Why Centralized Machine Learning Teams Fail


As a Solutions Architect at Tecton, I’ve had the luxury of working with hundreds of teams that are building products powered by machine learning. And I’ve noticed one key difference in how these teams are organized that is highly predictive of their success.
Central data teams, where ML practitioners build models and then hand them back to IT to integrate into the business, usually fail. In this article, I’ll discuss what an ML-enabled company looks like and how to organize a machine learning team for success. I’ll make the case for embedding data specialists in product teams — an approach that has been successful at leading-edge tech companies and forward-thinking teams. We’ll discuss why the central data team model usually fails, and how transitioning to an embedded model can help your team succeed.
How did we get here?
All ML projects which turned into a disaster in my career have a single common point:
— Francesco Pochetti (@Fra_Pochetti) March 12, 2022
🚨 I didn’t understand the business context first, got over-excited about the tech, and jumped into coding too early.
Most data organizations grew up as an analytics team, which leads to a straightforward operational model. A central data organization is responsible for creating data products that drive business decisions. The model looks something like this:
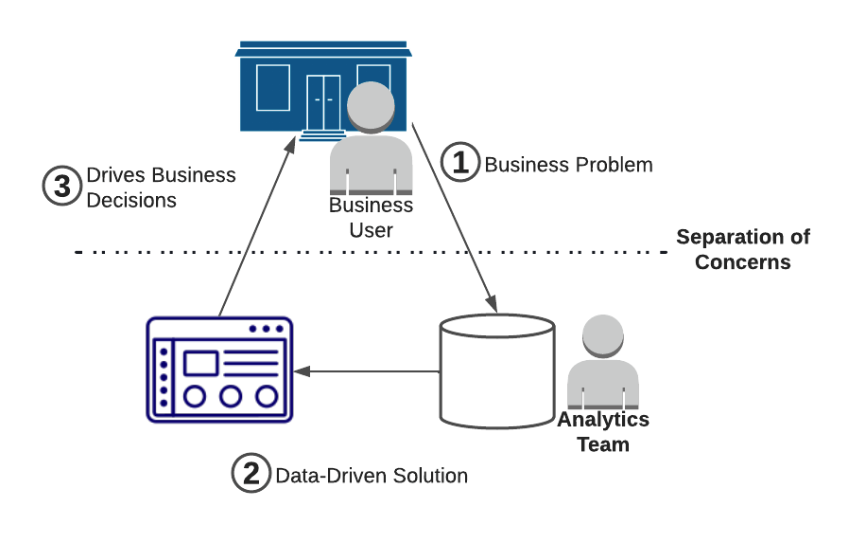
A core benefit to this model is that it allowed the existing business to continue operating “as-is”. Sure, there was a revolution in how data could drive business decisions, but with this model that revolution was purely additive. The business (which was ostensibly working well!) could just use the outputs of the data team to make better decisions, and there was no organizational reckoning.
As machine learning picked up in popularity in the last decade, the natural thing to do was to put the ML scientists on the data team (since they need data to do ML!).
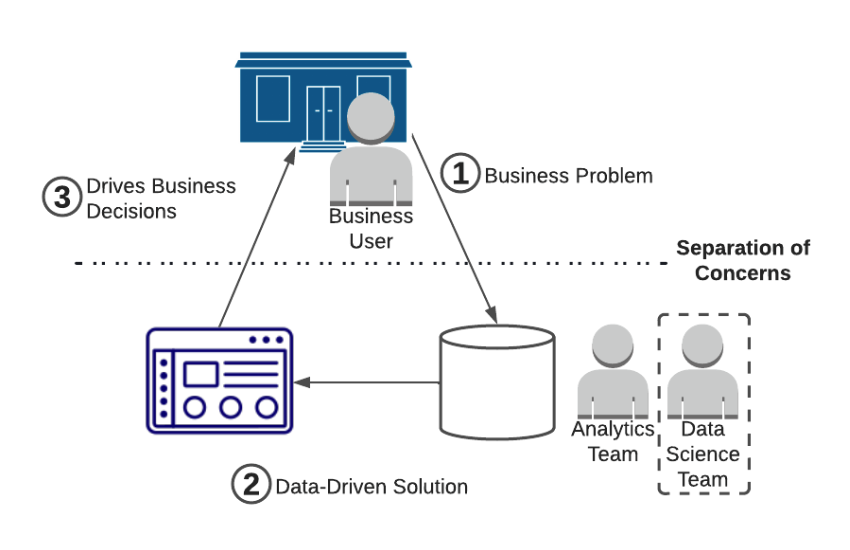
Unfortunately for central data teams, advances in machine learning have started to blur the line of shared concerns. More and more businesses are beginning to use ML to automate decisions, meaning the output of the ML team needs to be directly integrated into the business!
