Why We Need DevOps for ML Data


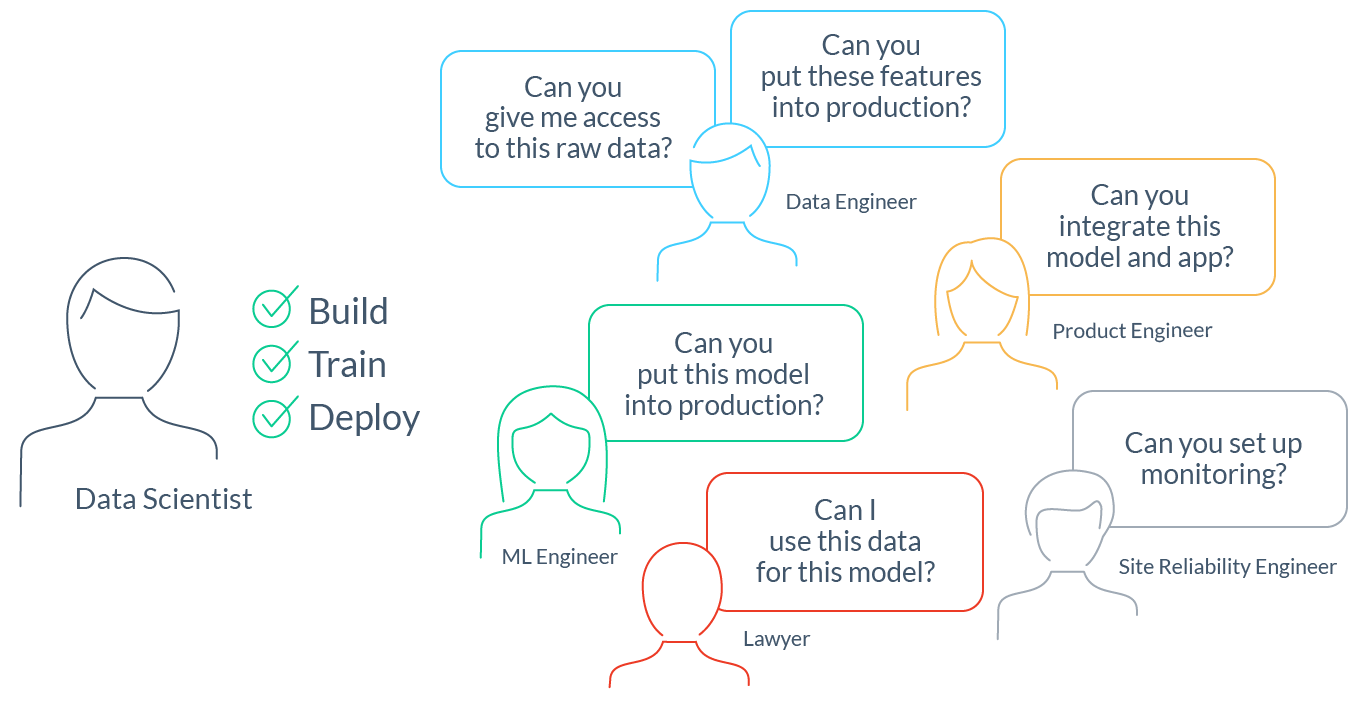
Getting machine learning (ML) into production is hard. In fact, it’s possibly an order of magnitude harder than getting traditional software deployed. As a result, most ML projects never see the light of production-day and many organizations simply give up on using ML to drive their products and customer experiences.1
From what we’ve seen, a fundamental blocker preventing many teams from building and deploying ML to production at scale is that we have not yet successfully brought the practices of DevOps to machine learning. MLOps solutions have emerged that solve the process of building and deploying ML models — but they lack support for one of the most challenging parts of ML: the data.
This blog discusses why the industry needs to solve DevOps for ML data, and how ML’s unique data challenges stifle efforts to get ML operationalized and launched in production. It describes the vacuum in the current ML infrastructure ecosystem and introduces Tecton, a centralized data platform for machine learning, to fill that vacuum. For additional details on Tecton’s launch, check out my co-founder Mike’s announcement post here.
The lessons presented in this blog, and the Tecton platform itself, are heavily influenced by the learnings our team has gathered putting ML into production over the last several years. Tecton was formed by a group of engineers who built internal ML platforms at places like Uber, Google, Facebook, Twitter, Airbnb, AdRoll, and Quora. These companies have invested massively in ML and developed processes as well as tools to broadly adopt ML within their organizations and products.
Remember when releasing software was slow and painful?
Developing and deploying software 20 years ago looked a lot like developing ML applications today: feedback loops were incredibly long and by the time you released an application, the requirements and designs that you started with were obsolete. Then, in the late 00’s, DevOps emerged as a set of software engineering best practices to manage the software development lifecycle and enable continuous, rapid improvement.
Under the DevOps approach, software engineers work in a well-defined shared codebase. Once an incremental change is ready for deployment, the engineer checks it into a version control system. A Continuous Integration/Delivery (CI/CD) pipeline picks up the latest changes, runs unit tests, builds the software artifacts, runs integration tests, and eventually rolls out the change to production in a controlled fashion or stages the release for distribution2.
