Proactive Drift and Data Quality Monitoring for Tecton Feature Views with Fiddler





Learn how to leverage Fiddler to detect drift and data integrity issues directly against your Tecton Feature Views.
Tecton’s Feature Store transforms raw data into machine learning features through real-time, streaming and batch data pipelines. These features are vital for many models that drive core business operations. If data quality issues or drift occur in these features, multiple models downstream can be affected.
In our previous installment, we discussed how to use Fiddler to detect drift at the individual model level. In this post, we will detail how Fiddler can monitor Feature Views for drift and data quality issues. By doing so, MLOps teams can detect upstream issues early and protect all dependent models from downstream performance problems.
Why Monitor a Feature Store Directly?
Direct monitoring of your Feature Stores empowers your MLOps teams to proactively identify data quality and drift issues that could affect multiple models. This upstream detection of problems can prevent numerous downstream complications. The following outlines some of the key benefits that can be realized through this approach:
- Earlier Problem Detection: Feature-level issues often manifest hours or days before they impact model performance metrics. By the time model drift or accuracy degradation happen, poor predictions have already been served to users. Feature monitoring acts as an early warning system.
- Root Cause Isolation: Monitoring features directly saves time and investigation effort. If a model’s performance suddenly drops, feature-level monitoring can immediately pinpoint whether the issue stems from a specific data source, transformation pipeline, or upstream system failure, rather than requiring extensive investigation.
- Operational Efficiency: When multiple models share the same features, a single corrupted feature can affect them all. Feature monitoring makes it clear when one upstream problem is causing widespread issues.
- Business Logic Validation: Business rules can be enforced at the feature level. You might know that a “customer_age” feature should never exceed 120 or that “transaction_amount” should follow certain business rules. These constraints are easier to validate directly on features than to infer from model behavior.
- Data Integrity Health: Monitoring at the feature-level gives you visibility needed to spot data integrity issues. Data integrity problems like missing or out of range values and incorrect data types often impact feature quality before affecting model outputs, especially if models have some robustness to missing or degraded inputs.
Compliance and Governance: Some industry-specific applications, like financial or healthcare applications, may require monitoring sensitive features regardless of model performance, such as tracking data lineage and quality for regulatory purposes.
Retrieving Feature Values
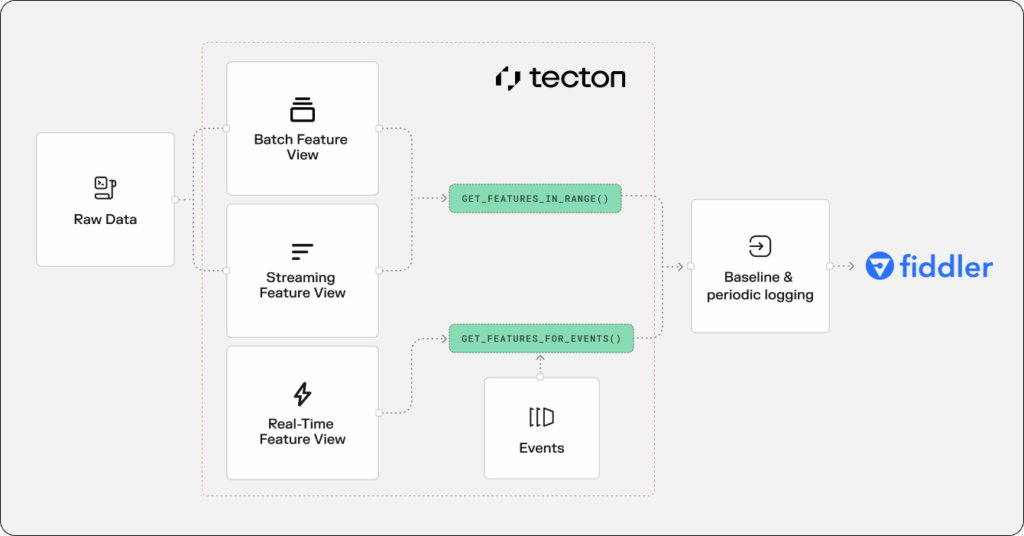
Tecton offers three types of Feature Views: streaming, batch and real-time. Each type of feature view provides different data processing and storage characteristics.
- Streaming feature views are used for event processing and store pre-calculated features for online/offline retrieval. Online values will be available as soon as the streaming events are processed. The offline store is updated periodically (usually daily).
- Batch feature views are used for periodic batch processing and they store pre-calculated features for online/offline retrieval. Both the online and offline stores are populated upon batch execution.
- Real-time feature views define request time transformations. These pipelines allow users to combine feature values from other streaming and batch pipelines along with request time parameters to calculate features at the time of the request. Feature values are not stored in either online or offline stores.
Since batch and streaming Feature Views populate the offline store and backfill history, you can use Tecton’s get_features_in_range method to retrieve a feature dataframe from any time period to then publish them on Fiddler for baseline setup or daily logging.