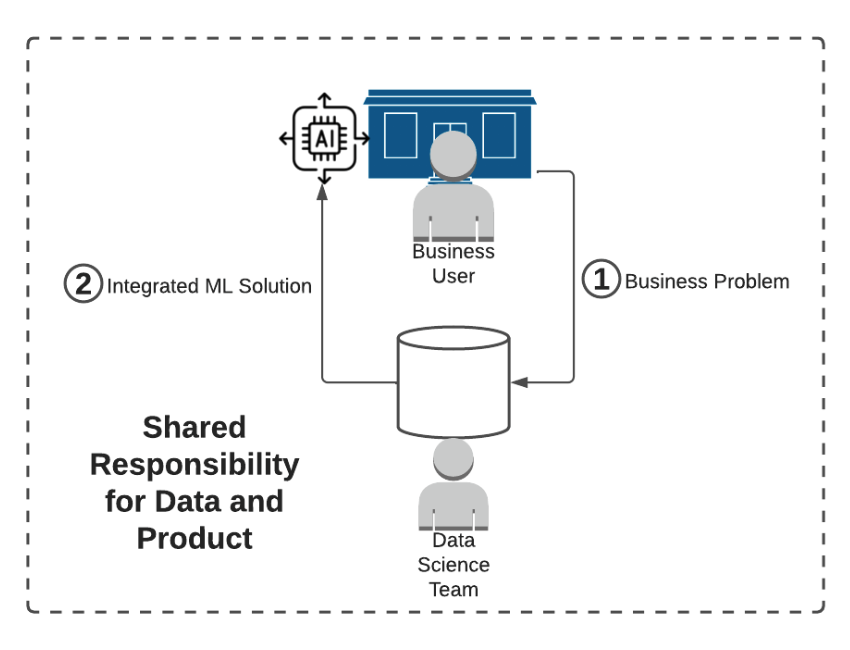
Your data team wasn’t designed to integrate products into your business – integrating software into your business is an engineering / IT problem! The natural progression many companies took is to make it an engineering / IT problem:
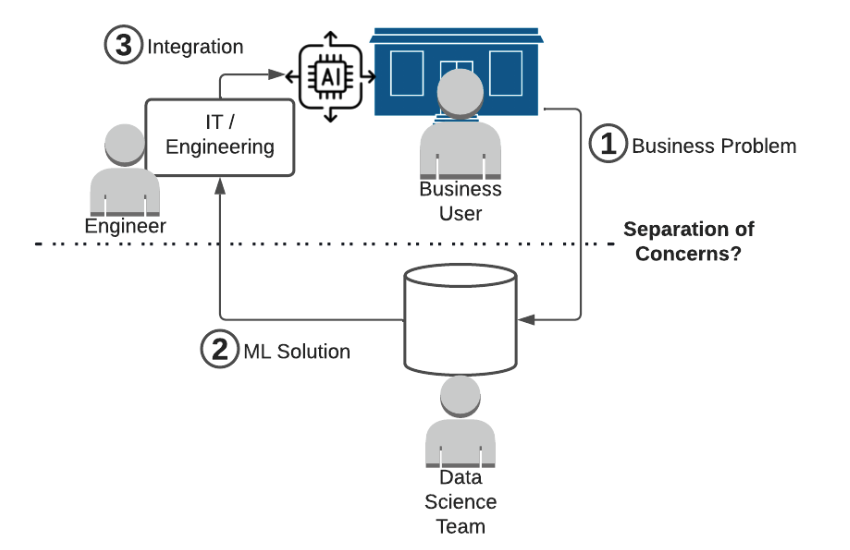
Solved, right?
Not at all. I’ve seen this model many times, and it always leads to execution problems.
You can’t hand off integration to IT
There are two main categories of challenges that emerge when ML teams “hand off” models for IT to integrate:
- ML scientists are not working within the constraints of the production environment
- Engineering / IT teams don’t have the machine learning expertise to manage data pipelines that will affect model performance
Both of these challenges are worth further exploration.
Challenge #1: Production data constraints
Data scientists don’t have the tools to understand what will and won’t work in a production environment. It’s natural for data scientists to build the most accurate model with whatever data is available in the data warehouse. However, this leads to two common types of mistakes:
1. Data is available in the data warehouse but isn’t available in a production environment, which actually takes two forms:
- Data isn’t available at all (e.g. data from a third party vendor that won’t be available when making an ML prediction)
- Data won’t be available in time (e.g. streaming infrastructure doesn’t exist yet to access recent events).
Data scientists have no way of knowing where the data is coming from. When an engineering team needs to put the model in production, their first instinct is often to try to solve the problem (build new infrastructure, access new data), instead of working with the data scientist to see if a different feature could work just as well. This leads to months of lost engineering effort.
2. Features are built with transformations that are painful to recreate in a production environment. Some transformations common in machine learning are trivial to implement in a data warehouse, but extremely challenging to implement in a serving environment (e.g. “lifetime count of transactions a user has made”). Without a strong understanding of real-time data processing, data scientists have no way of knowing which transformations will work in production. Engineering teams tasked with putting the model in production embark on long projects to implement complex production data pipelines. Further, the engineering team will often need to cut corners to make these feasible (maybe they will implement the “lifetime count of transactions a user has made, updated daily”). Without careful collaboration between engineers and data scientists, this will lead to training / serving skew, a silent killer of ML projects that derails a model’s performance once it’s in production.