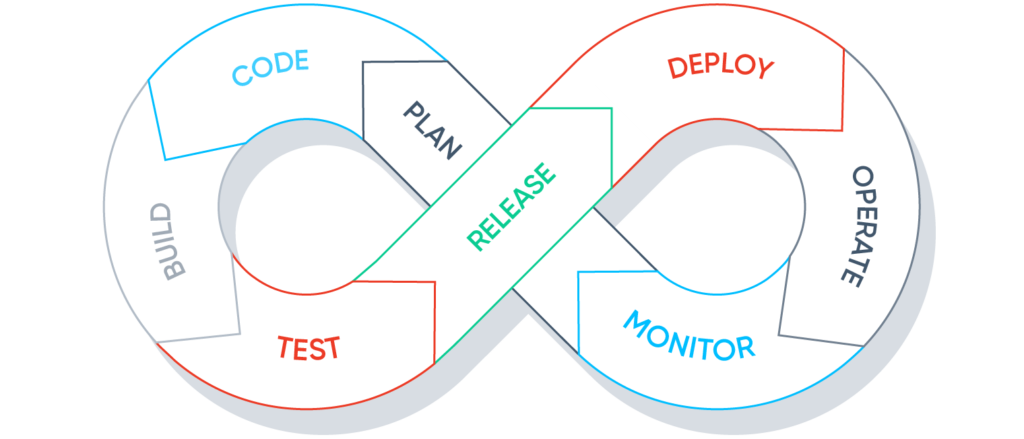
Some key benefits of DevOps:
- Software engineers own their code end-to-end. They’re empowered and ultimately responsible for every line of code that’s running in production. This sense of ownership generally increases code quality, as well as application availability and reliability.
- Teams are able to iterate rapidly and aren’t slowed down by months-long waterfall cycles. Instead, they can test new capabilities with real customers almost instantly.
- Performance and reliability issues can be identified and addressed quickly. If a health metric drops right after the most recent deployment, rollbacks are auto-triggered, and the code change that triggered the deployment is a likely culprit.
This integrated approach has now become the default for many software engineering teams.
…Well, deploying ML is still slow and painful
In stark contrast to software engineering, data science doesn’t have a well-defined, fully automated process to get into production quickly. The process to build an ML application and deploy it in a product involves multiple steps:
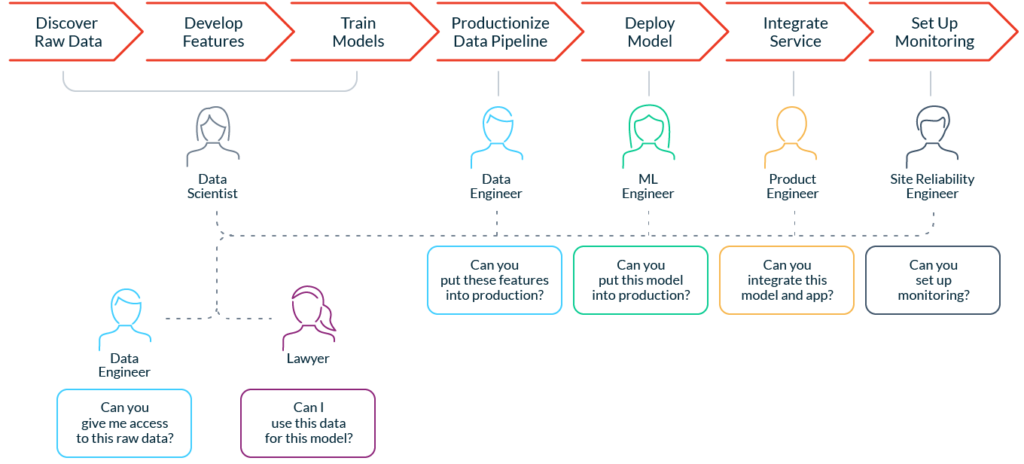
- Discover and access the raw data. Data scientists in most companies spend up to 80% of their time3 searching for the right raw data for their modeling problem. This often requires cross-functional coordination with data engineers and regulatory teams.
- Develop features and train models. Once data scientists get access to the data, they often spend weeks cleaning and turning it into features and labels. They then train models, evaluate them, and repeat the process several times.
- Productionize data pipelines. Data scientists then turn to engineering teams to “productionize” their feature data pipelines. This typically means “throwing feature transformation code over the wall” for an efficient reimplementation that is production-ready (more on this later).
- Deploy and integrate the model. This step typically involves integrating with a service that uses the model for predictions. For example: an online retailer’s mobile app that uses a recommendation model to predict product offers.
- Set up monitoring. Again, engineering help is required to ensure that the ML model and data pipelines continue to operate correctly.
As a result, ML teams face the same types of problems that software engineers dealt with 20 years ago:
- Data scientists lack full ownership of the model and feature lifecycle. They depend on others to deploy their changes and maintain them in production.
