A feature store is a data platform that makes it easy to build, deploy, and use features for machine learning.
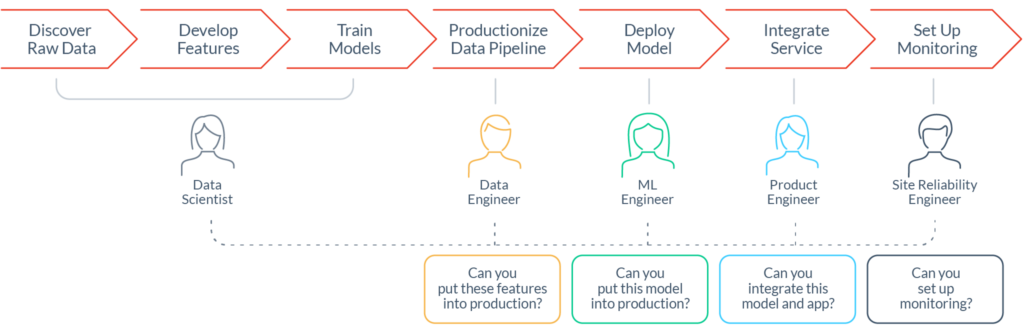
Data scientists don’t have the tooling required to easily deploy ML models and data to production. Instead, they rely on other teams to get them over the finish line. These dependencies often result in long lead-times of 6-12 months to deploy new models.
- Prof. Andrew Ng
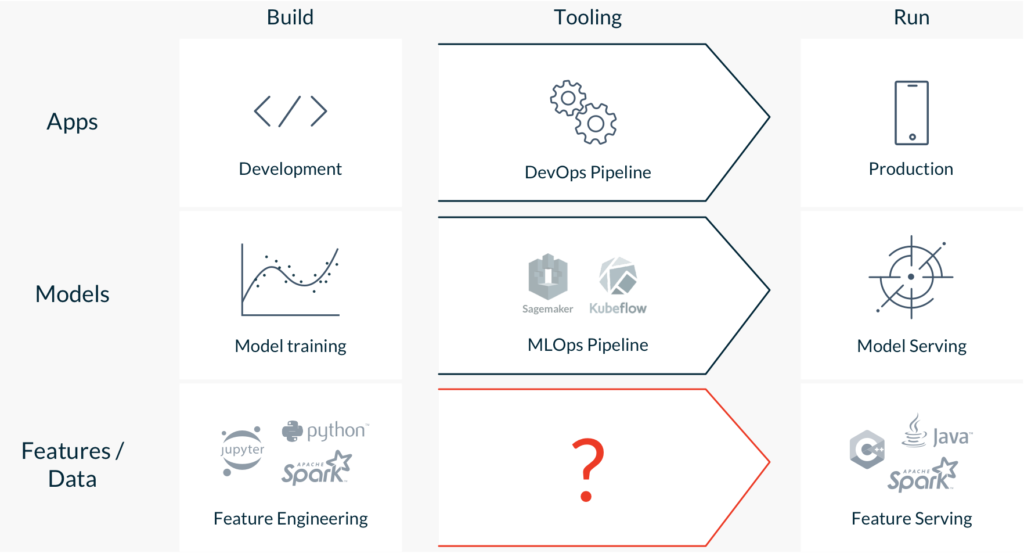
Operational ML requires deploying applications, models and features to production. We have great DevOps tooling to build applications, and emerging MLOps platforms to train, validate and deploy models. But when it comes to features – the predictive data signals that are the lifeblood of ML systems – we lack the tooling required to build and deploy them to production.
Data scientists engineer new features in interactive notebooks, using code that is not production-ready. So they pass their feature transformations to data engineers to re-implement the feature pipelines with production-hardened code. This process increases complexity, lead time, implementation costs, and can increase the risk of training/serving skew.
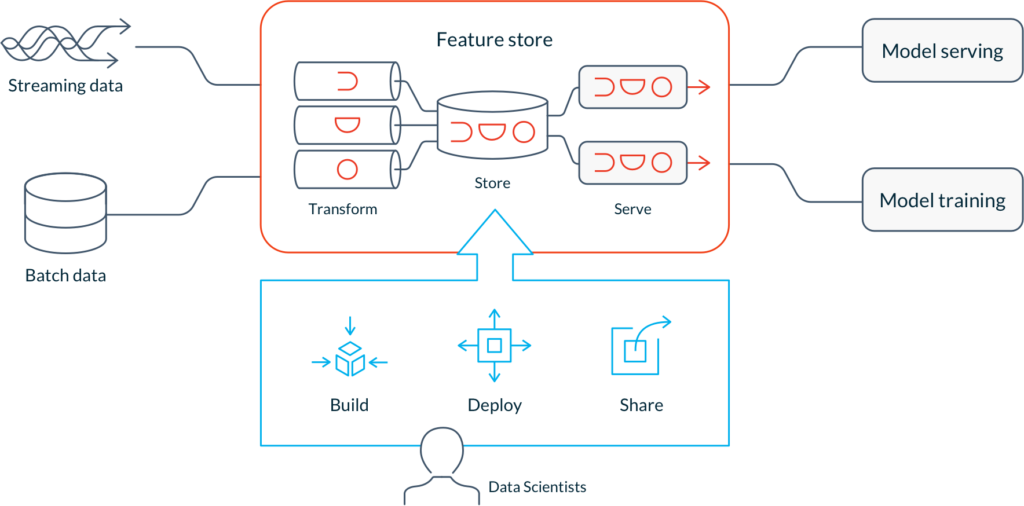
Feature stores are central hubs for the data processes that power operational ML models. They transform raw data into feature values, store the values, and serve them for model training and online predictions. By automating these steps, feature stores allow data scientists to build and deploy features within hours instead of months.
