Tecton’s Feature Store provides a single pane of glass for all of your ML features. Visualize and manage ML features across all models and AI applications. Eliminate rogue pipelines and prevent feature sprawl, ensuring an organized feature environment that reduces redundancy.
Share features across teams
Facilitate collaboration with feature reuse capabilities. Discover existing features, identify and remove duplicates, and share across teams. Accelerate development cycles, reduce costs, and maintain consistency across ML projects. Control feature access and usage with granular permissions.
Track feature evolution with built-in versioning
Track feature definition changes over time with end-to-end lineage. View feature evolution, prevent unintended modifications, and maintain a clear development history. Tecton proactively evaluates the impact of any changes, allowing experimentation while maintaining production feature integrity.
Ensure data security with enterprise-grade protections
Protect sensitive data with Tecton’s security features. These enterprise-grade security measures ensure that features and data remain protected while enabling streamlined collaboration. Our Feature Store comes equipped with:
SAML 2.0 for secure authentication
Role-Based Access Control (RBAC)
SOC 2 Type II & ISO 27001
End-to-end encryption
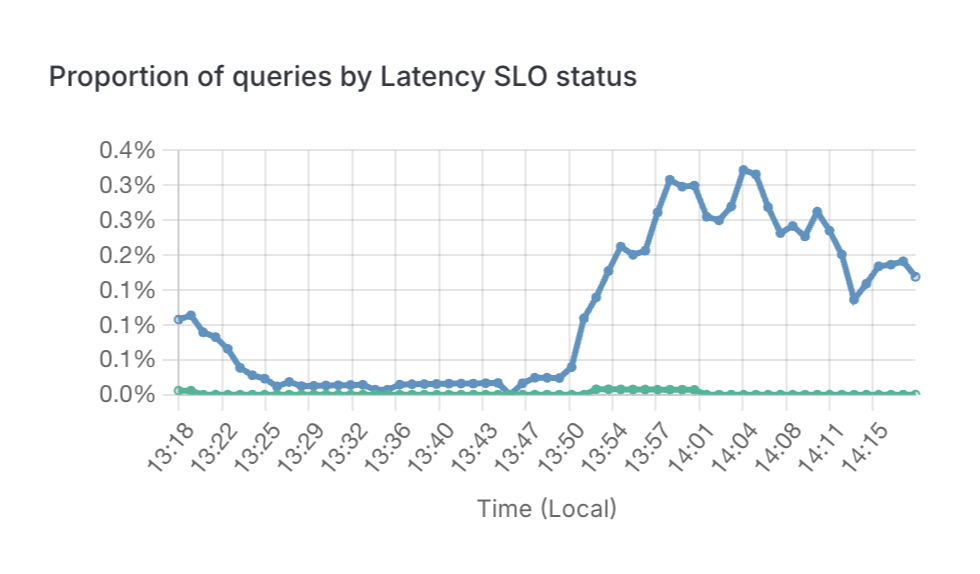
Monitor operational health in real-time
Keep your finger on the pulse of your feature infrastructure with Tecton’s operational monitoring. Track feature health, data freshness, quality metrics, and serving latencies in real time. This proactive approach allows you to identify and address issues before they impact your models, ensuring the reliability and performance of your ML applications.
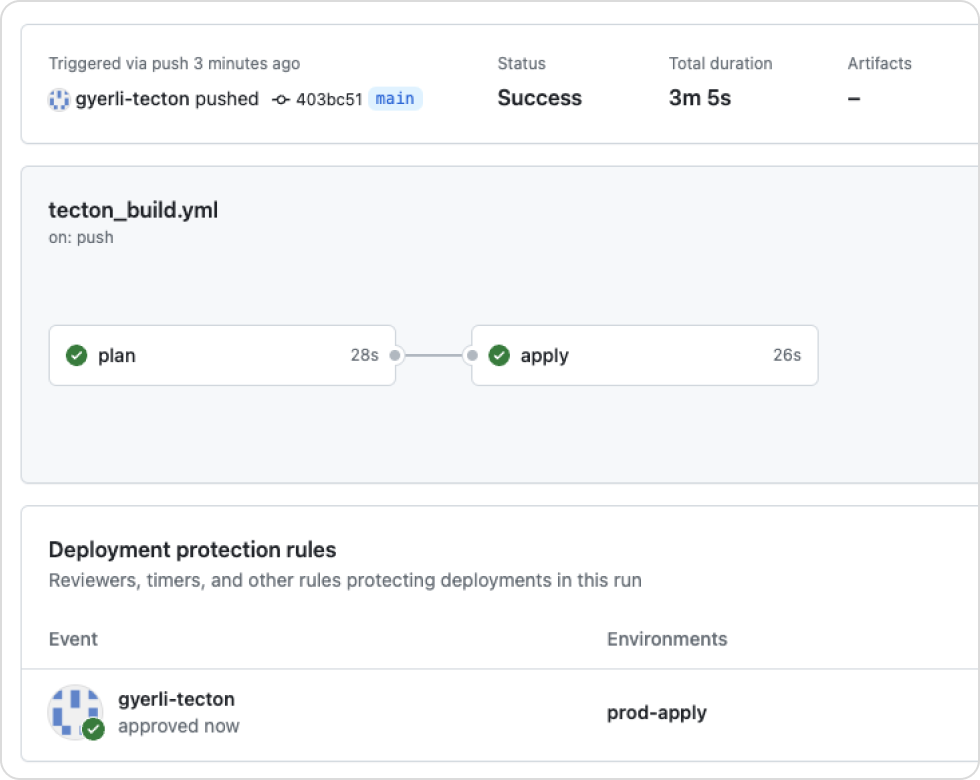
Move from development to production safely and quickly
Manage feature definitions as code. Use version control, PR reviews, and CI/CD tools like GitHub Actions to automate feature deployment pipelines. Improve collaboration between data scientists and engineers for smooth transitions from development to production.
Unfortunately, Tecton does not currently support these clouds. We’ll make sure to let you know when this changes!
However, we are currently looking to interview members of the machine learning community to learn more about current trends.
If you’d like to participate, please book a 30-min slot with us here and we’ll send you a $50 amazon gift card in appreciation for your time after the interview.
Interested in trying Tecton? Leave us your information below and we’ll be in touch.
Unfortunately, Tecton does not currently support these clouds. We’ll make sure to let you know when this changes!
However, we are currently looking to interview members of the machine learning community to learn more about current trends.
If you’d like to participate, please book a 30-min slot with us here and we’ll send you a $50 amazon gift card in appreciation for your time after the interview.
Interested in trying Tecton? Leave us your information below and we’ll be in touch.
Unfortunately, Tecton does not currently support these clouds. We’ll make sure to let you know when this changes!
However, we are currently looking to interview members of the machine learning community to learn more about current trends.
If you’d like to participate, please book a 30-min slot with us here and we’ll send you a $50 amazon gift card in appreciation for your time after the interview.
 Predictive ML
Predictive ML