Amazon SageMaker & Tecton: How to Choose the Right Feature Store on AWS


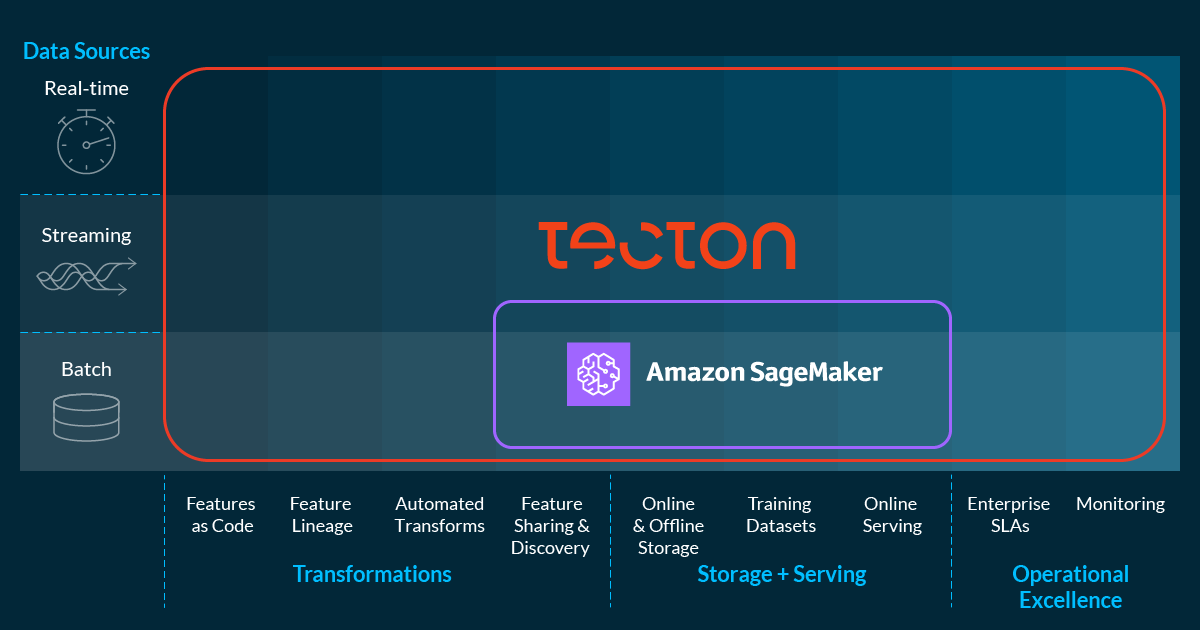
Amazon recently introduced the SageMaker feature store, recognizing that one of the largest challenges facing data science teams is building and serving high-quality machine learning features both in training and in production. We at Tecton couldn’t agree more with the problem statement presented by AWS. Our objective is to make feature stores available to every organization to solve this problem at scale. And we’re excited to see the product category grow and evolve.
For all their promise, feature stores have only recently become available as commercial or open source products. Tecton was introduced early this year and Feast, the leading open source feature store, was first introduced in early 2019. There’s still a lot of inconsistency in the way feature stores are defined across organizations. Our team has spent the last two years thinking about exactly what capabilities are needed from a complete feature store. In this post we’ll explore SageMaker Feature Store to understand what capabilities it has, and how it compares to Tecton.
What is the value of a feature store for machine learning teams?
The objective of a complete feature store is to deliver integrated, end-to-end management of features that can use a wide variety of data sources. Breaking it down further, a feature store should allow ML teams to:
- Maximize the utility of all of your data assets. Any data available when you’re building a model should be easy to use in training and just as easy to use in production.
- Make data scientists self-sufficient. Data scientists should be able to explore data, build features, retrieve training datasets, and promote features to production without the assistance of an engineering team.
- Provide easy-to-access and accurate historical data. Combining disparate data sources, in particular data sources with different records of time, is challenging but doing it well unlocks incredibly powerful models.
- Improve collaboration on features. Data scientists don’t need to work in silos anymore since they can easily share the features they’ve built and discover the features developed by other data scientists.
- Ensure high performance, especially in serving. Your ML models are incredibly valuable, and you should never have to worry about if your models will fail because your data wasn’t available fast enough.
