How Machine Learning Teams Share and Reuse Features


What does an “ML-enabled” company look like? The companies that come to mind, like Uber, Twitter, or Google, have tens of thousands of machine learning (ML) models in production. They use these models to make intelligent predictions across the business in real-time, critical capacities (we call this “operational ML”).
These companies are in a very different position from the average company using operational ML. Many companies are aiming to become more ML-enabled but only have a handful of models in production, and they’re just scratching the surface of the potential applications for ML in their business.
Going from one model to thousands of models is difficult, but creates immense value. At Tecton, we’ve seen this transformation happen up close: our founders and early employees built the ML platforms at Uber, Twitter, and Quora.
These companies have one key strategy in common: they share and reuse features across models and use cases. In our experience, feature reuse has been the single most important factor to successfully scaling ML across use cases at any given company.
Why is feature sharing so important?
Feature sharing is so important because data assets, particularly features and training datasets composed of features, are the hardest ML artifacts to create and manage. Data engineers and data scientists spend most of their time on feature development, so reusing features allows teams to leapfrog over the most difficult parts of putting new models into production.
It may be counterintuitive, but many features can be widely applicable to a variety of ML use cases in a business. For example, search, recommendations, and ad scoring all have similar demands for features that model user behavior. When features aren’t shared, redundant work happens. Furthermore, ML practitioners fail to learn about novel features from other teams that could benefit their models. Organizations are leaving significant improvements in model performance on the table when ML teams are working in silos.
Feature reuse also creates a strong snowball effect. When features are being reused, every new model deployment makes subsequent model deployments easier by adding to a company’s feature library. Eventually, only small amounts of feature engineering may be needed to deploy models because the majority of features in models are coming from reuse.
What are the common challenges with feature sharing?
Feature reuse is not top of mind for most organizations using ML today, and since it rarely happens organically, most businesses using ML end up reimplementing features across teams and use cases. In our experience, we’ve seen a few reasons why organizations struggle with feature sharing:
Teams don’t know what features exist. Separate teams are simply not aware of what features already exist. There is no way to see what features other teams have developed, and the information that you’d need to actually reuse a feature isn’t recorded anywhere, (e.g. “What models is this feature used in?”, “Does this feature make the model perform better?”, “Is this feature used in production or is it experimental?”)
To give you an idea of just how common this problem is, here’s an actual situation we’ve seen at a large tech company: information about features wasn’t available anywhere, so teams would have a monthly meeting where they’d swap lists of features that had recently improved model performance. Then, they’d each go away and reimplement these features in their own pipelines!
There is no standard access pattern for features. Teams have their own bespoke pipelines for training and serving, so features built for one system often won’t be accessible to other systems. When it takes effort and tribal knowledge to make an existing feature work in a new system, teams will often opt to just reimplement the feature instead of reusing it.
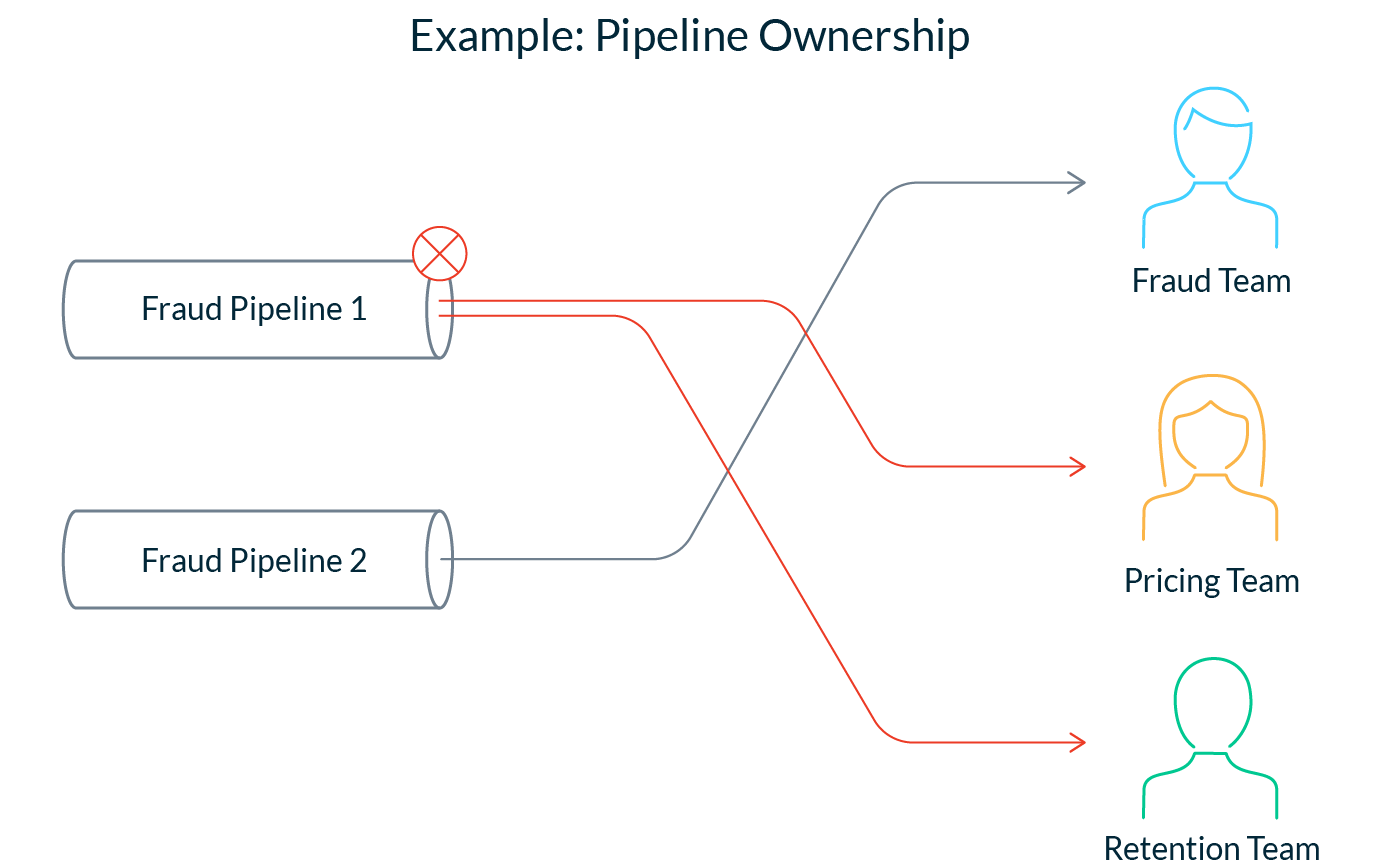
Ownership over features is unclear. It’s hard for teams to adopt dependencies that they don’t trust. Without a central feature sharing system, there are questions about the ownership of feature pipelines. Who is responsible for responding when a feature service or pipeline fails? Who is responsible for maintaining feature definitions when the underlying data changes? Who is responsible for managing data drift?
How are features shared today?
It’s important to keep in mind that for most businesses today, features are not shared at all! The status quo is that teams reimplement feature pipelines, creating large inefficiencies.
However, when successful feature reuse programs do materialize, we’ve seen them fall into roughly the following categories:
1. Write feature data to a published location
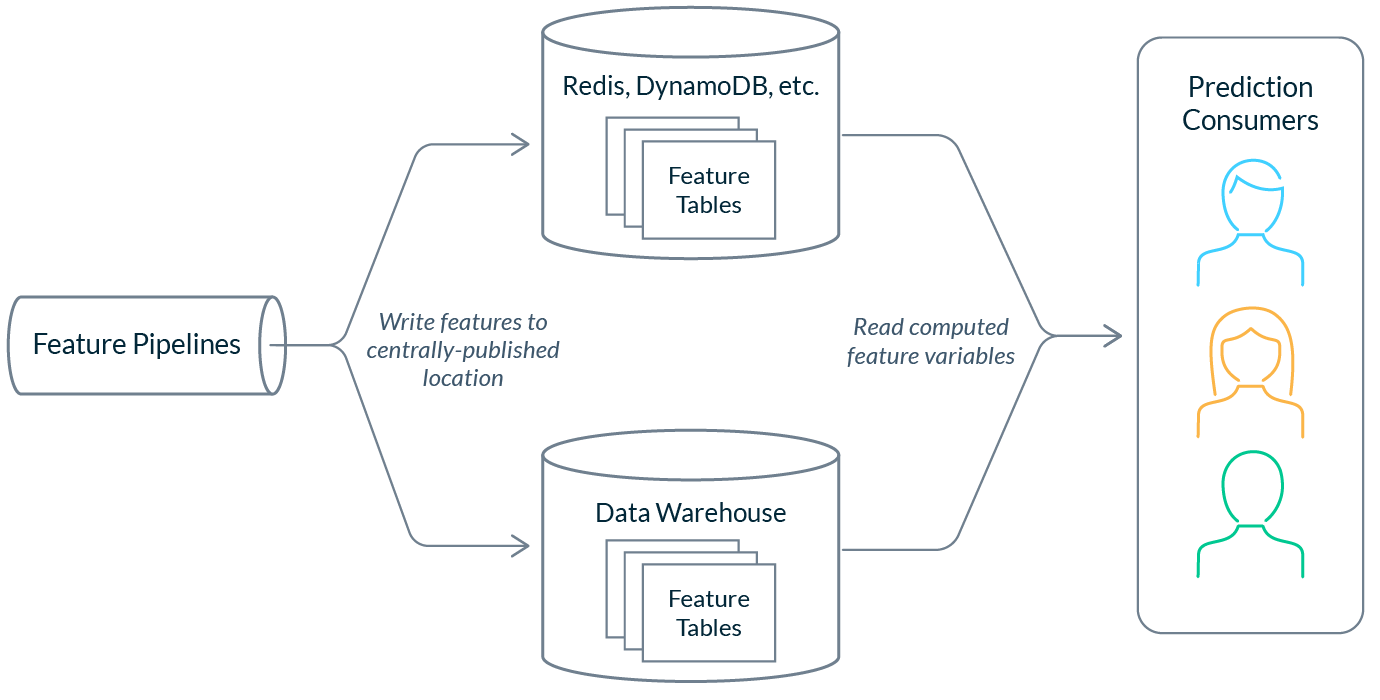
The simplest way to start sharing features is to begin publishing them to a location that is shared within the organization. For example, this could look like a set of feature pipelines that compute features and load them to data stores for offline and online consumption. In the example above, DynamoDB is used for online consumption and a data warehouse is used for offline consumption. In this pattern, feature pipelines are not exposed; only final feature values are available for consumption by consumers.