- Data scientists are unable to iterate rapidly. The lack of ownership makes it impossible to iterate quickly. Teams on which data scientists depend have their own priorities and agendas, which often introduce delays and uncertainty. Iteration speed is critical and delays can easily compound to levels that squash productivity:
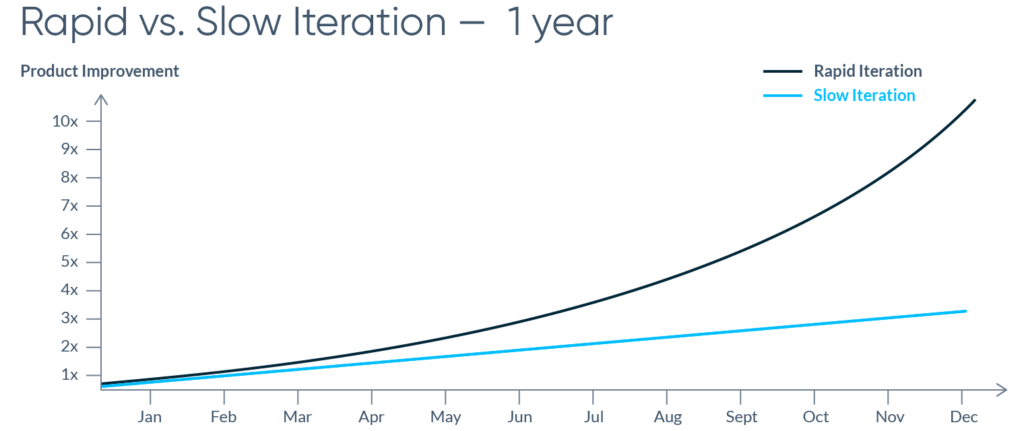
- Performance and reliability issues are rarely identified. It’s easy to miss important details when engineers reimplement a data scientist’s work. And it’s even easier to completely fail to notice when a model that’s running in production isn’t making accurate predictions anymore because data pipelines are broken or because the world has changed and a model needs to be retrained.
DevOps for ML models is well on its way. But DevOps for ML data is lacking.
We are now starting to see MLOps bring DevOps principles and tooling to ML systems. MLOps platforms like Sagemaker and Kubeflow are heading in the right direction of helping companies productionize ML. They require a fairly significant upfront investment to set up, but once properly integrated, can empower data scientists to train, manage, and deploy ML models.
Unfortunately, most tools under the MLOps banner tend to focus only on workflows around the model itself (training, deployment, management) — which represents a subset of the challenges for operational ML. ML applications are defined by code, models, and data4. Their success depends on the ability to generate high-quality ML data and serve it in production quickly and reliably… otherwise, it’s just “garbage in, garbage out.” The following diagram, adapted and borrowed from Google’s paper on technical debt in ML, illustrates the “data-centric” and “model-centric” elements in ML systems. Today’s MLOps platforms help with many of the “model-centric” but only a few, if any, of the “data-centric” elements:
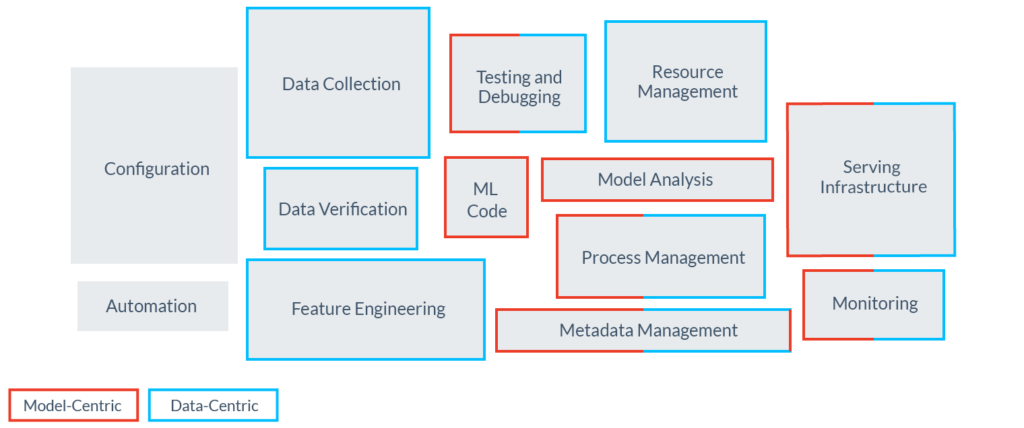
The following sections highlight some of the toughest challenges we’ve gone through to operationalize ML. They’re not meant to be exhaustive, but intended to provide an overview of issues we’ve frequently run into when managing the lifecycle of ML data (features and labels):
- Accessing the right raw data source
- Building features from raw data
- Combining features into training data
- Calculating and serving features in production
- Monitoring features in production
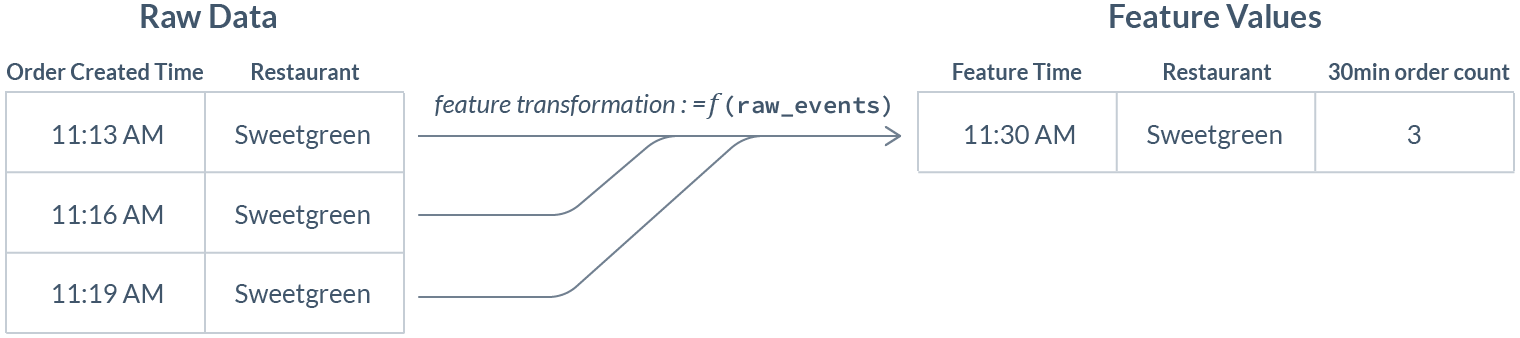
A quick refresher before we dive in: in ML, a feature is data that serves as an input signal to a model making a prediction. For example, a food delivery service wants to show an expected delivery time in their app. This requires predicting the meal preparation time of a specific dish, from a specific restaurant, at a specific time. One useful signal to help make this prediction — a proxy for how busy the restaurant is — is the “trailing count” of incoming orders in the past 30 minutes. The feature is calculated using a raw data stream of order events:
Data Challenge #1: Accessing the right raw data source
In order to develop any feature or model, a data scientist first needs to discover and access the right raw data source. This comes with several challenges:
- Data discovery: They need to know where the raw data actually exists. Data cataloging systems like Lyft’s Amundsen are a great solution but not yet widely adopted. Often the data needed doesn’t even exist in the first place and must first be created or logged.
