Rethinking Feature Engineering for ATO Detection


Why building ATO detection features doesn’t require an army of data engineers.
Account takeover (ATO) detection is one of the most feature-intensive machine learning problems you’ll encounter. To effectively identify when legitimate users’ accounts are being compromised, you need to analyze dozens of signals across multiple time windows, correlate streaming and batch data, and serve everything in real-time with millisecond latency.
Selecting the right signals to detect ATO is challenging, especially since fraudsters are coming up with new attack vectors all the time, and fraud detection teams need to iterate continuously to keep user accounts safe.
Unfortunately, iteration speed is held back by one simple truth: Most of your time gets consumed by data engineering, not the actual ML work.
Let me show you what building ATO detection features typically looks like, and how a feature platform lets you skip these steps, and get straight to testing signals.
Taking the Stairs : Data Engineering for ATO
To build effective ATO detection, we really only need a few key building blocks:
- Time-windowed aggregations: We’ll want to look at login attempts across a broad range of time windows like the last 1 minute, 10 minutes, 24 hours, and 30 days.
- Streaming computations: We’ll need to calculate an ongoing failure rate in near-realtime as events arrive in our detection system.
- Cross-stream joins: We need a way to combine a stream of live login attempts with historical behavior patterns, so that we can look at unusual signals
- Point-in-time correctness: Model accuracy will be supremely important, so we need training data that isn’t leaking future information
- Real-time serving: Sub-100ms online feature retrieval so we can score risk within acceptable wait times for a login use case
With this modest set of tools, we can build a robust ATO detection system. Unfortunately, each of these requirements easily represents a complex data engineering project:
DIY – Requires a lot of Engineering
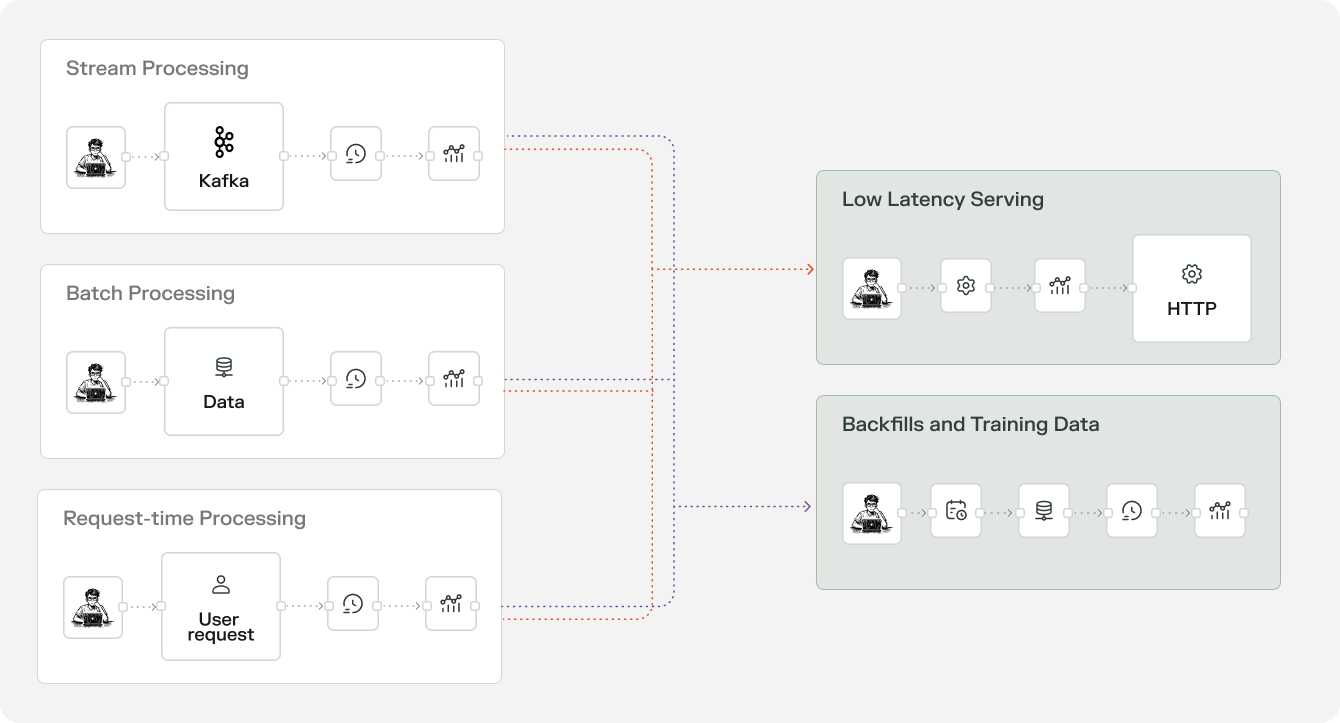
For time-windowed aggregations, you’d need to build Kafka consumers that process every login event in real-time, parsing JSON messages and updating online store counters for multiple time windows simultaneously. Each event requires updating separate counters for 1-minute, 10-minute, and 24-hour windows, with proper expiration times set for each key. Failed login events need additional counter updates, and you’d need to handle online store connection failures, ensure exactly-once processing, and manage memory usage as counters accumulate.