For real-time Feature Views that don’t store pre-calculated values, you can still create historical baselines in Fiddler. Use the get_feature_for_events method to calculate feature values for your past triggering events.
For example, if your features feed a fraud detection model that processes payment transactions, you can take your transaction history and use each transaction as an event to calculate what the real-time feature values would have been at that moment. The resulting dataframe can be used to publish on Fiddler.
Monitoring Feature Views in Fiddler
In the initial installment of this blog series, we demonstrated how Fiddler could detect drift for binary classification models. Specifying the model’s task is crucial, as it enables Fiddler to provide the pertinent ML performance metrics (e.g. accuracy, F1, precision, AUC, etc).
However, when we aim to monitor our Feature Views before they reach our models, a different task type is necessary, specifically one designed for scenarios focusing solely on “inputs.” In such cases, there are no model predictions or actual outcomes to consider. Fiddler’s fdl.ModelTask.NOT_SET model task type is specifically intended for this type of monitoring.
We need to retrieve a deployed feature view from the Tecton platform so that we can easily define its corresponding Fiddler model and retrieve feature data for logging:
# access a tecton workspace
ws = tecton.get_workspace("prod")
# retrieve a deployed feature view
user_transaction_metrics = ws.get_feature_view("user_transaction_metrics")
# retrieve a baseline dataset from the feature view. This will serve as historical feature values and our point of reference for detecting change.
end = datetime.now().replace(hour=0, minute=0, second=0)
start = end - timedelta(days=60)
history_df = user_transaction_metrics.get_features_in_range(
start_time=start,
end_time=end
).to_pandas()
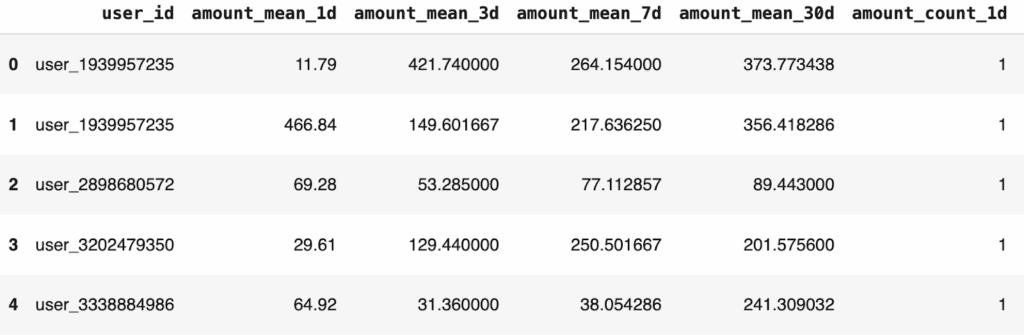
history_df.sample(5)Output:
On the Fiddler side, we first define our model_spec to specify inputs and metadata. Note there is no specification of model outputs or targets in our model_spec object. The input columns come from the feature view’s feature list and we map Tecton’s entity identifiers as Fiddler metadata columns:
# map FV features to Fiddler input columns
input_columns = user_transaction_metrics.get_feature_columns()
# map entity join_keys to Fiddler metadata columns
entity_cols = [col for y in user_txn_recent_activity.entities for col in y.join_keys ]
model_spec = fdl.ModelSpec(
inputs=input_columns,
metadata=entity_cols,
)
We then ask Fiddler to create a model definition with model type set to fdl.ModelTask.NOT_SET which relaxes the need to monitor outputs, targets and task specific performance metrics.
# get or create the project in Fiddler
project = fdl.Project.get_or_create( name="tecton_integration" )
# define the model
fdl_model = fdl.Model.from_data(
name = "dqm_usr_txn_metrics",
version = "v1.0",
project_id = project.id,
source = history_df, # source dataframe used to infer schema
spec = model_spec,
task = fdl.ModelTask.NOT_SET, # type of model NOT_SET <= there is no model
event_ts_col = "_valid_from", # use Tecton's start of applicability
)
# register new model on Fiddler
fdl_model.create()
print(f'New model created with id = {fdl_model.id} and name = {fdl_model.name}')
The history_df dataframe acquired from Tecton is used in the source parameter to define the data schema for the model. We now need to publish the baseline as a point of reference for calculating drift and data quality issues.
# publish the feature value history dataset as production data
history_publish_job = fdl_model.publish(
source=history_df,
environment=fdl.EnvType.PRODUCTION,
)
# wait for publish to complete
history_publish_job.wait()Use Historical Feature Values to Track Drift
Baselines in Fiddler are essential for several key functions related to the monitoring of machine learning models. Primarily, they serve as a point of reference so Fiddler can understand what “expected” data distributions look like when calculating drift or data anomalies.
Fiddler typically establishes a baseline using the model’s training data. However, when monitoring Feature Views, there is no applicable concept of a model nor its training data. Thus, we must look at values from these Feature Views in the past and use that as our baseline.