- Access approval: Data scientists often have to jump through approval hoops to get access to data relevant for their problem.
- Raw data access: The raw data may be extracted as a one-time data dump that’s out of date the moment it lands on their laptop. Or, the data scientist struggles her way through networking and authentication obstacles and is then faced with having to fetch the raw data using data source-specific querying languages.
Data Challenge #2: Building features from raw data
Raw data can come from a variety of data sources, each with its own important properties that impact what kinds of features can be extracted from it. Those properties include a data source’s support for transformation types, its data freshness, and the amount of available data history:
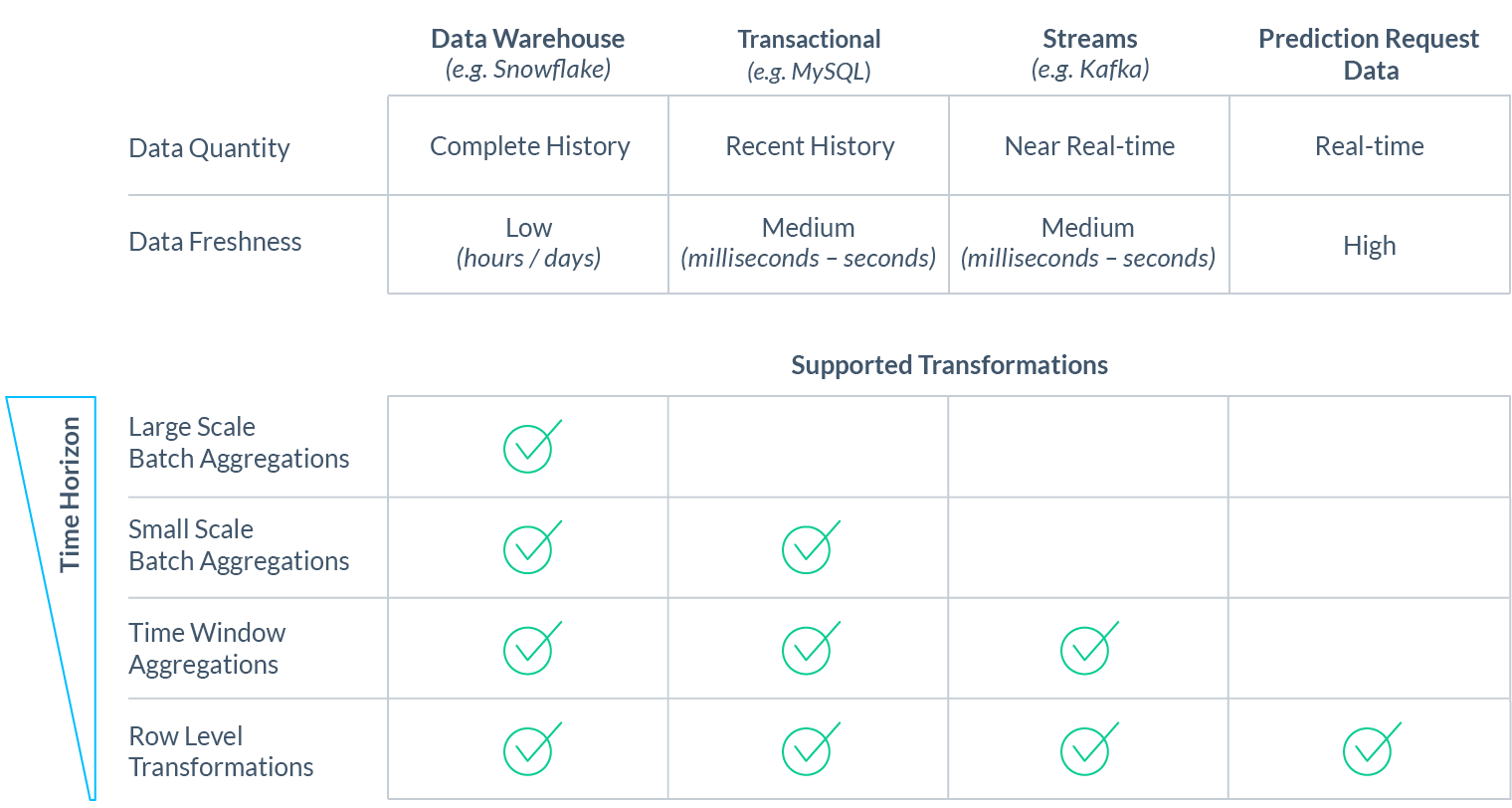
Taking these properties into account is important, as the type of data source determines the types of features a data scientist can derive from the raw data:
- Data warehouses / lakes (such as Snowflake or Redshift) tend to hold a lot of information but with low data freshness (hours or days). They can be a gold mine, but are most useful for large-scale batch aggregations with low freshness requirements, such as “number of lifetime transactions per user.”