- Enable effective governance. Managing data assets, especially as they are transformed and moved around, is an incredibly challenging task for most organizations. A feature store should only make this task easier, by providing a clear lineage of how data is being transformed, and where it is being used.
Comparison of the Tecton and Amazon feature stores
Feature stores are an emerging product category, and there’s still a lot of variation in the scope of their capabilities. At Tecton, we believe that feature stores should manage the end-to-end lifecycle of features that are built using batch, streaming, and real-time data sources. By building a solution that considers where data comes from, and how it gets managed, transformed, and used, we’re able to address these major concerns. Here’s how we view the feature lifecycle, and how the capabilities of the Tecton feature store compare to AWS SageMaker feature store.

Choosing the right feature store for your ML team
Given the stark differences in capabilities between the Tecton and SageMaker feature stores, let’s compare how well they can deliver on the goals laid out in the first section and get us closer to the desired end-state.
Goal 1: Maximize the utility of all of your data assets (batch, streaming and real-time)
The best ML models incorporate every relevant feature—not just the ones you can easily access and use. Some models aren’t even feasible without real-time data! Back at Uber one of the more influential models provided real-time ETA estimates for rides—without fresh traffic data these models would not have been possible.
Unfortunately for a lot of data scientists, the reality is that integrating data derived from streaming data sources or real-time data sources is extremely challenging. Ideally, a feature store would provide an abstraction that allows a data scientist to easily consume and transform data, no matter where it comes from.
| SageMaker Feature Store | Tecton |
|---|---|
| The SageMaker feature store does not provide tooling to define transformations on real-time or streaming data. In practice, this means that it will be difficult to use those sources, which will limit the quality of your models. SageMaker will make it easier for your data scientists to consume batch sources when they can reuse features built by other data scientists. | Tecton provides an easy-to-use abstraction for all of your data sources, meaning it’s just as easy to use streaming data as batch data. Furthermore, Tecton automates the transformation process, meaning that once you define transformations, Tecton automatically builds the complex pipelines needed to keep your feature store updated. |
| Key capabilities: Batch data support, online and offline storage | Key capabilities: Batch, streaming and real-time data support, online and offline storage |
Goal 2: Make data scientists self-sufficient
For many data science teams, it can take more than six months to get a new ML model running in production. This slowness is driven by the challenge of building production data pipelines, which frequently requires a data engineering team to step in and assist data scientists. Ideally, a data scientist could define the features for their model on their own, and then those features would be available for production without any further effort. With more time to focus on building models, this capability provides a huge productivity boost to data scientists.
| SageMaker Feature Store | Tecton |
|---|---|
| To build production data pipelines, data scientists need to combine three loosely integrated tools: SageMaker Pipelines, SageMaker Data Wrangler, and SageMaker Feature Store. Unfortunately these tools only support batch data sources, meaning you’ll still need data engineers and external pipelines to incorporate streaming or real-time data. | When a data scientist defines a feature, Tecton automatically builds the production data pipelines that used to take months to build. In practice, this has turned the six month process to move a model to production into a 1-2 day affair. |
| Key capabilities: Batch-only transformations, online and offline storage | Key capabilities: Automated transformations, online and offline storage |
Goal 3: Provide easy-to-access & accurate historical data
Many high-performing models need to synthesize data from a wide variety of sources. To build a fraud detection model, you’ll want data about historical user behaviour, static data about users, data about vendors, and more—and it can be incredibly difficult to fuse these sources together effectively when building your training dataset.
With some clever storage technology and approaches to joining together data, feature stores can make this challenge relatively straightforward. This approach is called time travel and allows you to join together all of your data sources, even those with different timestamp cadences. This is done by estimating exactly what data would have been in the online store at some point in the past, and then providing exactly that data when generating a training dataset.
| SageMaker Feature Store | Tecton |
|---|---|
| SageMaker does not provide a utility to join historical data from different sources. This means you’re on your own to figure out how to fuse everything—in practice, you’ll iterate more slowly or exclude data that is particularly hard to manage. | Tecton provides advanced row-level time travel, meaning that if you provide a list of times at which you want to retrieve historical values of features, we will return values of those features at those points in time. This approach makes it easy to fuse the many sources of data you need to construct high-performance models. |
| Key capabilities: None | Key capabilities: Training datasets with time travel |
Goal 4: Improve collaboration on features
As data science teams grow, more and more data scientists find themselves working in silos. This leads to a huge amount of duplicated work as data scientists all build their own versions of the same features. This duplicated work is only made worse when those models are moved to production, and without careful collaboration, those costly data pipelines will also be duplicated.