For batch features, you’d schedule daily batch jobs that scan entire login event tables, computing aggregations for every user. These jobs need to handle late-arriving data, manage compute resources efficiently, and write results to your feature storage system. You’d need separate processes to backfill historical data, handle schema changes, and ensure the batch job doesn’t conflict with real-time updates.
For historical backfills, you’d create separate logic from your production features to achieve point-in-time correctness. Your production streaming features compute “login attempts in the last 10 minutes” by looking at current time, but for training data, you need to compute “login attempts in the 10 minutes before each historical event” – which requires entirely different code. This means maintaining two codebases that should produce identical results but are implemented differently, adding risk of training-serving skew.
You’d need to build complex backfill jobs that simulate the aggregations that would have been computed at that time. This involves scanning historical data with sliding time windows, ensuring no future data leaks into past computations, and coordinating the timing between different feature types. The slightest bug in this separate backfill logic means your training data doesn’t match your production features, leading to models that perform well in training but fail in production. Many teams spend months debugging mysterious model performance issues that ultimately trace back to subtle inconsistencies between their backfill and production feature logic.
For real-time serving, you’d build a service that queries multiple storage systems simultaneously – your online store for streaming features, your database for batch features, and potentially other systems for user profiles. In order to maintain the freshness you need for ATO detection this can’t be as simple as just querying a fast KV store – you’ll need to compute windowed aggregations on the fly, and implement a partial aggregation strategy to minimize read penalties. The service needs to handle missing data gracefully, implement caching strategies, compute derived features on-the-fly (like time since last login or device fingerprinting), and combine everything into a consistent feature vector. All of this while maintaining sub-100ms latency and handling thousands of requests per second.
This approach requires you to manage:
- Multiple storage systems (e.g. Kafka, online stores, databases)
- Complex orchestration (e.g. Airflow for batch jobs, Kubernetes for services)
- Data consistency management (e.g. handling late-arriving events, exactly-once processing)
- Monitoring and alerting for each component
- Point-in-time correctness implementation for training data
Most teams spend 6-12 months just getting the infrastructure right, before getting changes into production.
Taking the Escalator : Feature Engineering with a Platform
Now let me show you how the same ATO detection features look with a modern feature platform like Tecton.