- Transactional data sources (such as MongoDB or MySQL) usually store less data at a higher freshness and are not built to process large analytical transformations. They’re better suited for small-scale aggregations over limited time horizons, like the number of orders placed by a user in the past 24 hrs.
- Data streams (such as Kafka) store high-velocity events and provide them in near real-time (within milliseconds). In common setups, they retain 1-7 days of historical data. They are well-suited for aggregations over short time-windows and simple transformations with high freshness requirements, like calculating that “trailing count over the last 30 minutes” feature described above.
- Prediction request data is raw event data that originates in real-time right before an ML prediction is made, e.g. the query a user just entered into the search box. While the data is limited, it’s often as “fresh” as can be and contains a very predictive signal. This data is provided with the prediction request and can be used for real-time calculations like finding the similarity score between a user’s search query and documents in a search corpus.
And taking it one step further: many great features result from combining data from multiple sources with complementary characteristics, which requires implementing and managing more advanced feature transformations.
Data Challenge #3: Combining features into training data
Feature data needs to be combined to form training or test data sets. There are many things to look out for that can have critical implications on a model. Two notably tricky issues:
- Data Leakage: Data scientists need to ensure their model is training on the right information and that unwanted information is not “leaking” into the training data. This can be data from a test set, ground truth data, data from the future, or information that undoes important preparation processes like anonymization.
- Time Travel: One particularly problematic kind of leakage is data from the future. Preventing this requires calculating each feature value in the training data accurately with respect to a specific time in the past (i.e. time traveling to a point of time in the past). Common data systems aren’t designed to support time travel, leaving data scientists to accept data leakage in their models or build a jungle of workarounds to do it correctly.
Data Challenge #4: Calculating and serving features in production
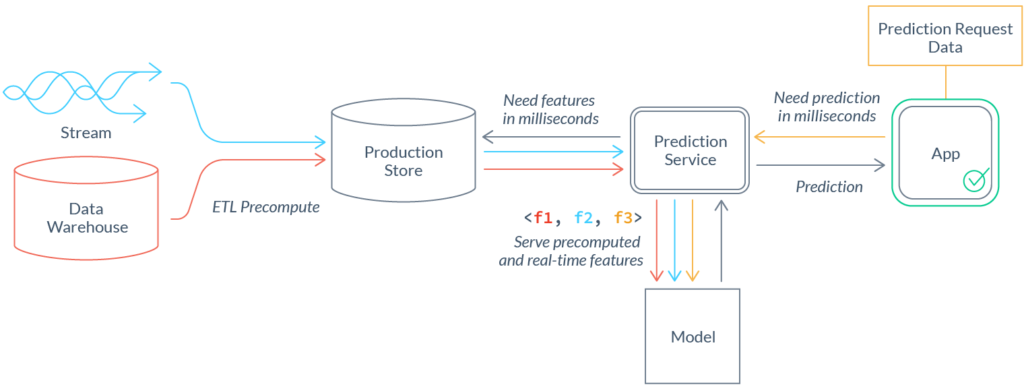
After a model is deployed for real-time use cases, new feature data needs to be continually delivered to the model to power new predictions. Often, this feature data needs to be provided at low latency and high scale.
How should we get that data to the model? Directly from the raw data source? In many cases, that’s not possible. It can take minutes, hours, or days to retrieve and transform data from a data warehouse, which is way too slow to be used for real-time inference:

In those cases, feature calculation and feature consumption need to be decoupled. ETL pipelines are needed to precompute features and load them into a production data store that’s optimized for serving. Those pipelines come with additional complexity and maintenance costs:
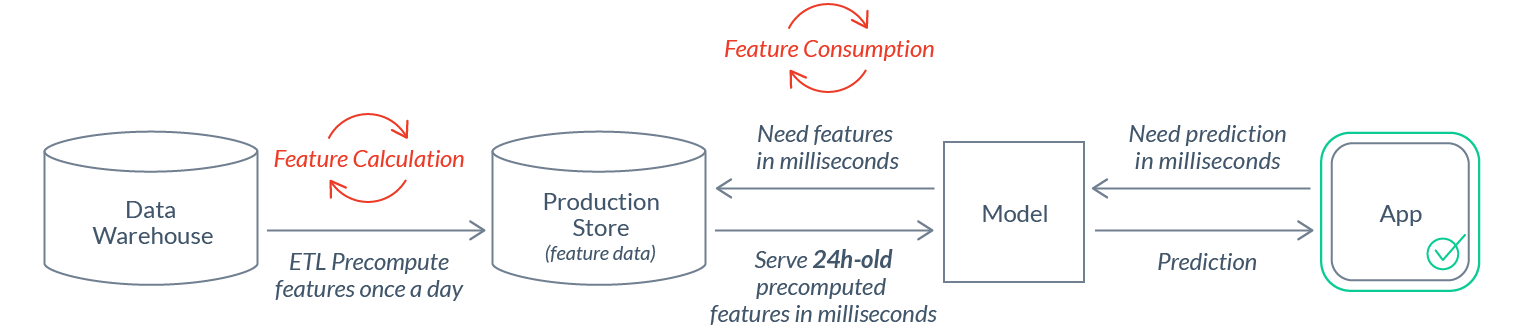
Finding the optimal freshness / cost-efficiency tradeoff: Decoupling feature calculation from feature consumption makes freshness a primary concern. Often, feature pipelines can be run more frequently and result in fresher values, at the expense of added cost. The right trade-off here varies across features and use cases. E.g. for a 30-minute trailing window aggregation feature to be meaningful, it should be refreshed more frequently than a similar 2-week trailing window feature.

