What Is a Feature Platform for Machine Learning?


Up until two years ago, only giant technology companies had the resources and expertise to build products that fully depended on machine learning systems. Think Google powering ad auctions, TikTok recommending content, and Uber dynamically adjusting pricing. To power their most critical applications with machine learning, these teams built custom infrastructure that met the unique needs of deploying machine learning systems.
Fast forward a few years and an entire ecosystem of MLOps tools have sprung up to democratize machine learning in production. But with hundreds of different tools out there, understanding what each of them does is now a full-time job. Feature platforms and their related cousin, feature stores, are a popular part of that ecosystem. In a nutshell, a feature platform enables your existing data infrastructure (data warehouses, streaming infrastructure like Kafka, data processors like Spark/Flink, etc.) for operational ML applications. This post explains in more detail what feature platforms are and what problems they solve.
Building operational machine learning is tough
Feature platforms enable operational machine learning (ML), which happens when a customer-facing application uses ML to autonomously and continuously make decisions that impact the business in real time. The examples I shared from Google, TikTok, and Uber are all operational ML applications. Any machine learning project always consists of four stages:
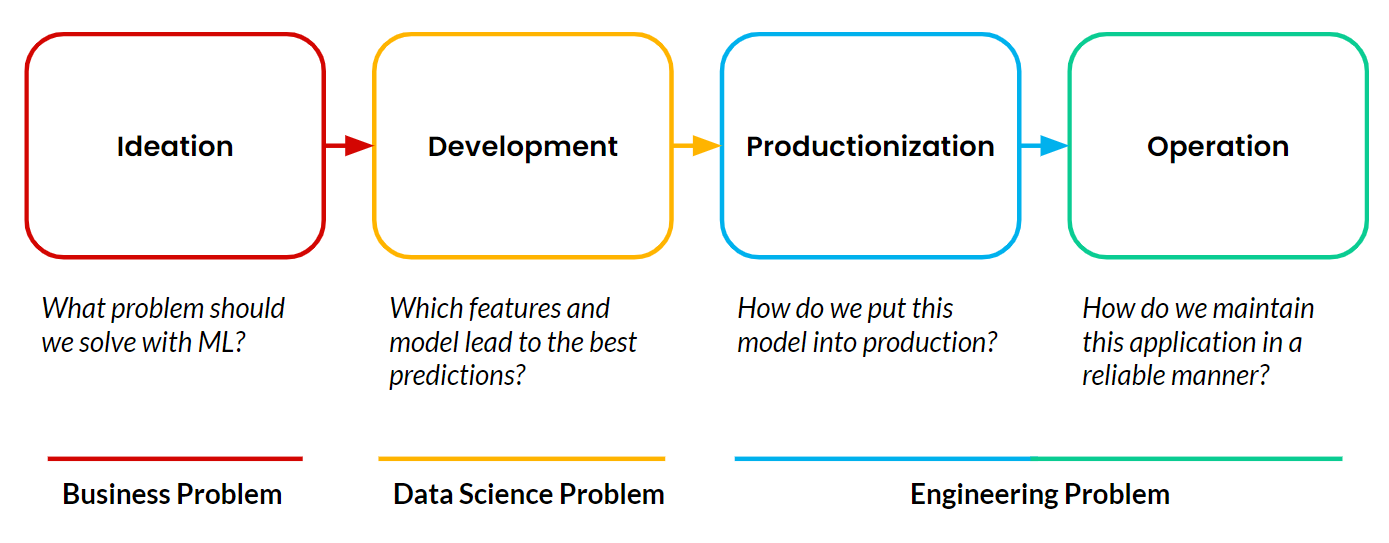
Most projects never make it past the development stage. Productionizing and operating machine learning applications remain the main blocker for teams. And the most difficult part of productionizing and operating ML is managing the data pipelines that need to continuously feed these applications.
A feature platform solves the data challenges associated with productionization and operation. It creates a path to production. We’ll get into the specific of what this means, but let’s first describe what a feature is.
What is a machine learning feature?
