Why Building Real-Time Data Pipelines Is So Hard


If you’re reading about machine learning tooling, you’ll find countless articles that will tell you how real-time machine learning is hard and that most machine learning projects fail. But there are relatively few articles explaining why real-time machine learning (ML) is hard! People building ML tools sometimes take it for granted that everyone doing ML has already experienced this hardship.
At Tecton, we often write (and strongly believe!) that the hardest part of real-time machine learning is building real-time data pipelines. In this blog, I’ll focus on why it’s so hard to build real-time data pipelines for ML, what problems emerge when you try, and how you can avoid those challenges in the first place.
Why is building real-time data pipelines in machine learning so challenging?
Before we get to the challenges of building real-time data pipelines, we should start by exploring the data journey most teams take on their way to real-time machine learning. For most projects, things start off with batch feature engineering:
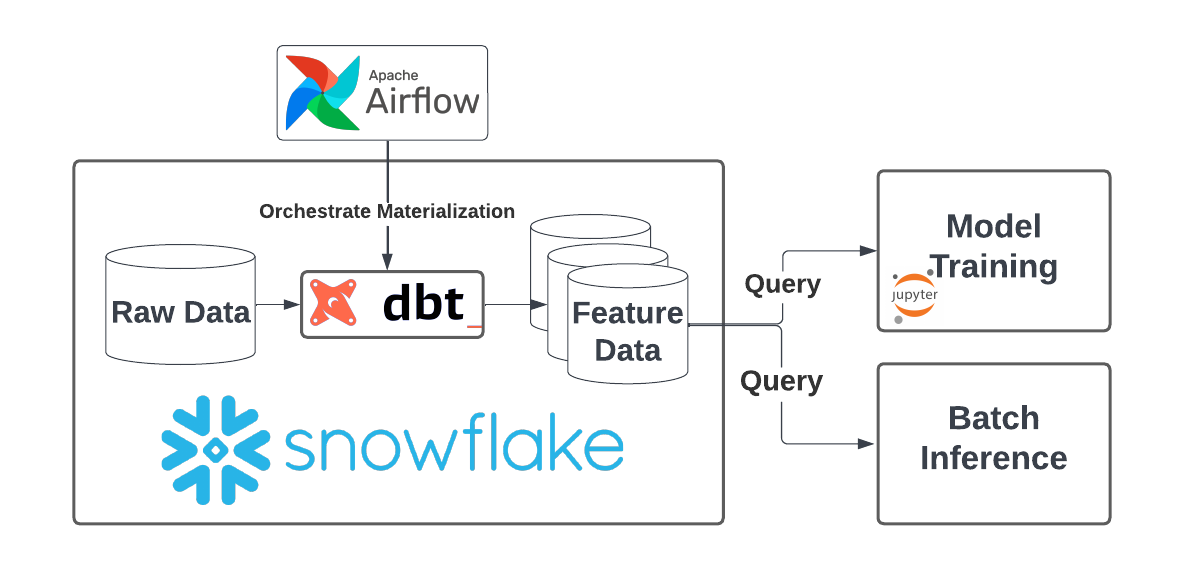
Notably, batch feature engineering is not all that hard! Thanks to the progress made over the past few decades building data warehouse solutions, there are a lot of tools available to build features on historical data. A common stack that I’ve seen folks converge on in the last few years looks like:
- A data warehouse for central access to data (e.g. Snowflake or Databricks)
- A data modeling tool to express feature logic (e.g. DBT)
- A scheduler to orchestrate feature computation (e.g. Airflow)
- A tool for querying features and training models (e.g. Snowflake, Databricks)
With this stack, scheduled jobs (~daily) kick off the materialization of feature tables, which can be consumed on demand by ML models.
The nice thing about batch machine learning is that the work done to generate training data typically generalizes between model training and model inference. If you were diligent about using modern tooling to build your training data, you should be able to reuse that code to pull data for batch inference.
Notably, many teams still haven’t converged on both a good stack and good practices for the creation and generation of training data. You still frequently hear stories about feature engineering in fragile Python notebooks—untangling and refactoring this code can still be a multi-week slowdown on the path to production.
TL;DR: There are good solutions to build batch ML data pipelines, but they are not yet widely adopted.
The first challenge: Online inference
The data world starts to change once predictions need to be made in real time—suddenly machine learning models needs very fast access to feature data. If an ML model is in the critical path of an application, typically the service-level agreement (SLA) for inference is ~100 milliseconds. That means you have less than 100 milliseconds to retreive data! Suddenly the code you wrote to read features from your data warehouse won’t cut it anymore.
To solve this problem, you’ll typically start by precomputing features and storing them in a fast database. The most common addition I see to the batch stack to solve this is Redis.