Integrating feature pipelines: Although the above mainly discusses challenges with a specific type of data source, other complex challenges need to be solved to productionize features built on other types of data sources. Serious data engineering is typically required to coordinate these pipelines and integrate their outputs into a single feature vector:
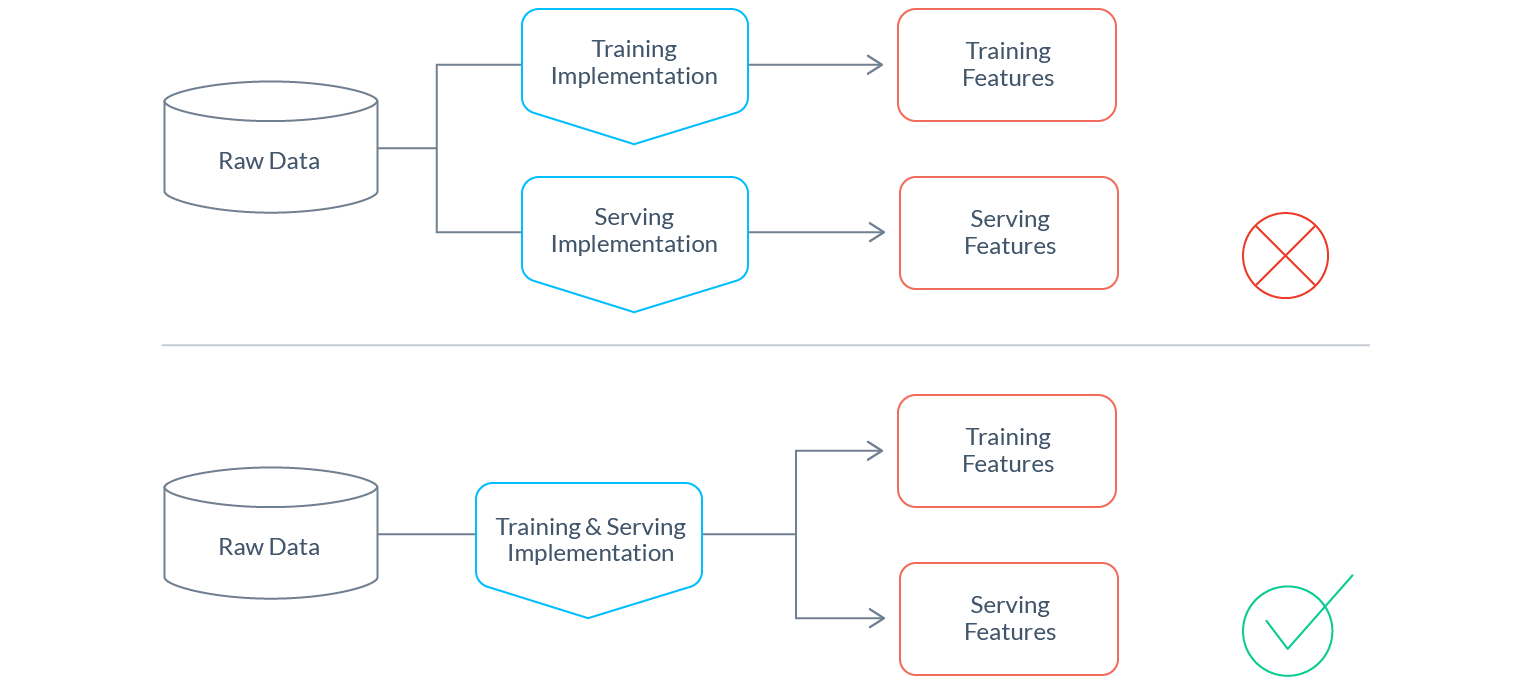
Avoiding training/serving-skew: Discrepancies between training and serving pipelines can introduce training/serving-skew. A model can act erratically when performing inference on data generated differently than the data on which it trained. Training/serving-skew can be very hard to detect and can render a model’s predictions completely useless. This topic deserves its own entire blog series. However, two common risks that are worth highlighting:
- Logic discrepancies: When training and serving pipelines have separate implementations (as is the common practice), it’s very easy for differences in transformation logic to be introduced. Are Null values handled differently? Do numbers use consistent precision? Tiny discrepancies can have a huge impact. Best practice for minimizing risk of any skew is to reuse as much transformation code as possible across training and serving pipelines. This is so important that it’s not uncommon to take on significant additional engineering effort to achieve this goal in the pursuit of saving endless future hours of painful debugging.
