What Is Operational Machine Learning?



Author: Kevin Stumpf, Co-founder and CTO
In 2015, when we started rolling out Uber’s Machine Learning Platform, Michelangelo, we noticed an interesting pattern: 80% of the ML models launched on the platform powered operational machine learning use cases, which directly impact the end-user experience (Uber riders and drivers). Only 20% were analytical machine learning use cases, which power analytical decision-making.
The operational ML / analytical ML ratio we observed was the exact opposite of how most other enterprises applied ML in the wild — analytical ML was king. In hindsight, Uber’s massive adoption of operational ML is no big surprise: Michelangelo made it extremely easy to implement operational ML, and the company had a long lineup of high-impact use cases. Today, 7 years later, Uber’s reliance on operational ML has only increased: without it, you would see uneconomical trip prices, terrible ETA predictions, and hundreds of millions of dollars lost to fraud. In short, without operational ML, the company would grind to a halt.
Operational ML has been key to Uber’s success, and for a long time it seemed like something only tech giants could accomplish. But the good news is that a lot has changed in the past 7 years. There are new technologies and trends that allow any company to switch from using primarily analytical ML to using operational ML, and we have some tips for anyone eager to do so. Let’s dive in.
Operational ML vs. Analytical ML
Operational machine learning is when an application uses an ML model to autonomously and continuously make decisions that impact the business in real time. These applications are mission-critical and run “online” in production on a company’s operational stack.
Common examples include recommendation systems, search ranking, dynamic pricing, fraud detection, and loan application approvals.
Operational ML’s older sibling in the “offline” world is analytical machine learning. These are applications that help a business user make better decisions with machine learning. Analytical ML applications sit in the company’s analytical stack and typically feed directly into reports, dashboards, and business intelligence tools.
Common examples include sales forecasting, churn predictions, and customer segmentation.
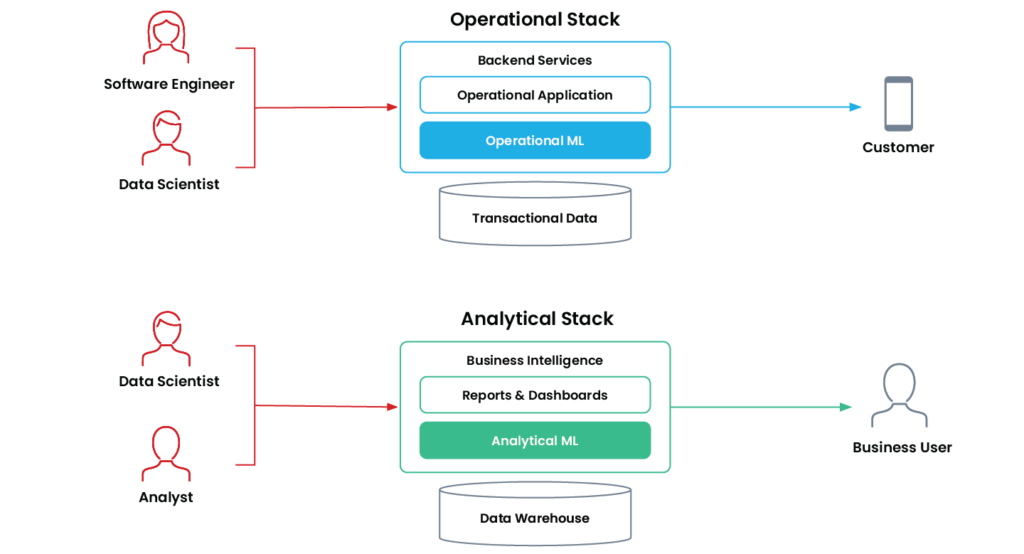
Organizations use operational ML and analytical ML for different purposes, and they each have different technical requirements.