Feature stores enable simple sharing of features, meaning when one data scientist creates a feature it can easily be used by another data scientist potentially in a completely different organization.
| SageMaker Feature Store | Tecton |
|---|---|
| SageMaker allows any user to easily retrieve created features from the feature store for re-use. SageMaker Data Wrangler could then be used to analyze or explore the data. The lack of feature lineage across the two tools means it may be impossible to understand how that data was generated before you use it. | Features are shared between data scientists, and Tecton provides an easy-to-use UI that allows data scientists to browse existing features and learn about how those features were created. Further, Tecton provides straightforward tools and APIs to visualize and examine features when conducting exploratory data analysis. |
| Key capabilities: Batch-only transformations | Key capabilities: Sharing and discovery of features, feature lineage |
Goal 5: Ensure high performance, especially in serving
As ML teams mature, models find their way into more and more customer facing applications. These applications typically have particularly strict requirements for both quality and runtime, often needing to execute in real time. As these models become more and more relevant to a company’s bottom line, it becomes crucial for them to be operating at 100% at all times.
Feature stores provide a critical role in enabling real-time ML by guaranteeing fresh data is provided to models in real time. Further, feature stores can provide advanced monitoring to ensure your data quality is consistent, helping you ensure that your ML models don’t fail silently.
| SageMaker Feature Store | Tecton |
|---|---|
| SageMaker provides low-latency endpoints to retrieve data from the online feature store. This helps ensure your models can quickly retrieve data. SageMaker does not provide feature-specific SLAs or built-in monitoring capabilities. | Tecton doesn’t just provide high-performance endpoints for serving features, it also provides around-the-clock support and enterprise SLAs to ensure those features are available whenever your models need them. When you use Tecton, our engineers are on call to make sure everything is working 24/7. Further, Tecton provides an advanced monitoring suite that helps you monitor data quality, meaning you can be confident your models are working throughout their lifetime. |
| Key capabilities: Online serving | Key capabilities: Online serving, enterprise SLAs, monitoring |
Goal 6: Enable effective governance
Getting data governance right is incredibly challenging. Whether it’s privacy, auditing, data quality monitoring, or whatever is most important to your organization, you cannot afford to add tools to your data toolchain that obfuscate where data came from or how it got there.
A feature store should serve to make these concerns easier to manage. A feature store can provide a full lineage of features, to understand how they are being generated, where they are being stored, and what services are consuming features. Further, the state of the feature store should be tracked through time to ensure your understanding of your data is consistent when you need to go back in time and do analysis.
| SageMaker Feature Store | Tecton |
|---|---|
| The SageMaker feature store requires you to push externally processed data into the feature store. In this model, data can end up in your feature store with no record of how it was collected, where it came from, or where it was transformed. At any point, a feature could be overwritten with different data, which could negatively impact existing models. SageMaker doesn’t provide intelligent handling of feature versions, meaning keeping track of your features over time will be challenging. | In Tecton, features are defined as code, meaning the full history of your features can be tracked with powerful tools like Git. Tecton also provides full feature lineage, meaning you know exactly how each piece of data in your feature store ended up there. This governance capability gives organizations much more visibility into their data, making it easier to manage everything data scientists are using for ML. |
| Key capabilities: None | Key capabilities: Features as code, feature lineage |
Conclusion
Not all feature stores are made equal. To get the most out of your data assets and make your data scientists as efficient as possible, you really need end-to-end feature management. In its first version, the SageMaker feature store does not cover the entire feature lifecycle, but it does make important strides to making it easier to manage your data for ML in SageMaker.
The SageMaker feature store will most certainly improve over time, and we look forward to the AWS team starting to push the boundaries of what is possible with a feature store. We also expect more organizations to join the fray—the problem of feature management is too pressing and too important to be ignored.
For now, Tecton offers a managed feature store that enables all of your disparate data sources to come together to generate value for your business. If you’re interested in seeing what Tecton can do for your team, sign up for a free trial today.