Streaming Features: Just Describe What You Want
@stream_feature_view(
source=login_stream, # hook it up to kafka, kinesis or direct ingest
entities=[user], # track feature values by user
features=[
# Login attempt counts across multiple time windows
Aggregate(name="login_attempts_1min", function="count",
input_column=Field("ip_address", String),
time_window=timedelta(minutes=1)),
Aggregate(name="login_attempts_10min", function="count",
input_column=Field("ip_address", String),
time_window=timedelta(minutes=10)),
Aggregate(name="login_attempts_24h", function="count",
input_column=Field("ip_address", String),
time_window=timedelta(hours=24)),
# Failed login counts
Aggregate(name="login_failures_1min", function="sum",
input_column=Field("failed", Float64),
time_window=timedelta(minutes=1)),
Aggregate(name="login_failures_10min", function="sum",
input_column=Field("failed", Float64),
time_window=timedelta(minutes=10)),
Aggregate(name="login_failures_24h", function="sum",
input_column=Field("failed", Float64),
time_window=timedelta(hours=24)),
],
online=True, # Serve in real-time
offline=True, # Store the history of feature values for training
)
def login_stats(login_stream):
# Raw data transformations
login_stream["failed"] = np.where(login_stream["login_success"], 0, 1)
return login_stream[["user_id", "timestamp", "ip_address", "failed"]]That’s it. You’ve just defined streaming features across multiple time windows with automatic:
- Stream processing infrastructure
- Real-time aggregation computation
- Online feature serving
- Offline feature retrieval for training
- Stream’s sink used for consistent backfill
- Point-in-time correctness
Batch features are just as easy, because they use the same feature definition language.
Real-time Features: Complex Logic, Simple Code
Using a centralized feature platform means you have access to all pre-calculated features when calculating new features on the fly. Streaming and batch features like login_stats and user_device_fingerprints are readily accessible in simple python code and they’re combined with the current request data login_request to produce new features using python:
@realtime_feature_view(
sources=[
login_request, # request time parameters
login_stats, # precalculated streaming features
user_device_fingerprints # precalculated batch features
],
features=[
Attribute("time_since_login_success", Float64),
Attribute("is_new_device", Int64),
],
)
def login_request_features( login_request,
login_stats,
user_device_fingerprints):
# use python/pandas code for real-time features
result = pd.DataFrame()
result["time_since_login_success"] = (
pd.to_datetime("today") - login_stats["last_success_timestamp"]
).dt.total_seconds() / 24 / 3600
# Detect new devices using fingerprinting
login_request["device_fingerprint"] = (
login_request[["browser_name_version",
"os_name_version",
"user_agent_string"]]
.apply(lambda x: create_device_fingerprint(x), axis=1)
)
result["is_new_device"] = np.where(
login_request["device_fingerprint"] in
user_device_fingerprints["known_device_fingerprints"],
1, 0
)
return result[["time_since_login_success", "is_new_device"]]Training Data: Point-in-Time Correctness Automatically
Given that historical backfills are created and managed for you, obtaining consistent training data is straightforward. The following code uses a feature service ato_feature_service which joins features from multiple streaming, batch and real-time feature views to enhance a set of labeled_events to be used for training:
# Load your labeled events
labeled_events = pd.read_csv("login_attempts_with_labels.csv")
# Get time-consistent training dataframe
training_data = ato_feature_service.get_features_for_events(labeled_events)
# That's it - no data leakage with automatically aligned timestamps
The resulting dataframe can be instantiated as a Pandas or Spark dataframe for use in training, testing, and validating your machine learning models.
Production Serving: Low Latency Feature Retrieval
Feature services are accessed through a REST API on the Tecton platform that provides auto-scaling and workload isolation to deliver low latency retrieval at up to 100k QPS.