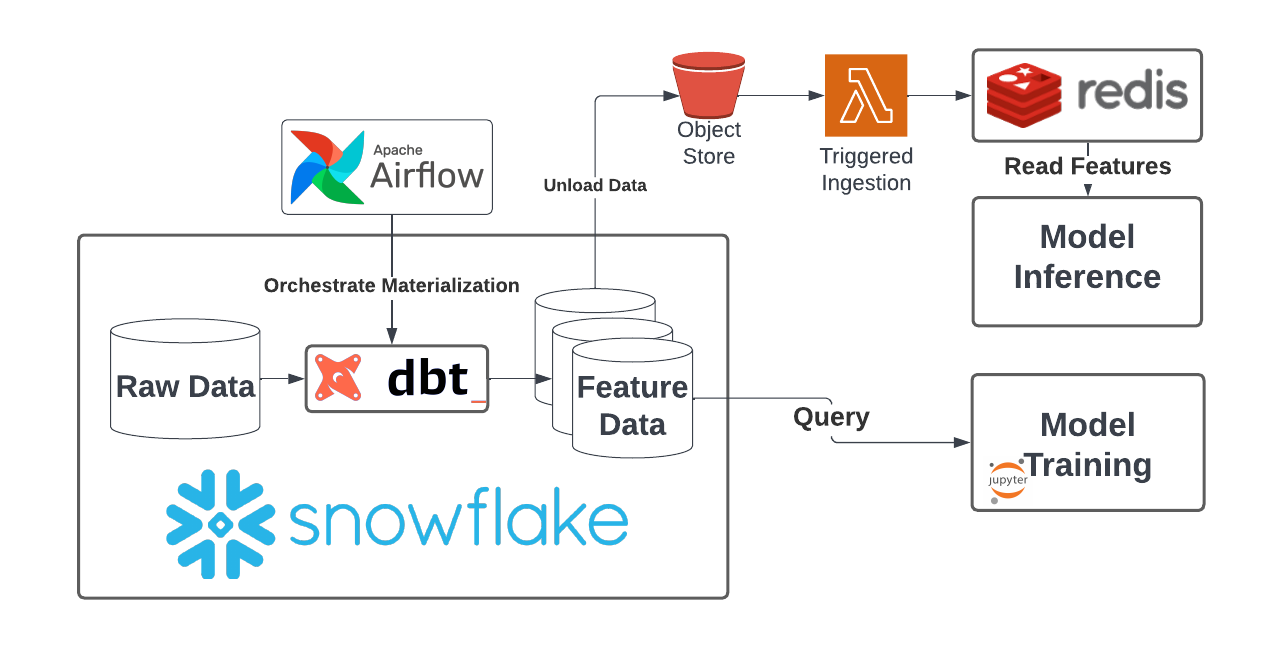
To make this all work, you’ll need to add a step to your scheduled feature materialization jobs to load data into Redis. A reasonable approach would be to unload newly computed features to object storage, then write a Lamba function that triggers on the appearance of new data to load the data into Redis.
The main challenge added by this change is that now you need to maintain standing infrastructure! Previously, all of your work (outside of your data warehouse) was stateless and typically not time sensitive. If something failed, you could manually debug and retry a job. However, if Redis fails, your application is facing downtime! Realistically, this comes with significant new burdens:
- You’ll want to implement monitoring on your online store to detect issues
- You’ll need to implement an on-call engineering rotation to support your feature-serving infrastructure
These changes represent significant engineering burdens and costs—work maintaining infrastructure will begin to drag your time away from creating new ML models.
TL;DR: With online inference, you’ve entered the world of maintaining standing data infrastructure, which has significantly increased the burden on your engineering team.
The big challenge: Fresh features in machine learning
The complexity of your machine learning product begins to explode as soon as your model demands fresh features. Most real-time ML models benefit heavily from fresh data—for instance, fraud models need to process information about recent transactions, recommendation systems care about recent user behavior, insurance-quoting models depend on information from third-party APIs, etc.). So now you need to solve the problem of gathering features from many different sources.
The first challenge is simply figuring out where fresh data will come from! Some of the common sources I’ve seen:
- Streaming data (e.g. Kafka)
- Third-party APIs (e.g. Plaid)
- Transactional databases (e.g. Postgres)
- Internal APIs managed by other teams
- Application context
Simply hunting down all of these sources of data (to match what was available in your data warehouse) can be a major challenge. Making it worse, you’ll often need a unique set of tooling to query and transform each of these sources of data into features!
| Streaming data | Stream processing (e.g. Flink, Spark Structured Streaming) |
| Third-party APIs (e.g. Plaid) | Application code (e.g. Java, Go) |
| Transactional databases (e.g. Postgres) | SQL |
| Internal APIs managed by other teams | Application code (e.g. Java, Go) |
| Application context | Application code (e.g. Java, Go) |
Each of these applications has its own engineering challenges associated with it. Building efficient stream processing code is incredibly challenging as an example.