| Analytical ML | Operational ML | |
| Decision Automation | Human-in-the-loop | Fully autonomous |
| Decision Speed | Human speed | Real time |
| Optimized For | Large-scale batch processing | Low latency and high availability |
| Primary Audience | Internal business user | Customer |
| Powers | Reports & dashboards | Production applications |
| Examples | Sales forecasting Lead scoring Customer segmentation Churn predictions | Product recommendations Fraud detection Traffic prediction Real-time pricing |
Operational Machine Learning in Practice
Let’s take a more concrete look at a real-world operational machine learning example from Uber Eats. When you open the app, it recommends a list of restaurants and suggests how long you would have to wait until the order shows up on your doorstep. What looks simple in the app is actually quite complex behind the scenes:
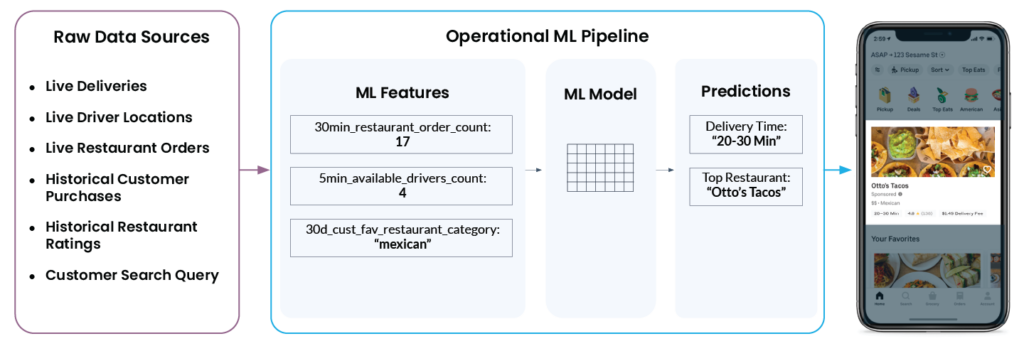
To eventually show “Otto’s Tacos” and “20-30 min” in the app, Uber’s ML platform needs to look at a wide array of data from various different raw data sources:
- How many drivers are in the restaurant’s vicinity now? Are they delivering an order or are they available for the next dispatch?
- How busy is the restaurant’s kitchen right now? The more orders a restaurant is currently processing, the longer it will take them to start working on a new order.
- Which restaurants has the customer rated highly and poorly in the past?
- What cuisine, if any, is the user actively searching for right now?
- And … what is the user’s current location?
Michelangelo’s feature platform converts this data into ML features. These are the signals that a model is trained on and uses to make predictions in real time. For example, ‘num_orders_last_30_min’ is used as an input feature to predict the delivery time, which will eventually show up in your mobile app.
The steps I’ve laid out above, which turn raw data from a myriad of different data sources into features, and features into predictions, are common across all operational machine learning use cases. Whether a system tries to detect credit card fraud, predict a car loan’s interest rate, suggest a newspaper article in the international affairs section, or recommend the best toy for a 2-year-old, the technical challenges are identical. And it’s exactly this fundamental technical commonality that allowed us to build one central platform for all operational ML use cases.
The Trends Enabling Operational Machine Learning
Uber was poised to take advantage of operational ML because it built its entire tech stack on a modern data architecture and modern principles. Over the past few years, we have seen a similar modernization take place far outside of Silicon Valley:
Historical data is preserved nearly indefinitely
Data storage costs have collapsed in recent years. As a result, companies have been able to collect, purchase, and store information about every touchpoint with customers. This is crucial for ML—training a good model requires a large amount of historical data. And without data, there’s no machine learning.
Data silos are getting broken up
From day one, Uber centralized pretty much all of its data in its Hive-based distributed file system. Centralized data storage (or, as an alternative, centralized access to decentralized data stores) is important because it allows data scientists, who train ML models, to know what data is available, where to find it, and how to access it. Most enterprises haven’t quite centralized all of their data (access) yet. However, architectural trends such as The Modern Data Stack have been moving the data scientist’s dream of democratized data access much closer into the limelight of reality.
Real-time data is made available with streaming
At Uber, we were lucky to have a “central nervous system” for data streams: Kafka. A lot of real-time signals from services and mobile apps are streamed through Kafka. This is crucial for operational ML.
You can’t detect fraud if you only know what happened yesterday. You need to know what happened in the last 30 seconds. Data warehouses and data lakes are built for long-term storage of historical data. And over the past few years, we’ve seen massive adoption of streaming infrastructure, like Kafka or Kinesis, to supply applications with real-time signals.