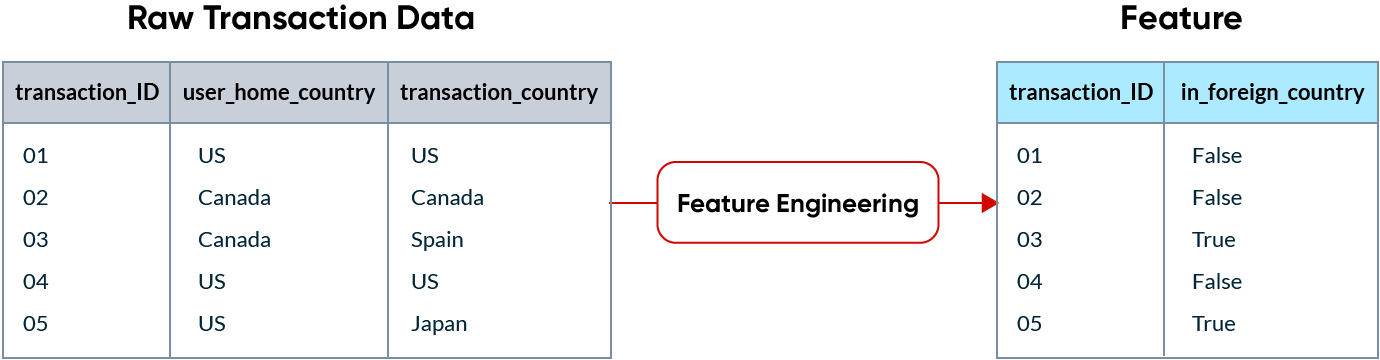
In machine learning, a feature is data that’s used as the input for ML models to make predictions. Raw data is rarely in a format that is consumable by an ML model, so it needs to be transformed into features. This process is called feature engineering.
For example, if a credit card company is trying to detect fraudulent transactions, a transaction being made in a foreign country might be a good indicator of fraud. Features end up being columns in the data that is sent to a model.
What’s unique about ML is that features are consumed in two different ways:
- To train a model, we need large amounts of historical data.
- To make a live prediction, we need to provide only the latest features to the model, but we need to provide that information within milliseconds. This is also called online inference. In this example, the model only needs to know whether the current transaction is in a foreign country or not, and it needs to process that information while the transaction is happening.
What problems does a feature platform solve?
In the development stage of a machine learning project, data scientists do large amounts of feature engineering to find the features that lead to the highest prediction accuracy. Once that process is complete, they usually hand off the project to an engineering colleague who will put those feature engineering pipelines into production.
If you’re a data scientist, you don’t want to be concerned about how the data becomes available or how it is computed. You know which features you want, and you want those features to be available for the model to make live predictions. Engineers, on the other hand, need to re-implement those data pipelines in a production environment, which quickly becomes very complex as soon as there’s real-time or near-real-time data involved. To power operational ML applications, these pipelines need to run continuously, can’t break, need to be extremely fast, and need to scale with the business.
Re-implementing data pipelines into a production environment is the main blocker for operational ML projects. Going back to the fraud detection example, realistic features that companies will implement are:
- Distance between a user’s home location and the location where the transaction is happening, computed as the transaction is occurring.
- Whether the current transaction amount is more than one standard deviation higher than the historical average at that merchant location.
- A user’s number of transactions in the last 30 minutes, updated every second.
These feature engineering pipelines are difficult to implement. They can’t be computed directly on a data warehouse, and they require setting up streaming infrastructure to process data in real time. A feature platform solves the engineering challenges of putting these features into production and, in doing so, creates an easy path to production. Concretely, a feature platform:
- Orchestrates and continuously runs data pipelines to compute features and makes them available for offline training and online inference.
- Manages features as code, allowing teams to do code reviews, version control, and integrate feature changes into CI/CD pipelines.
- Creates a library of features, standardizing feature definitions and enabling data scientists to share and discover features across teams.
Let’s dive deeper into how users interact with a feature platform and what its components are.
What is a feature platform?