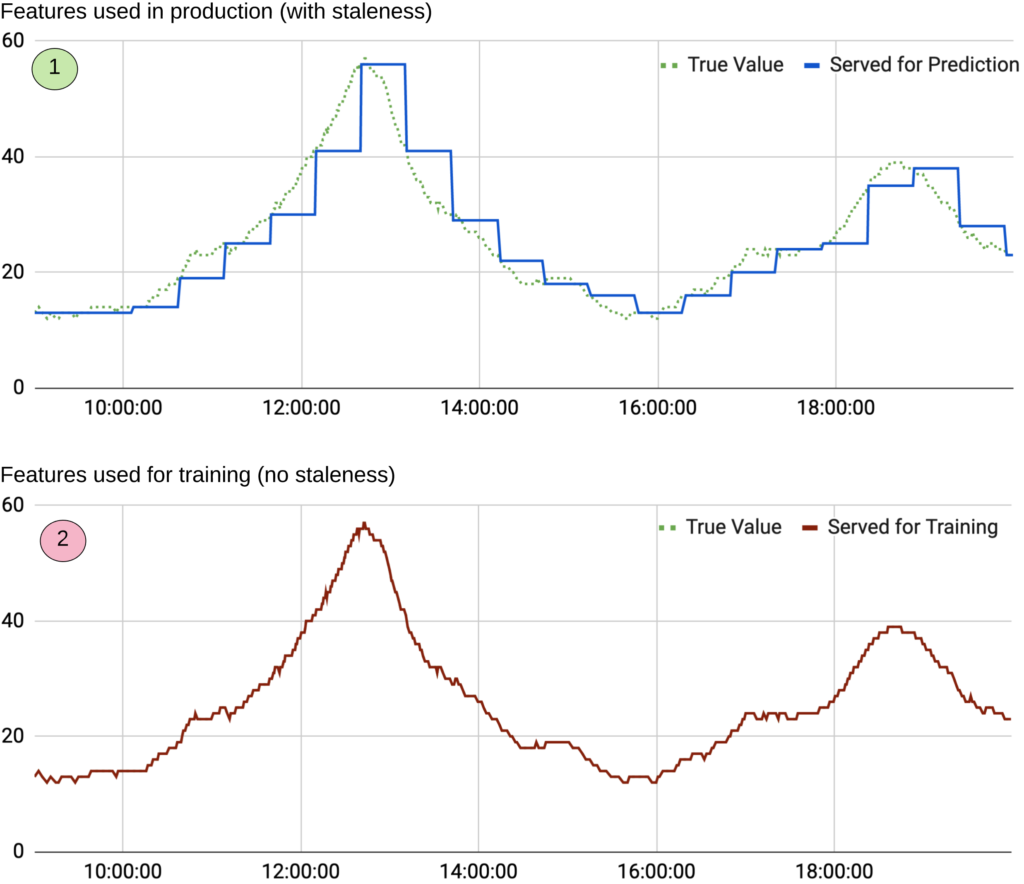
- Timing discrepancies: For a variety of reasons (like cost) features aren’t always continuously precomputed. E.g., little additional signal is gained from recalculating a two-hour trailing count of orders for every customer and every second in production. In practice, feature values tend to be a few minutes, hours, or even days stale at inference time. A common mistake happens when this staleness is not reflected in the training data, leading the model to train on fresher features than it would receive in production.
Data Challenge #5: Monitoring features in production
Despite all the effort put into getting everything above right, things will still break. When an ML system breaks, it’s nearly always due to a “data breakage.” This can refer to many distinct problems for which monitoring is needed. A few examples:
- Broken upstream data source: A raw data source may experience an outage and suddenly provide no data, late data or completely incorrect data. It’s all too easy for such an outage to go undetected. A data outage may have wide-reaching ripple effects, polluting downstream features and models. It’s often very difficult to identify all affected downstream consumers. And even if they are identified, solving the problem via backfills is expensive and arduous.
- Actionable feature drifts: Individual features may start to drift. This could be a bug or it could be perfectly normal behavior that indicates that the world has changed (e.g. your customer’s behavior may indeed have wildly changed based on a recent news break), requiring the model to be retrained.
- Opaque feature subpopulation outages: Detecting entire feature outages is fairly trivial. However, outages that affect only a subpopulation of your served model (e.g. all customers living in Germany) are much harder to detect.
- Unclear data quality ownership: Given that features may be derived from different upstream raw data sources, who is ultimately responsible for the quality of the feature? The data scientist who created the feature? The data scientist who trained the model? The upstream data owner? The engineer who did the production model integration? When responsibilities aren’t clear, issues tend to remain unresolved much longer than necessary.
These data challenges pose an almost impossible obstacle course even for the most advanced data science or ML engineering teams. In many organizations, the status quo is siloed, bespoke solutions to subsets of these challenges. A better approach is needed.
Introducing Tecton: A data platform for machine learning
At Tecton, we’re building a data platform for machine learning to help with some of the most common and most challenging workflows in data science.