MLOps enables rapid iteration
At Uber, individual engineers are empowered to make daily changes to the production system. This process is supported by following and automating DevOps principles. With Michelangelo, we brought those principles to operational ML before the process was called MLOps 🙂. It was important to us that data scientists were able to train models and safely deploy them to production literally within one day.
Outside of Uber and far outside of Silicon Valley, we’ve seen a growing number of early adopters bring DevOps principles and automation not just to their software engineering, but also to their data science teams via MLOps. Of course, ML is still much more painful than software for most companies, for reasons that I outlined in this blog. But I’m convinced that the industry is steadily heading towards a future in which your typical data scientist in your typical Fortune 500 organization is able to iterate on an operational ML model multiple times a day.
Here’s what a modern data architecture that enables operational ML looks like:
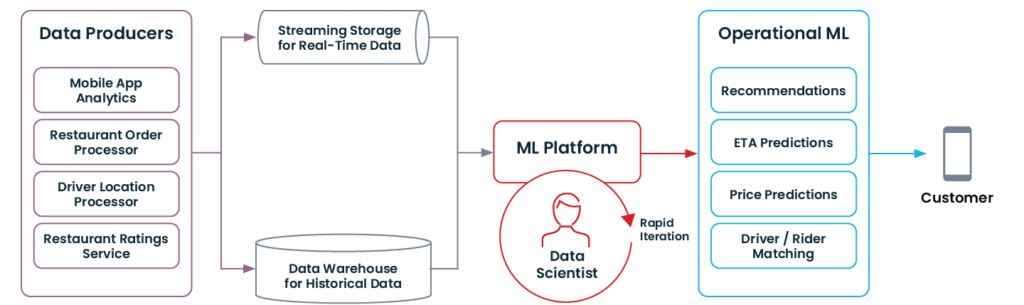
If your organization has gone through some of the modernizations mentioned above (or started with them from scratch!), you may be ready to get started with operational ML.
Get Started With Operational Machine Learning
In 2013, Uber was not using machine learning in production. Today, it’s running tens of thousands of models in production. That change did not happen overnight.
If you’re looking to take advantage of operational ML in your organization, I’d recommend taking the following steps:
Pick a use case that is fit for machine learning
Not all problems can be solved with ML. Qualifiers for a problem that may be well suited for ML:
- Your system is making a lot of very similar and repeated decisions (at least tens of thousands)
- Making the right decision is not trivial
- Some time after the decision was made, you have a way to determine whether the decision was a good one or a bad one
If these elements are true, a machine learning application can make decisions, learn from those decisions, and continuously improve.
Pick a use case that actually matters
As mentioned before, the path to get the first model into production is hard. If the future payoff of your first machine learning application isn’t very promising, it will be too easy to give up when the going gets tough. Priorities will change, leadership may get impatient, and the effort won’t endure. Pick a high-potential use case.
Empower a small team and minimize stakeholders for your first model
A project’s probability of failure increases with the number of handoffs involved in training and deploying a model. Ideally, start with a very small team of 2–3 people that have access to all the required data, know how to train a simple model, and are familiar enough with your production stack to put an application into production.
ML engineers are best suited to pave the way, given that they typically have a rare combination of data engineering, software engineering, and data science skills. This is also how you should scale machine learning teams, with small groups of ML experts embedded into product teams.
Don’t go through it alone
Finally, learn from the mistakes others have made. The MLOps Community is sprawling with helpful practitioners who have real-world experience putting simple and complex models into production. The apply() conference is a great virtual event where teams from around the world discuss the lessons they’ve learned when deploying ML.
Operational machine learning will continue to revolutionize entire industries. Not all applications are well suited for it—but for the ones that are, operational ML will be the key differentiator between winners and losers. If you have an application that would benefit from it, you should be thinking about adopting elements of a modern data architecture and experimenting with your first use cases. The effort will be worth it. And when you run into walls (we’ve all been there), feel free to DM me directly on the Tecton & Feast Community Slack or head to the MLOps community and ask for help.