Both problems emerge because, through no fault of their own, data scientists do not have enough context about production environments. Unfortunately, it’s rare for engineering teams to get involved at the model development stage, and in most cases, they implement a model that has already been developed and approved by business stakeholders.
Challenge #2: Managing data pipelines
Once engineering teams overcome the challenges described in the last section, they are responsible for maintaining a machine learning production system – a challenging job that requires machine learning expertise.
One issue that is bound to emerge is drift, in one of its many forms. ML models always experience performance degradation over their lifetimes, and debugging these issues requires a strong understanding of the underlying model and data. While good engineers can learn how to do so, data scientists are best positioned to solve this problem. But it’s extremely rare to see processes in place to escalate the issue back to data science, and when these issues do come up, data scientists have usually moved on to other projects.
Solution: Product-driven teams
Top tech companies figured this out a decade ago. The solution: ensure that teams developing products have the skills to build, productionize, and monitor ML applications. Now that you’re expecting data teams to influence your core product, they should participate in the same way software engineers would. Their KPIs should be the same as the rest of the product team (engagement, sales, etc.) instead of loosely correlated metrics, like model accuracy.
This is done by embedding data scientists and data engineers onto the product teams that are using machine learning. This doesn’t require a full re-org – teams still maintain a functional reporting structure into a central data organization. One way of implementing this structure is through the Spotify Model.
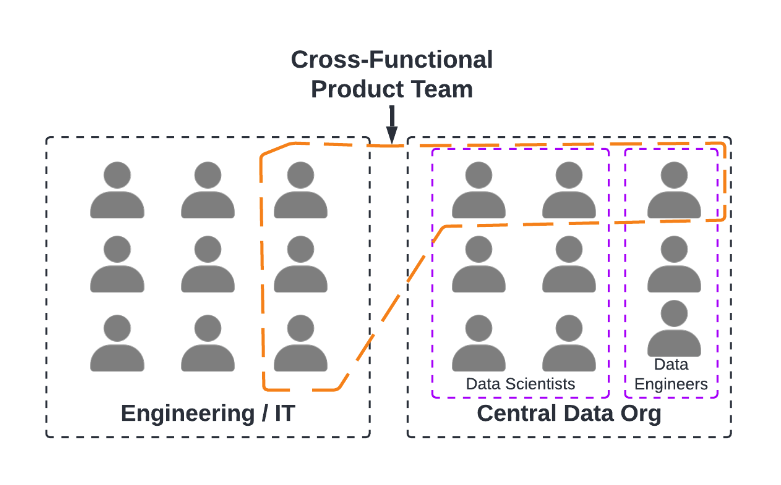
There are four key benefits I’ve seen from embedded teams:
- Data scientists and engineers improve product planning. Machine learning isn’t like traditional software. It has unique constraints on latency, hardware cost and data availability. You’ll want experts that understand these challenges to help prioritize product initiatives.
- Investing in early collaboration produces outsized returns. Consider the feature I presented above: “lifetime count of transactions a user has made”. By working with a data engineer, a data scientist can understand the feature is both expensive and complex to implement. Instead, they might select a simpler feature with similar predictive power: “365-day count of transactions a user has made, updated daily”. The organization just saved $50K in compute costs, a month of engineering time, and a lifetime of painful data pipeline maintenance. Every applied ML team knows how rare it is to have these conversations at the model development stage.
- Embedded teams find new opportunities for machine learning. Most businesses are rife with opportunities for ML. Without experts in the team, it’s very difficult to surface opportunities and appropriately assess which should be pursued.
- Clear ownership. When data scientists and data engineers are embedded in a product team, they are the clear owners for new and existing models. When something breaks in production, they’re responsible for it.
Conclusion
The Spotify model isn’t without its fair share of problems. Organizational design is hard, and there isn’t a cookie-cutter method to design cross-functional teams. Centralized data organizations have benefits too, and the most successful companies are proactive about addressing the challenges of embedded teams:
- Learning and development becomes more challenging in embedded teams as there is limited interaction with peers of the same discipline.
- Data scientists and engineers must be proactive about establishing common best practices and maintaining consistency across product groups.
- This includes standardizing on consistent tools, and larger organizations usually set up a small, centralized platform team to provide tooling and infrastructure for embedded teams.
- With fully centralized teams, re-allocating resources to highest priority projects is simple. Re-allocating embedded data engineers and data scientists across teams is substantially more difficult.
While these challenges are non-trivial, time and again the successful teams I’ve seen have data scientists and engineers embedded in product teams. The benefits of embedded teams far outweigh the costs. This is not only true for high-tech companies, it holds true across industries. In practice, centralized machine learning teams just don’t work.