In this scenario, it is best to define a “rolling baseline” which references feature values at a point in the past. By comparing current values from our Feature Views to a point in the past, we can detect when new data is diverging from what data distributions were witnessed historically.
# setup rolling baseline for feature view monitoring one month ending one month ago
fdl_model = fdl.Model.from_name(name="dqm_usr_txn_metrics", version="v1.0", project_id=project.id)
rolling_prod_baseline = fdl.Baseline(
name='rolling_usr_recent_activity',
model_id=fdl_model.id,
environment=fdl.EnvType.PRODUCTION,
type_=fdl.BaselineType.ROLLING,
window_bin_size=fdl.WindowBinSize.MONTH,
offset_delta=2,
)
rolling_prod_baseline.create()In the example above, we create a rolling baseline of one month worth of data (fdl.WindowBinSize.MONTH) that references feature values published into Fiddler two months ago (offset_delta).
Publishing Ongoing Production Feature Values
Now we simply need to publish values into Fiddler at the appropriate cadence for our feature views. A scheduled daily incremental script might look something like this:
# retrieve yesterday's feature values from the feature view
end = datetime.now().replace(hour=0, minute=0, second=0)
start = end - timedelta(days=1)
incremental_df = user_transaction_metrics.get_features_in_range(
start_time=start,
end_time=end
).to_pandas()
# retrieve Fiddler project and model
project = fdl.Project.get_or_create( name="tecton_integration" )
fdl_model = fdl.Model.from_name(name="dqm_usr_txn_metrics", project_id=project.id, version="v1.0")
# publish incremental data
incremental_publish_job = fdl_model.publish(
source=incremental_df,
environment=fdl.EnvType.PRODUCTION,
)
print(
f'Incremental feature view data with Job ID = {incremental_publish_job.id}')Drift and Data Integrity Insights in Fiddler
Using the approach outlined above, the following chart illustrates how Fiddler can provide early detection of data issues in our Tecton Feature Views. Specifically, the chart below identifies a concerning trend related to drift on our “amount_mean_30d” feature as compared to our “rolling_usr_recent_activity” baseline. Furthermore, by setting alert rules, we can expect Fiddler to proactively send us alert notifications automatically when these concerning conditions appear.

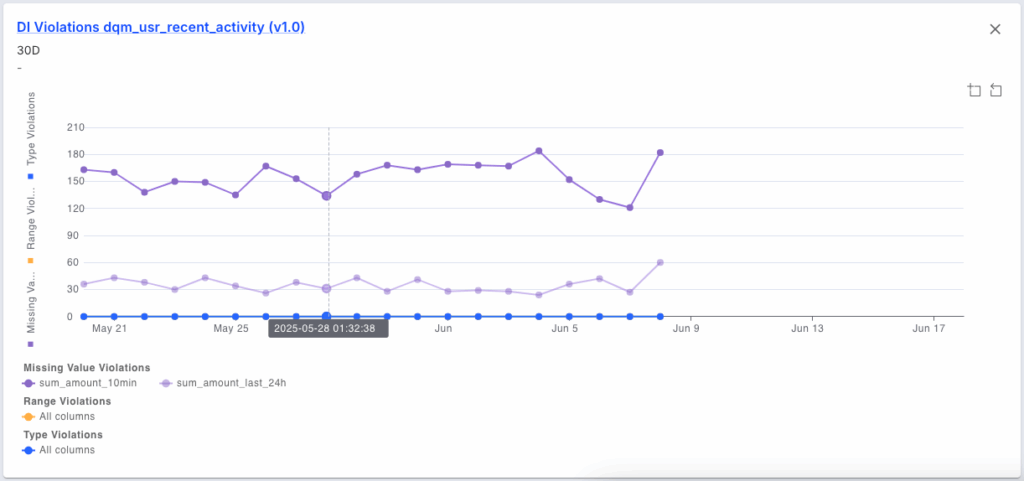
In addition to monitoring data drift in our Feature Views, we can also look at data integrity issues like missing values, range violations and data type mismatches. The chart below identifies some missing values for our “sum_amount_last_24h” and “sum_amount_10min” features.
Conclusion: Building Resilience Into Your ML Pipelines with Proactive Feature Monitoring
Monitoring your Tecton Feature Views directly with Fiddler creates a powerful early warning system for your ML operations. By detecting drift and data quality issues at the feature level, you can identify problems before they cascade into multiple downstream models and impact business outcomes.
The approach we've outlined - monitoring feature values only using Fiddler's NOT_SET model task with rolling baselines - gives you the visibility needed to maintain healthy feature pipelines. Whether you're working with streaming, batch, or real-time feature views, you can now catch data anomalies, schema changes, and distribution shifts as they happen rather than reacting only after model performance degrades.
With this proactive monitoring strategy, MLOps teams shift from a reactive, defensive stance to true prevention before they reach production. The result is more reliable ML systems, faster incident resolution, and greater confidence in your feature store operations.
Ready to take the next step? Start by implementing feature-level monitoring for your most critical Feature Views, and experience firsthand the benefits of upstream drift detection.