# Real-time feature serving in production
response = client.get_features(
feature_service_name="ato_feature_service",
join_key_map={"user_id": "1081032094316532815"},
request_context_map={
"user_id": "1081032094316532815",
"ip_address": "10.1.17.196",
"user_agent_string": "Mozilla/5.0 (iPod; CPU iPhone OS 6_1_6...)",
"browser_name_version": "Mobile Safari 6.0.0.3605",
"os_name_version": "iOS 6.1.6",
"device_type": "mobile"
}
)
# Returns feature vector in ~50ms:
# [12.0, 45.0, 156.0, 2.0, 8.0, 23.0, 2.5, 1.0, 0.12, 0.33]
The Power of Abstraction
Notice what’s happening here. In the DIY approach, you’re thinking about:
- Infrastructure (Kafka, Redis, databases)
- Data pipelines (stream processing, batch jobs)
- Consistency (exactly-once processing, late events)
- Operations (monitoring, scaling, debugging)
With a feature platform, you’re thinking about:
- Feature logic (what aggregations do I need?)
- Business requirements (what time windows matter?)
- ML problems (what signals indicate account takeover?)
The platform handles everything else automatically.
Adding External APIs
Let’s say you want to add IP reputation scoring or identity verification using an external service.
Manual Approach
Building a new IP reputation service requires creating an entirely new microservice that manages SageMaker endpoint connections, handles authentication, implements retry logic, and provides its own monitoring and alerting. You’d then need to update your existing feature serving infrastructure to call this new service, handle potential failures gracefully, and manage the additional latency it introduces.
The training pipeline requires completely separate work – you’d need to backfill IP reputation scores for historical data, ensure the training and serving feature schemas stay synchronized, and update your model training code to handle the new features. You’d also need to deploy the new microservice, update load balancers, configure monitoring dashboards, and coordinate the rollout across multiple environments.
This entire process typically takes weeks of work across multiple teams – backend engineers for the new service, data engineers for the training pipeline updates, and DevOps engineers for deployment and monitoring.
Platform Approach with Tecton
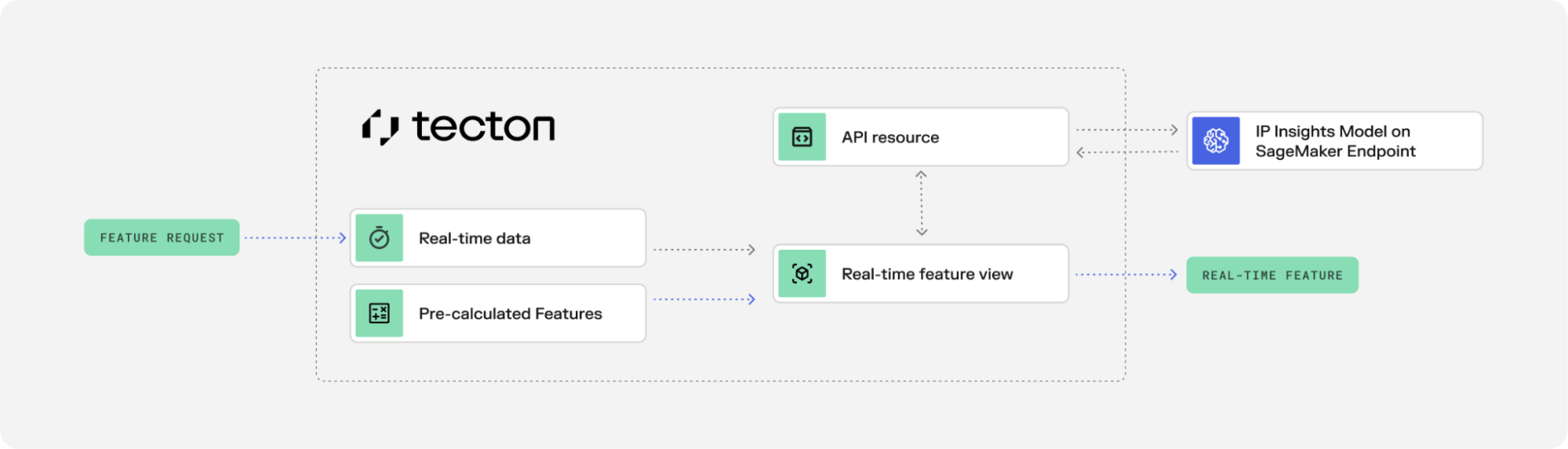
1. Define resource provider for external service:
@resource_provider(
name="ip_insights_predictor",
def ip_insights_predictor(context):
import sagemaker
from sagemaker.predictor import Predictor
endpoint_name = "ipinsights-pretrained-model"
predictor = Predictor( endpoint_name=endpoint_name,
sagemaker_session=sagemaker.Session()
)
return predictorTecton resource providers enable secure and performant access to external APIs. The provider is instantiated once to avoid connection overhead.