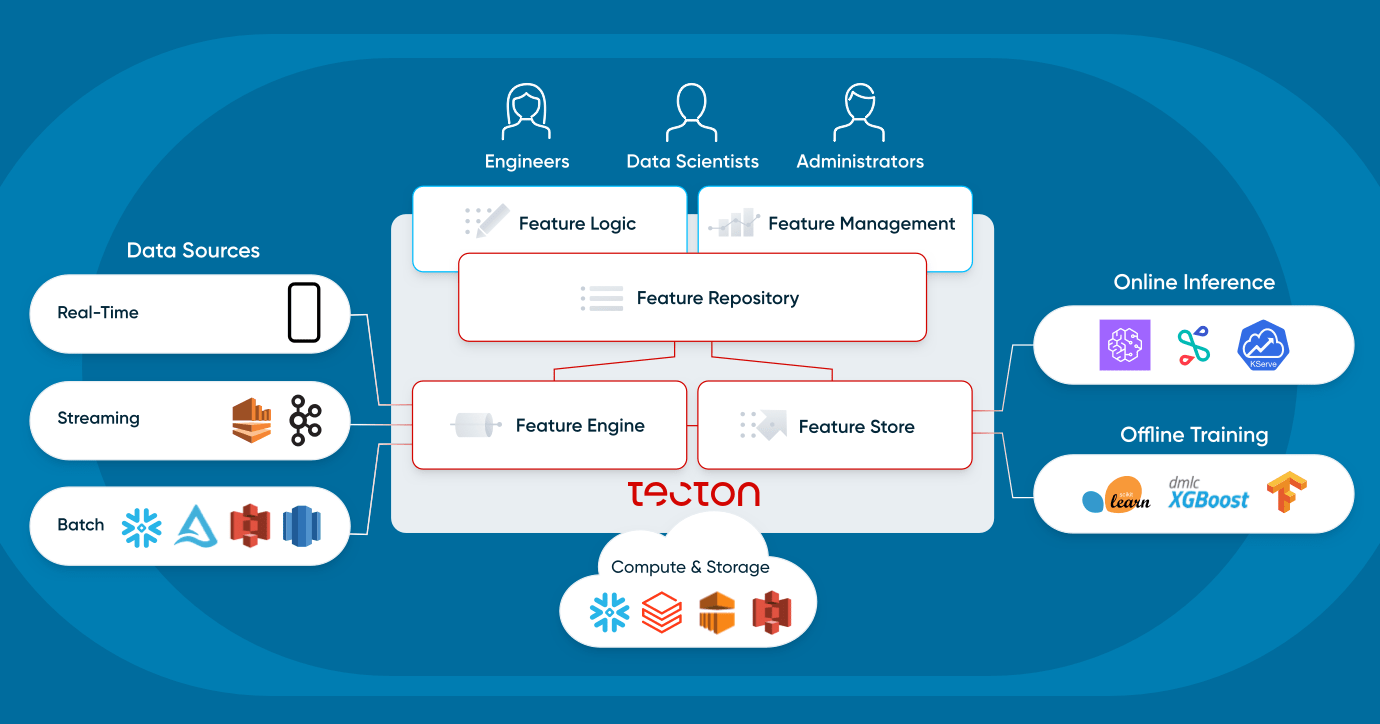
A feature platform is a system that orchestrates existing data infrastructure to continuously transform, store, and serve data for operational machine learning applications.
There are two main ways in which users interact with a feature platform:
- Feature creation and discovery
- Users define new features as code in Python files using a declarative framework. Feature definitions are managed in a git repo.
- Users discover existing features that other teams have defined.
- Feature retrieval
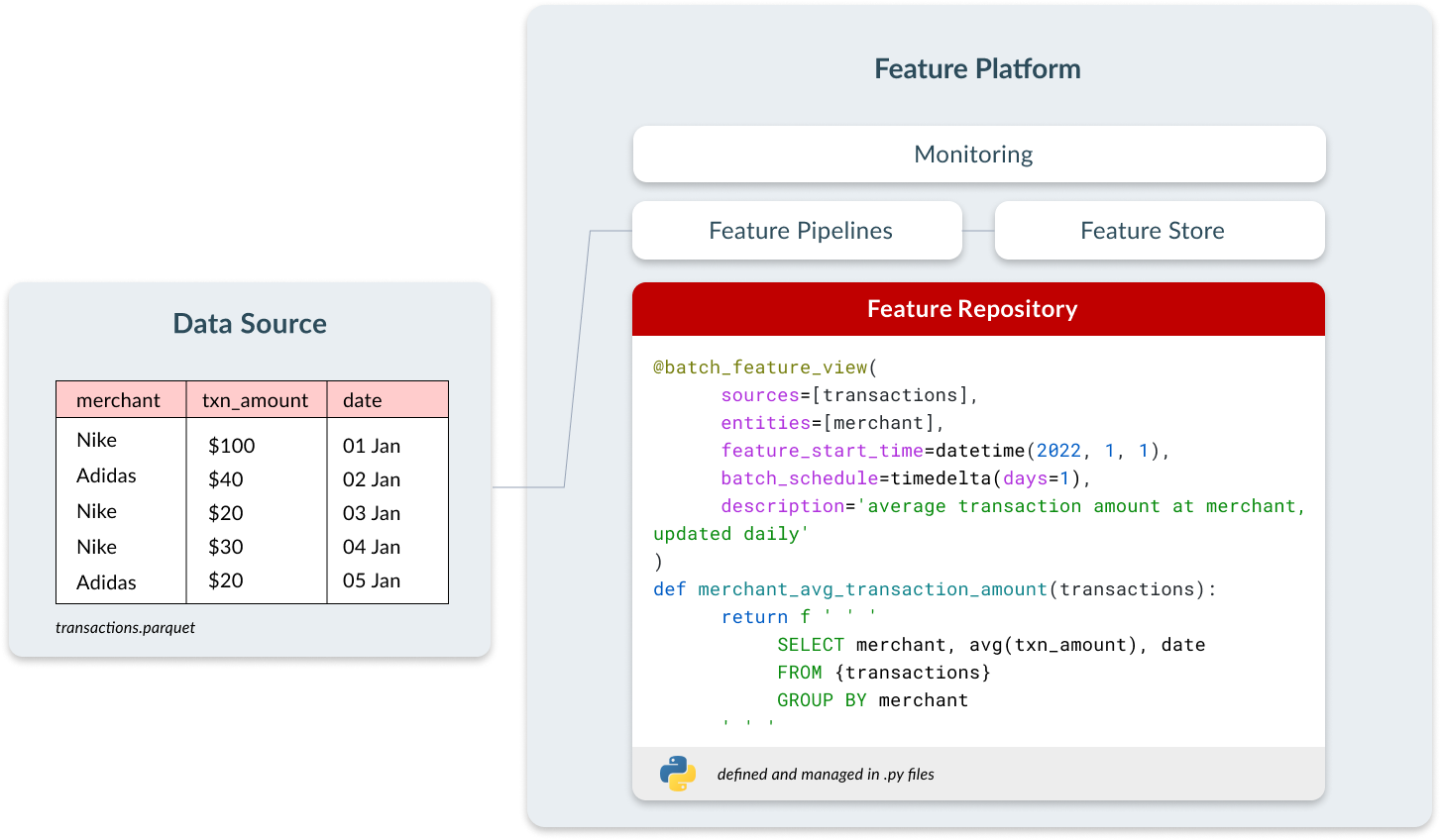
- At training time, users can call the feature platform within a notebook to get all the historical data they need to train a model. This can be done with a call such as get_historical_features(fraud_model). The feature platform handles the complexity of backfilling features and doing correct point-in-time joins, and the resulting data frame can be ingested by any model training tools, such as XGBoost, Scikit-learn, etc.
- For inference time, the feature platform exposes a REST endpoint that can be called by a live application. This returns the latest feature vector for a given entity ID in milliseconds that the model will use to make a prediction.
