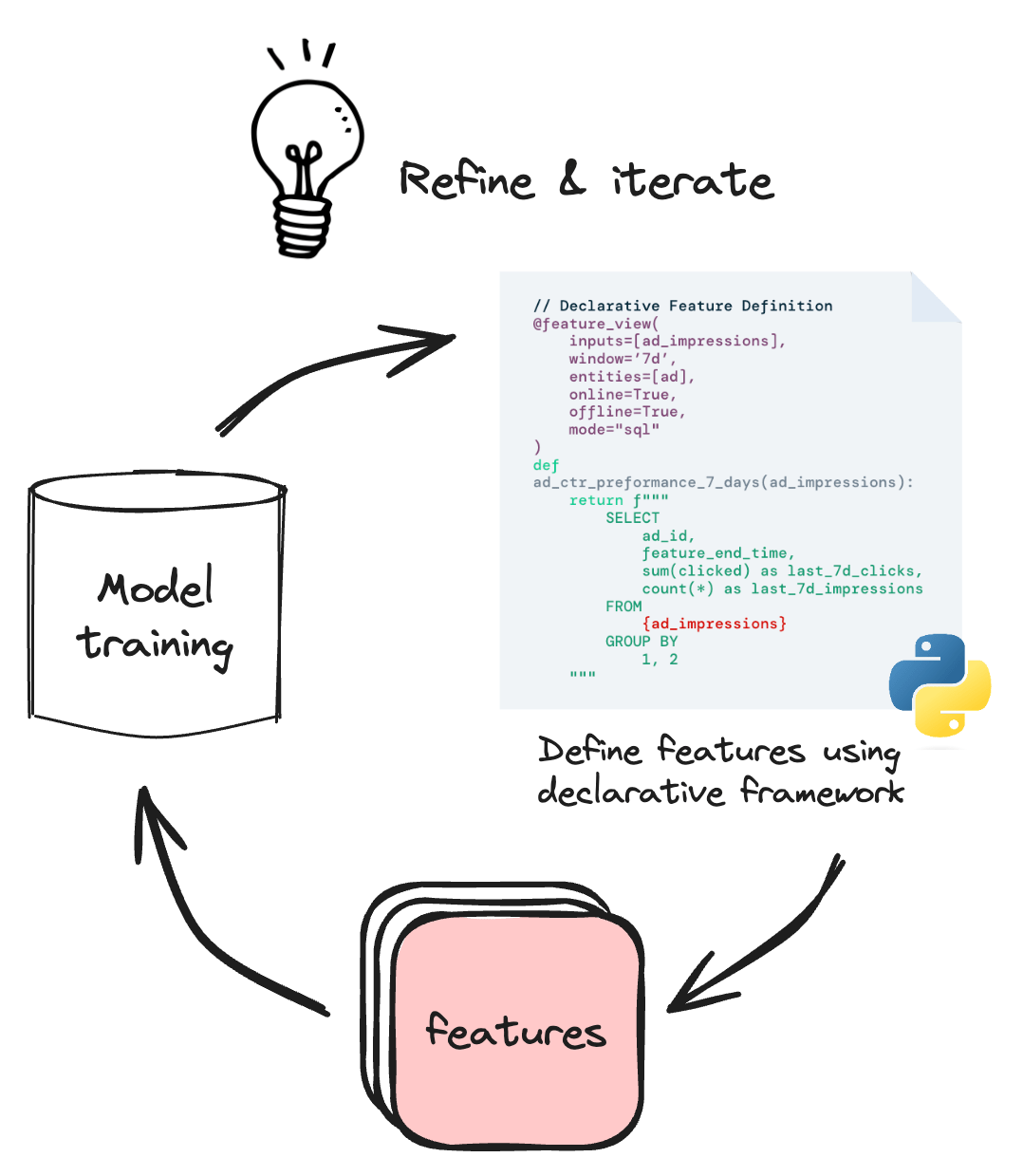
Tecton offers a streamlined and rapid development experience for feature engineering. Using our declarative framework, users can easily define and test features from diverse data sources (including streaming, batch, and real-time data). With our abstraction layer, creating or joining tables, moving data, or configuring databases is not required. Features can be defined in Python or reused from existing features, enabling the creation of training datasets in just a few lines of code.
Productionize features in under a minute

With Tecton, engineering teams are freed from the burden of constructing and upkeeping feature pipelines, as we manage these operations seamlessly. To productionize a feature, users simply have to specify the desired characteristics of the features—such as the data source, transformations, update frequency, and serving latency—within the declarative framework. Then, Tecton efficiently constructs and executes reliable data pipelines and infrastructure, ensuring the generation and storage of computed features for precise models and predictions.