2. Create real-time feature using the external resource:
@realtime_feature_view(
sources=[login_request],
features=[
Attribute("ipinsights_score", Float64)
],
resource_providers={"ipinsights": ip_insights_predictor}
)
def realtime_ipinsights_score(login_request, context):
predictor = context.resources["ipinsights"]
model_inputs = [(login_request["user_id"],login_request["ip_address"])]
response = predictor.predict(model_inputs)
ipinsights_score = response["predictions"][0]["dot_product"]
return {
"ipinsights_score": ipinsights_score,
}3. Create a variant of the feature service that includes the new feature view:
ato_detection_inference_service_V2 = FeatureService(
name="ato_feature_service:2_0",
# features to include in service
features=[
login_baseline,
login_stats,
login_request_features,
realtime_ipinsights_score # new feature view
],
)
Using a different version (variant) of the feature service allows continuity of feature serving on the existing service. This allows you to train, test and validate new models using the augmented feature set without disrupting existing models already in production.
4. Deploy changes to the platform using tecton apply command:
> tecton apply
Using workspace "sergio-demo" on cluster https://community.tecton.ai
🌏 Processing feature repository module features.realtime_ipinsights_scoreVersion: 1.2.0b15
Git Commit: fb46e70e7e1a7228144f6f5ca5d57ff94193a8bd
Build Datetime: 2025-05-13T21:19:49
✅ Imported 13 Python modules from the feature repository
✅ Imported 13 Python modules from the feature repository
⚠️ Running Tests: No tests found.
✅ Collecting local feature declarations
✅ Performing server-side feature validation: Initializing.
↓↓↓↓↓↓↓↓↓↓↓↓ Plan Start ↓↓↓↓↓↓↓↓↓↓
+ Create Transformation
name: realtime_ipinsights_score
+ Create Realtime (On-Demand) Feature View
name: realtime_ipinsights_score
+ Create Feature Service
name: ato_detection_inference_service:2_0
↑↑↑↑↑↑↑↑↑↑↑↑ Plan End ↑↑↑↑↑↑↑↑↑↑↑↑
Generated plan ID is 0e915e353f7d4b059c7b7db8f3f29ee3
View your plan in the Web UI: https://community.tecton.ai/app/sergio-demo/plan-summary/0e915e353f7d4b059c7b7db8f3f29ee3
Note: Updates to Feature Services may take up to 60 seconds to be propagated to the real-time feature-serving endpoint.
Are you sure you want to apply this plan to: "sergio-demo"? [y/N]> y
🎉 Done! Applied changes to 3 objects in workspace "sergio-demo".Time to production: 5 minutes instead of 5 weeks or more.
The Bottom Line
Feature engineering for ATO detection is inherently complex because the problem is complex. You need sophisticated features across multiple data sources and time windows.
But that complexity should live in your feature logic, not your infrastructure.
When you abstract away the data engineering, you can focus on what actually matters:
- Faster iteration on detection algorithms
- More sophisticated features without infrastructure overhead
- Better models because you can experiment more and know that training and serving features are consistent
- Shorter time-to-market for new fraud detection capabilities
The companies winning at ATO detection aren’t necessarily the ones with the best data engineers – they’re the ones whose data scientists can move fastest from idea to production.
Modern feature platforms like Tecton make that possible by turning months of data engineering into minutes of feature engineering.
Want to see this in action? Explore Tecton on your own or browse our tutorials