Because features are published in a location that is shared internally, teams can reuse features by simply reading them from data stores. This solution is often accompanied by internal references about the features which might live in a company’s wiki or engineering documentation.
When starting out, it’s common for these pipelines to be managed by just a single team (often, the team that was first to implement ML). However, this isn’t an effective long-term strategy as things scale, and teams end up quickly outgrowing this ownership model.
Pros:
- Easy to get started. Since most teams already have some form of this infrastructure set up, there’s a low barrier to sharing features in this manner. This is particularly the case for batch-only use cases (it’s common for teams to reuse their data lake or data warehouse for offline feature storage, but most teams spin up key-value stores specifically for online feature serving).
Cons:
- Not extensible. Adding new features to the system is not trivial. It’s especially hard for consumer teams to modify what’s running in production because they might not even have write access to the tables. Since pipeline definitions are not exposed, teams who are primarily consumers may have to fight through red tape to make changes.
- Lack of pipeline visibility. In this model, the source code for feature pipelines is not exposed. This means that teams must rely on metadata stored in external systems (such as wikis or data catalogs) and cannot build trust by inspecting pipelines directly.
- Poor knowledge curation. Because metadata is not coupled directly with the storage system, those seeking to reuse features may not even know where to go to find information about them. It’s also common for wikis to go stale; this problem is exacerbated by the size of the company.
2. Share feature pipelines
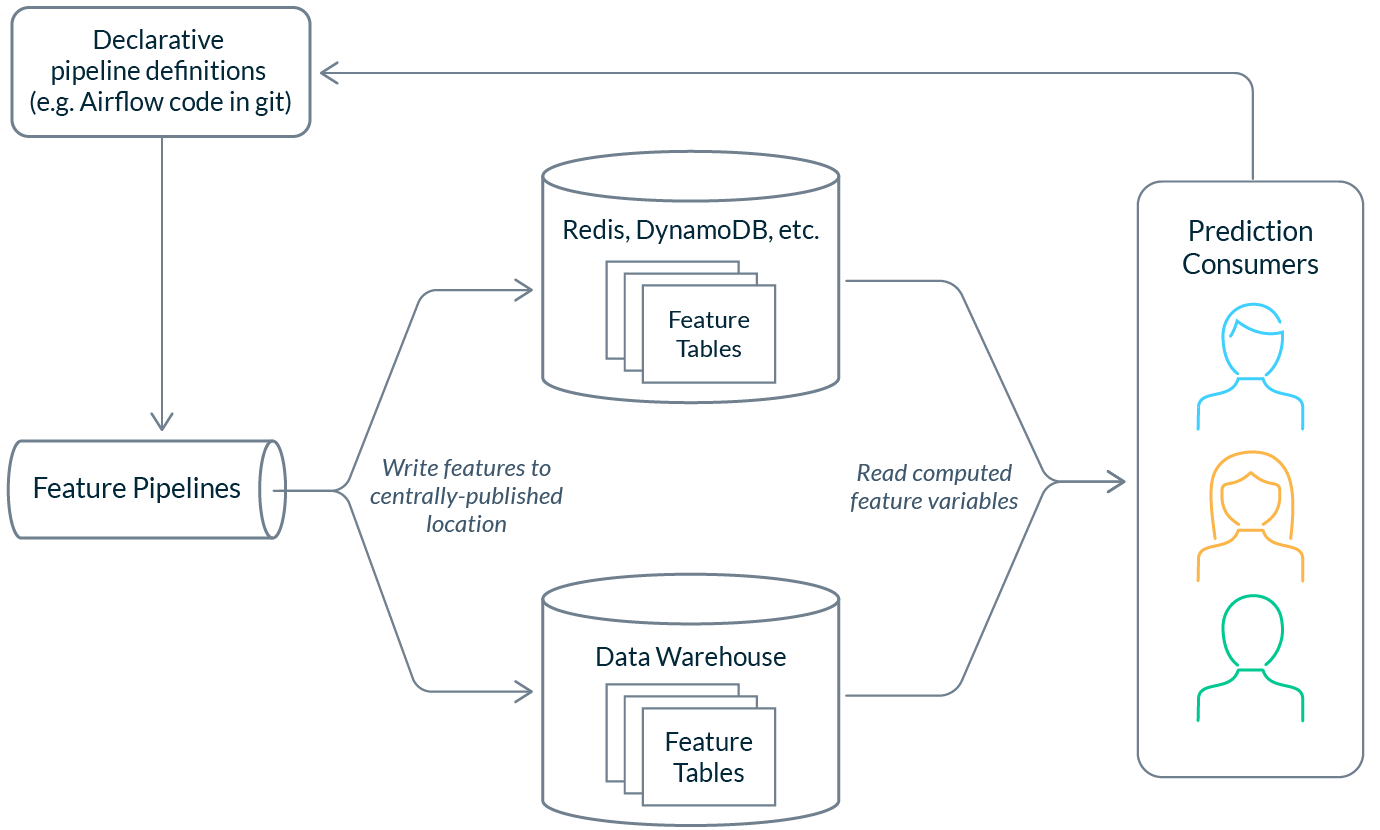
As ML complexity grows in an organization, teams begin to want to author and modify feature definitions easily. Organizations commonly solve this problem by sharing the source code of pipelines that produce feature values. Practically, this might look like sharing code via tools like dbt or Airflow in a git repository that is deployed via CI/CD.
Architecturally, this pattern looks similar to the previous setup: pipelines are published to different data stores. The key difference here is that the pipeline source code is exposed in an open and extensible way. This empowers individuals and teams to contribute to, fork, or otherwise modify the pipeline code to suit their needs.
Pros:
- Increased flexibility. Sharing pipeline code allows users and teams to contribute to feature definitions without going through any hurdles to get access.