Centralize and manage features in one place
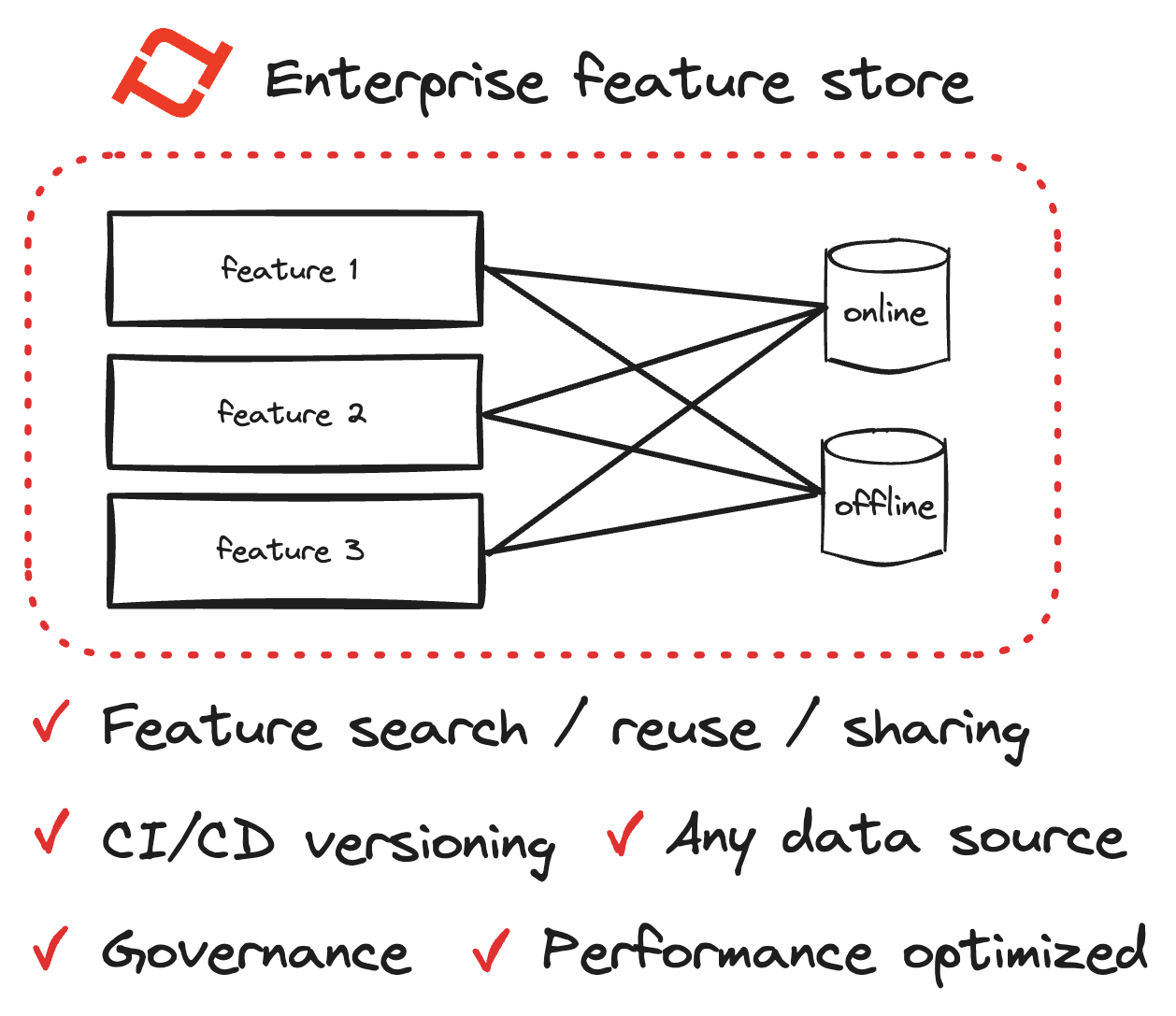
Tecton’s enterprise feature store is a centralized repository for managing, sharing, and retrieving features across various data sources and projects. This feature store streamlines the governance, sharing, and reuse of features, promoting collaboration across teams. It ensures consistency across offline and online stores, preventing online/offline skew and enhancing model accuracy. For platform teams, it offers centralized governance, preventing feature pipeline sprawl and facilitating cost control.