Your stack has a lot of moving parts now:
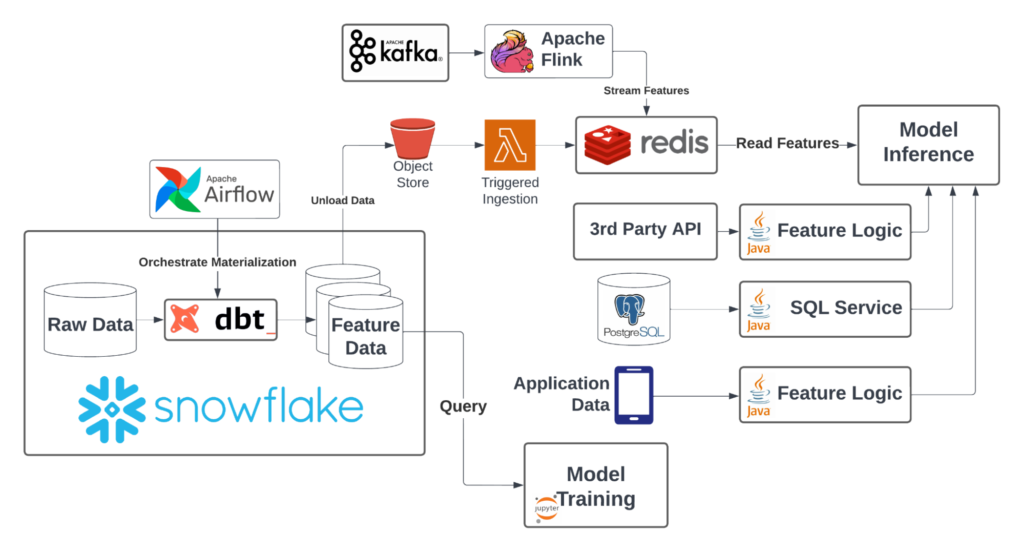
There is also a lot more standing infrastructure to monitor: microservices, stream processing jobs, transactional databases. This means more monitoring to build and more on-call burden. You’ll need to commit significant time to maintaining existing systems—and probably a dedicated team, eventually.
You also need to put significant thought into the scalability of your solution when you’re dealing with online traffic. Modern data warehouses handle scaling a lot more seamlessly than most online data infrastructure! You’ll need to design a solution that can handle your peak load now (and hopefully your peak load next year, too!). At the largest scale, each of these production systems can be incredibly complex to scale and manage.
TL;DR: Fresh features multiply the amount of infrastructure you need to manage.
The kicker: Training / serving skew in machine learning models
Eventually, you’ll complete all of the engineering work needed to maintain a production ML model with fresh features—but the challenges have just begun. If you’re like most organizations, you’ve built your features in two distinct places, using two different data models. Writing logic in two places almost always leads to small but important differences in feature distributions!
This approach (almost invariably) leads to training / serving skew—the features you used to train your model will look slightly different than the features you use when making predictions. You’ll notice this because the model you spent all that time building isn’t performing nearly as well as you expected it to in the real world.
Diagnosing and solving training / serving skew is a painfully difficult task for most teams. You’ll probably need to retrofit both your online and offline feature computation with some sort of data quality monitoring and drift detection (a complicated form of monitoring). Debugging these differences can take additional weeks of engineering time.
Solution: Feature platforms are built to manage the complexity of real-time data pipelines for machine learning
The modern solution for building machine learning data pipelines is the feature platform. Feature platforms give teams the tools to centrally build and manage all of the diverse data pipelines needed to power machine learning models. Here’s an overview of how to build a feature store, which will walk you through the components you need to build to solve the problems laid out in this blog.
If you’d prefer to buy an enterprise-grade solution, Tecton is purpose-built to simplify the challenges I enumerated above. Tecton:
- Helps you build unified online / offline pipelines to avoid training / serving skew before it happens.
- Supports processing data from each of the common sources of fresh data (meaning you don’t need to build your own tooling and services for each of these sources).
- Is a managed service with guaranteed SLAs, reducing the on-call burden needed to support production ML systems.
- Is built to scale, so you won’t need to re-architect when your application grows.
Tecton’s goal is to make it easy for teams to quickly develop real-time data pipelines for ML applications. Let us know if you’re interested in trying it out!

Want to learn more about data engineering for real-time ML?
Watch this on-demand video, where Henrik Brackmann, VP Data at Tide (a UK finserv provider), shares the key areas his team focused on during their attempt at building a feature store, and why they eventually decided to adopt Tecton’s feature platform to support their real-time ML use cases.