- Pipeline visibility. Teams can inspect the pipelines that are producing features and build trust in features much more easily, which spurs reuse.
Cons:
- Monolithic pipelines. Feature pipelines are rarely designed to be incremental. This means that data scientists often fork large upstream pipelines to make small changes. This increases complexity and creates waste.
- Risk of pipeline failure. By sharing pipeline definitions, teams create dependencies on each other. Teams may step on each other’s feet when changing feature definitions, leading to outages or silent failures.
3. Feature Store
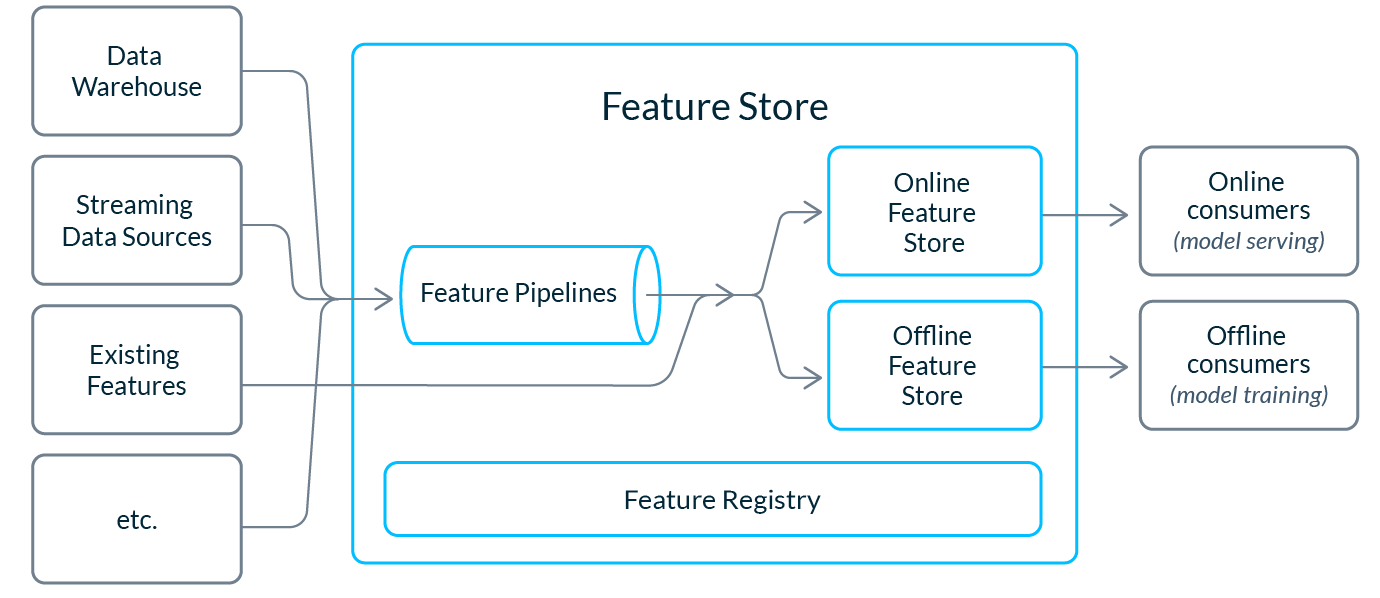
Organizations that are eager to derive significant value from operational ML are investing in feature stores. At Tecton we define a feature store as a system that manages the complete feature lifecycle through feature definition, transformation, storage, serving, monitoring, and sharing. The three components of feature stores that are most relevant to feature reuse are:
- Feature storage: Feature stores automatically manage the storage and consumption of features across the online and offline environments, so users don’t need to think about implementation nuances when reusing existing features.
- Feature registry: A feature store contains a centralized source of truth for standardized feature definitions and metadata. This feature registry is a key component of a reuse program as it enables curation and search, allowing teams to find relevant features for their new use cases. Many feature stores also explicitly track ownership and consumption dependencies.
- Feature transformations: Feature stores can optionally provide a system to define transformations (along with features and existing data pipelines) in a high-level language such as Python or SQL. Not all feature stores contain transformations.
The goal of implementing a feature store is to allow data teams to easily author the features needed to support their use case without modifying existing infrastructure or services running in production.
Pros:
- Consistently find data in offline and online environments. A feature store provides a standardized interface for accessing features, which significantly increases discoverability. Once a user finds a relevant feature, the feature store provides a consistent way to access it in both offline and online environments without needing to think about the underlying storage or serving infrastructure (e.g. the user doesn’t need to know where to find the feature in Dynamo vs. S3).