Serve data for any production application
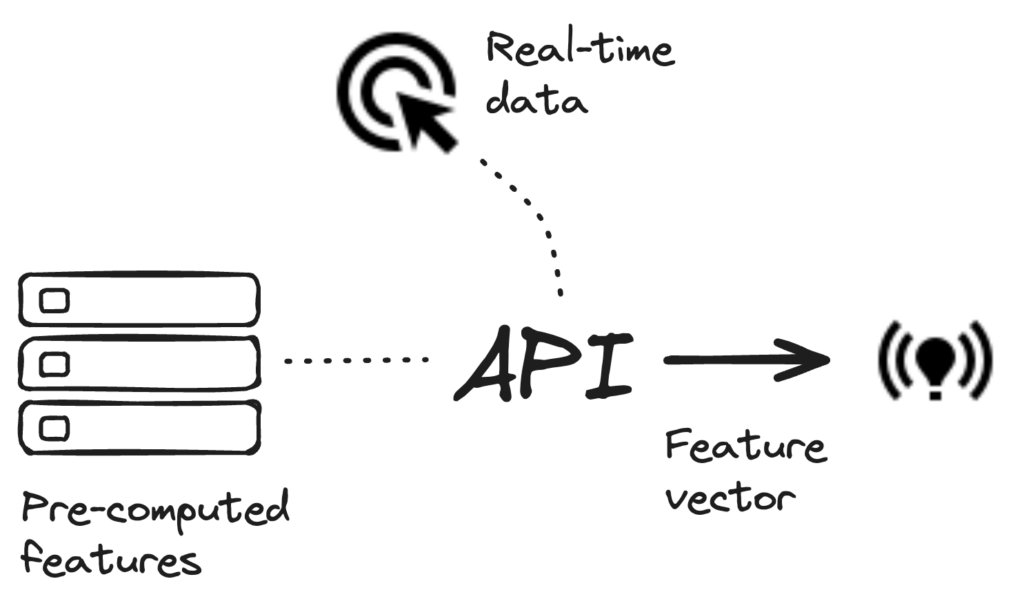
Tecton’s unified serving system is designed to serve any model for any performance SLA, with a single API endpoint that provides fast, reliable, and scalable access to features needed for inference. It supports both real-time and batch ML applications, enabling low-latency access to pre-computed and real-time computed features. This system ensures that features can be served at any freshness, throughput, or latency requirement, backed with an enterprise SLA for reliability.
Lastly, Tecton streamlines the ML data lifecycle by consolidating the functionalities of various tools into a single integrated platform. Traditionally, teams would need separate systems for connecting to diverse data sources, processing data in streaming, batch, and real-time formats, orchestrating and monitoring production pipelines, as well as managing and serving features.
Tecton simplifies all of this by offering a unified solution that eliminates the need to juggle multiple disparate systems, resulting in enhanced efficiency and reduced overhead associated with maintaining multiple tools. Together, these components form a robust platform that abstracts away the engineering required to activate data and serve it to models.
Tide achieves 2x faster time-to-production
Tide, a UK-based financial services platform for businesses, ran into limitations in building real-time ML models due to limitations of its in-house feature store. These limitations included difficulty in adding features, unpredictable production changes, slow iteration times, and heavy engineering requirements. As a result, deploying a new model was a long and laborious process, typically spanning two to four months. To address these challenges and expedite ML model deployment, Tide evaluated the Tecton feature platform.
With Tecton, Tide significantly improved its ML model iteration speed and deployment efficiency. Tide benefited from the easy reuse of high-quality features, streamlined backtesting processes, and reduced deployment times. Tecton’s platform enabled Tide to cut model deployment time in half, while also increasing model accuracy with 7x more features and deploying 2x more models.
Tide uses Tecton for real-time ML use cases like credit risk assessment and transaction fraud detection, which require a high level of precision and access to fresh features. By providing a unified environment for feature engineering, Tecton allowed Tide to easily create and incorporate high-quality features from both historical and real-time data sources into their models. Overall, Tecton’s platform significantly sped up time-to-value for new features, enabling the Tide team to deploy more models with more accurate predictions.
Get started with Tecton
Teams at companies like FanDuel, Plaid, and HelloFresh use Tecton to scale more ML applications with fewer engineers and build smarter models, faster.
Interested in learning more about how Tecton can unblock your ML projects? Check out the interactive demo that takes you through our feature engineering to serving experience.
You can also reach out to us or schedule a demo of Tecton—we’d love to help!