Build a library of features collaboratively using standard feature definitions.
Deploy features to production instantly using DevOps-like engineering best practices, and create training datasets that preserve training/serving parity.
Share, discover, and re-use features across your organization.
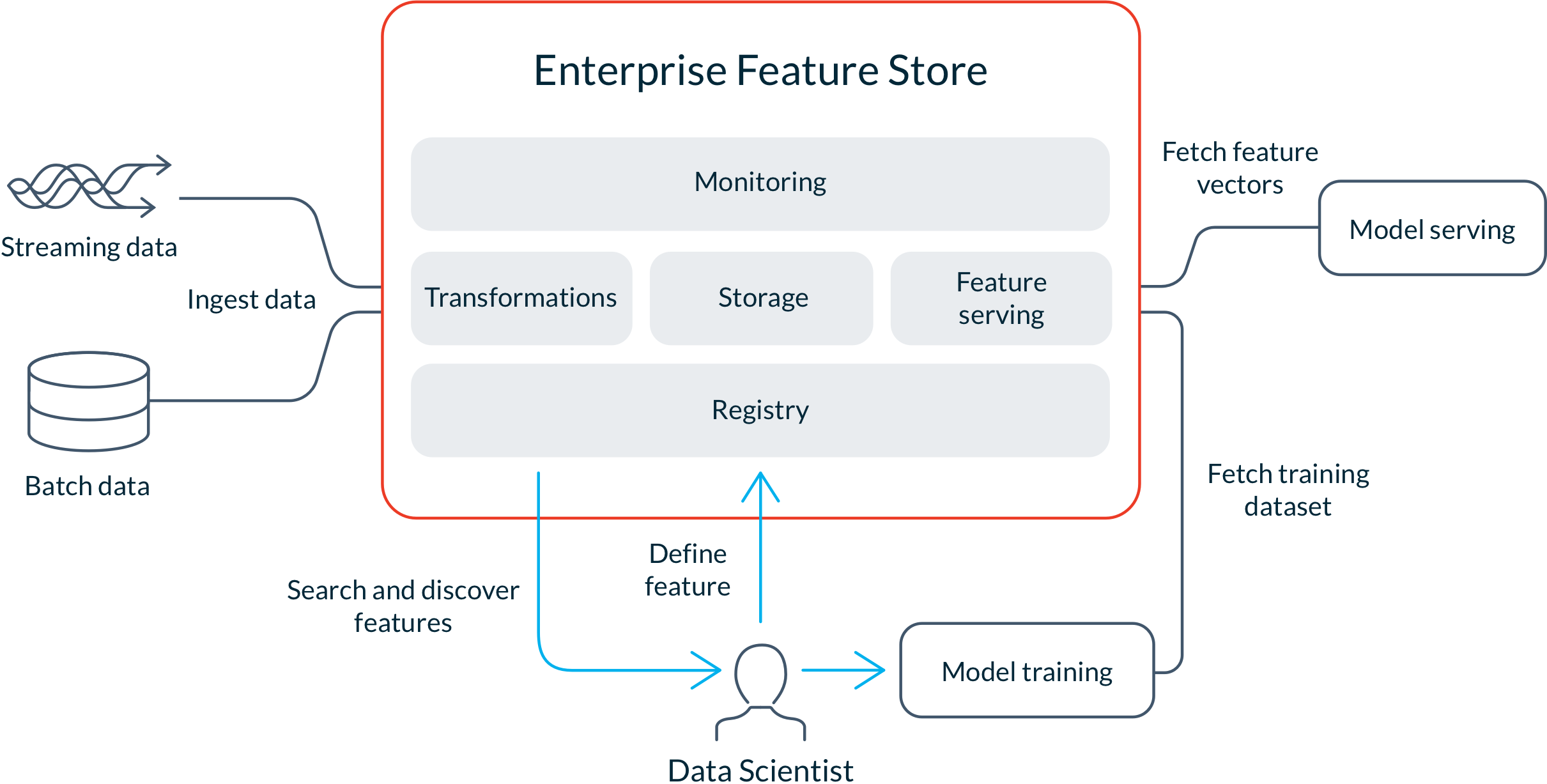
Enterprise feature stores are complete platforms that manage the end-to-end lifecycle of features. They integrate with existing data stores, feature pipelines, and ML platforms like Amazon SageMaker and Kubeflow to augment the infrastructure with feature management capabilities.
The key components of a feature store include:
Feature values are organized in feature storage. Feature stores provide both online storage for low-latency retrieval, and offline storage to curate historical data sets.
Interested in trying Tecton? Leave us your information below and we’ll be in touch.
Unfortunately, Tecton does not currently support these clouds. We’ll make sure to let you know when this changes!
However, we are currently looking to interview members of the machine learning community to learn more about current trends.
If you’d like to participate, please book a 30-min slot with us here and we’ll send you a $50 amazon gift card in appreciation for your time after the interview.
or
Unfortunately, Tecton does not currently support these clouds. We’ll make sure to let you know when this changes!
However, we are currently looking to interview members of the machine learning community to learn more about current trends.
If you’d like to participate, please book a 30-min slot with us here and we’ll send you a $50 amazon gift card in appreciation for your time after the interview.
or
Interested in trying Tecton? Leave us your information below and we’ll be in touch.
Unfortunately, Tecton does not currently support these clouds. We’ll make sure to let you know when this changes!
However, we are currently looking to interview members of the machine learning community to learn more about current trends.
If you’d like to participate, please book a 30-min slot with us here and we’ll send you a $50 amazon gift card in appreciation for your time after the interview.
or