- Robust metadata management via the feature registry. The metadata management that a feature store provides can make it much easier to find and discover relevant features. Feature stores keep track of metadata that is important for reuse, such as release state (“experimental”, “production-ready”, etc.), the entities the feature was based on, and feature lineage. Feature registries are much less likely to go stale than wikis, since feature metadata is stored in code and automatically recorded when possible.
- Trust-building via pipelines and lineage inspection. Since pipelines and feature lineage are available for inspection through the feature store, it’s easy for teams to build trust in the features they plan to reuse.
- Extensibility and modularity of features. The pipelines that are running within feature stores are purpose-built for modularity. Most feature stores allow you to easily fork and extend features without affecting the pipelines that are currently running in production. This allows new features to be written without creating risks of outages, allowing a wider variety of features to be reusable.
Cons:
- Hard to build. Feature stores can take years to reach maturity if built internally.
How should you share features?
All organizations have different needs, so an approach that works for one organization may not work for another. Here are some questions that might help you decide on the right feature sharing system:
How siloed or centralized should your features be?
In certain industries, like financial services or insurance, fine-grained ACLs on feature definitions are required. It’s also the case that in some organizations, features are less widely applicable across teams. In these situations, storing feature values in a general table in a data warehouse will not meet requirements.
How important is feature sharing?
Some organizations really may only have one or two marquee machine learning use cases. In these situations, simply sharing feature data across models might be a good enough solution for feature reuse.
How mission-critical is your ML system?
Mission-critical applications such as pricing and credit judgments typically require a system with operational stability. Certain practices, like sharing raw pipeline code, may not be suitable. In theory, feature stores prevent this by tracking breaking changes and consumption dependencies, but not all feature stores provide these benefits.
—
At Tecton, we spend a lot of energy thinking about how teams can robustly reuse features, and we think feature stores are a great solution for a wide variety of reuse scenarios. If you’d like to get started with a lightweight, open source feature store, try Feast. For a fully-managed feature store, check out Tecton by signing up for a free trial today.