At a high level, the Tecton Platform consists of:
- Feature Pipelines for transforming your raw data into features or labels
- A Feature Store for storing historical feature and label data
- A Feature Server for serving the latest feature values in production
- An SDK for retrieving training data and manipulating feature pipelines
- A Web UI for managing and tracking features, labels, and data sets
- A Monitoring Engine for detecting data quality or drift issues and alerting
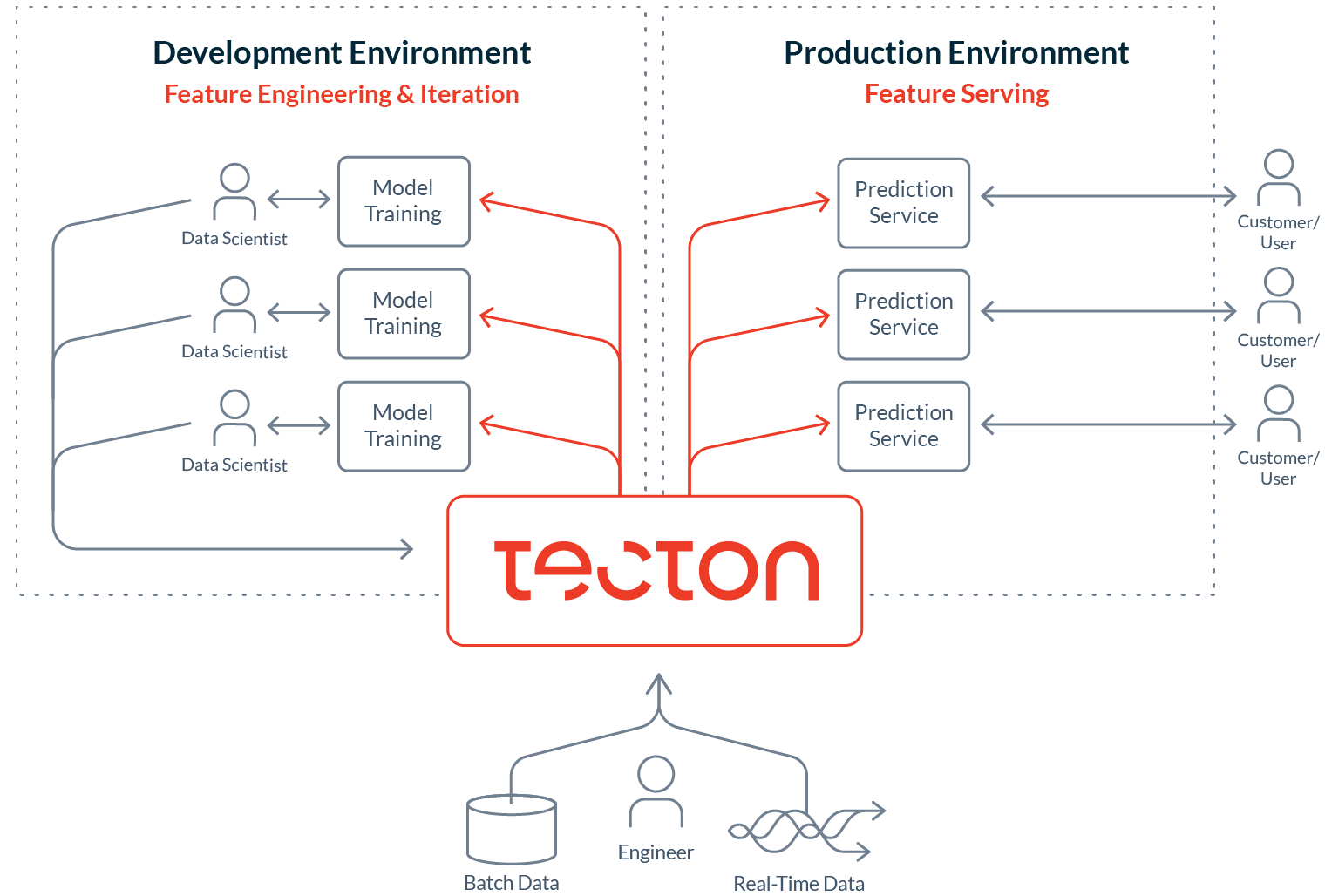
The platform allows ML teams to bring DevOps practices to ML data:
- Plan: Tecton’s features are stored in a central feature repository. This allows data scientists to share, discover, and leverage each other’s work.
- Code: Tecton lets users define simple but flexible feature transformation pipelines.
- Build: Tecton compiles the feature definitions into performant data processing jobs.
- Test: Tecton supports unit and integration testing of features.
- Release: Tecton tightly integrates with git. All feature definitions are version controlled and reproducible.
- Deploy: Tecton deploys and orchestrates the execution of data processing jobs on data processing engines (such as Spark). Those data pipelines continuously deliver feature data to Tecton’s feature store.
- Operate: Tecton’s feature server provides consistent feature values to data scientists for training and to production models for predictions.
- Monitor: Tecton monitors feature pipeline input and output for drift and data quality issues.
Of course, ML data without ML models doesn’t allow you to operationalize ML. That’s why Tecton exposes flexible APIs and integrates with existing ML platforms. We’ve started with Databricks, SageMaker, and Kubeflow, and continue to integrate with complementary components in the ecosystem.
We’re currently working closely with a few companies, helping them get their machine learning into production safely and at scale. If your team is working through similar challenges and interested in a hands-on partnership, we’d love to chat.
We’re also hiring! If you love to move fast, enjoy the challenge of building distributed data systems, and want to change how ML is managed in production, please check out our jobs page.
1. https://venturebeat.com/2019/07/19/why-do-87-of-data-science-projects-never-make-it-into-production/
2. Applications that cannot safely be continuously deployed to the customer (e.g. mobile apps or other applications that depend on an installation process) instead get staged for distribution.
3. https://www.infoworld.com/article/3228245/the-80-20-data-science-dilemma.html