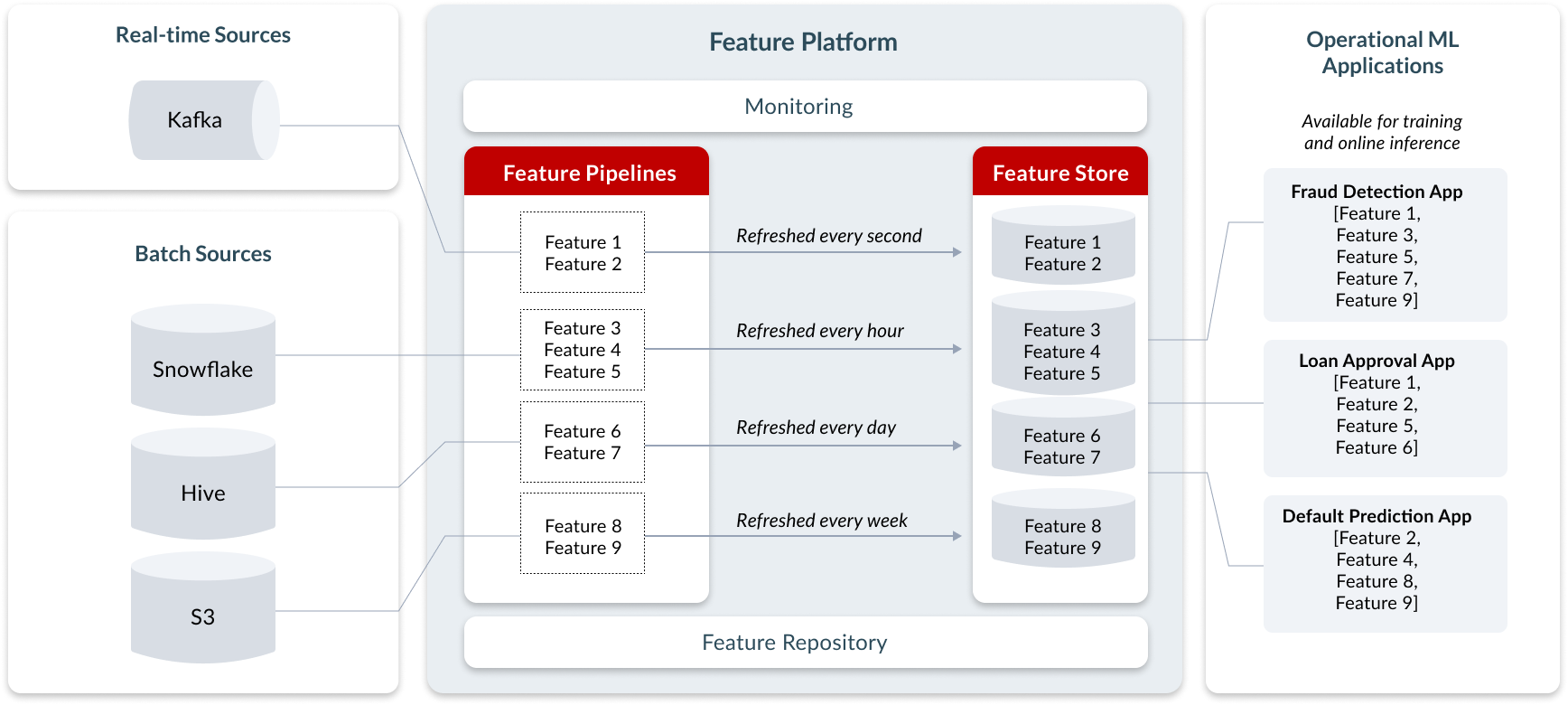
Feature platforms do not replace existing infrastructure. Instead, they enable existing infrastructure for operational machine learning applications—they connect to (1) batch data sources such as data lakes and data warehouses, and (2) streaming sources like Kafka. They use (3) existing compute infrastructure, such as a data warehouse or Spark, and (4) existing storage infrastructure, such as S3, DynamoDB, or Redis. A modern feature platform flexibly connects to an organization’s existing data infrastructure.
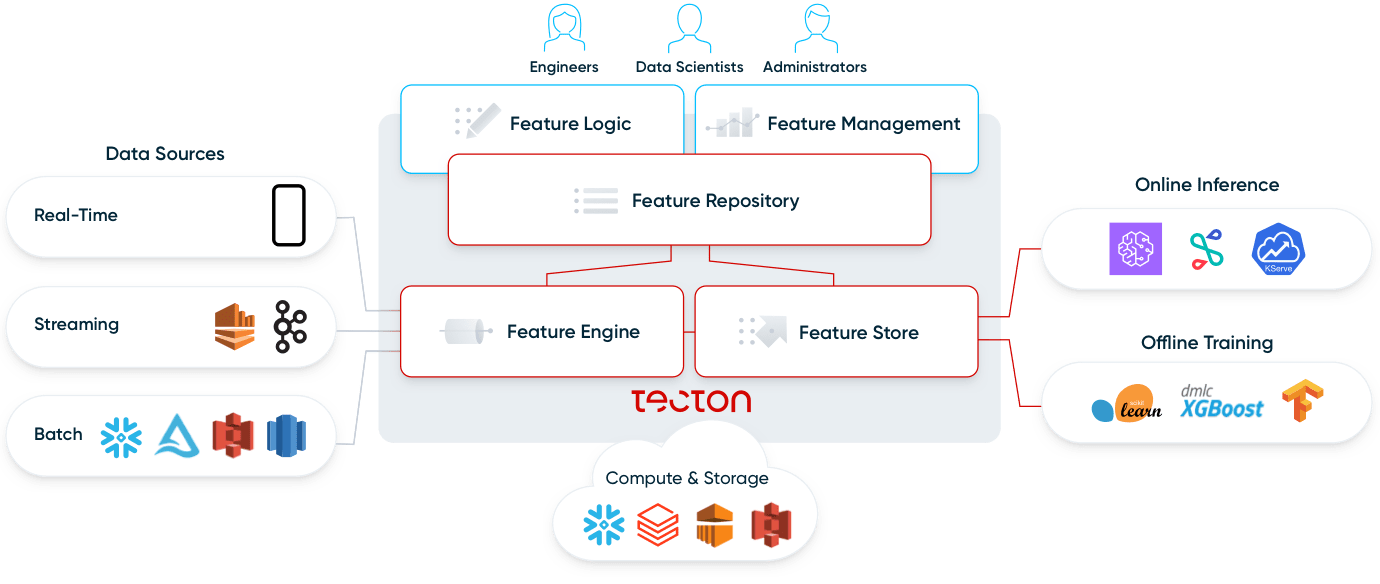
Let’s take a deeper look into the four components of a feature platform: feature repository, feature pipelines, feature store, and monitoring.
Feature repository
Many data scientists do their feature engineering in notebooks. They’re interactive, easy to use, and lead to fast development cycles. The pain begins when those features need to make it into production; it’s impossible to integrate them into CI/CD pipelines and have the controls that we employ with traditional software.
Teams that successfully deploy operational ML applications manage their features as code assets. This brings all of the benefits of DevOps — it enables teams to do code reviews, track lineage, and integrate into CI/CD pipelines, resulting in teams shipping changes faster and more reliably. A common symptom of teams that don’t manage features as code is that they’re often unable to iterate past the first version of a model.
In a feature platform, users define features as code using a declarative interface that contains three elements:
- Configuration about how often the feature should be computed.
- Metadata, such as the feature name and description, to enable sharing and discoverability.
- Transformation logic, defined in SQL or Python.
These features are then available centrally for all teams to discover and use in their own models. This saves development time, creates consistency between teams, and saves on compute costs since features don’t need to be computed multiple times for different use cases.
Feature pipelines
Operational machine learning applications require continuous processing of new data so models can make predictions using an up-to-date view of the world. Once a user has defined the feature in the repository, the feature platform will automatically process the data pipelines to compute that feature.
There are three types of data transformations that a feature platform must support:
| Transformation | Definition | Data source | Example |
|---|---|---|---|
| Batch | Transformations that are applied only to data at rest | Data warehouse, data lake, database | Average transaction amount per merchant, updated daily |
| Streaming | Transformations that are applied to streaming sources | Kafka, Kinesis, PubSub, Flink | Number of user’s transactions in last 30 minutes, updated every second |
| On-demand | Transformations that are used to produce features based on data that is only available at the time of the prediction. These features cannot be pre-computed. | User-facing application, APIs to RPC Services, In-Memory data | Is the current transaction amount more than two standard deviations higher than the user’s average transaction amount, computed at the time of transaction |
These transformations are executed on data processing engines (Spark, Snowflake, Python) to which the feature platform is connected to. The feature platform passes the user-defined transformation code 1:1 to the underlying data processing engine. This means that the feature platform should not have its own custom SQL-dialect or custom Python DSL. This both simplifies the onboarding experience to the feature platform, as well as the debugging experience.
Batch transformations are simple to execute — they can be executed through a SQL query against a data warehouse or by running a Spark job. Operational ML applications, however, benefit the most from fresh information that can only be accessed through streaming and on-demand transformations. In the fraud detection example, features that will enable the model to make the best prediction will contain information about the current transaction, such as amount, merchant, and location, or information about transactions that happened within the last few minutes.
Every team we talk to agrees that having access to fresh data would improve the performance of the majority of their models. Most organizations are still using batch transformations only because managing streaming and on-demand transformations is complex. A feature platform abstracts that complexity away, allowing a user to define the transformation logic and select whether it should be executed as a batch, streaming, or on-demand transform.
When iterating on new features in the development stage, data needs to be backfilled to generate training data sets. For example, we might develop a new feature merchant_fraud_rate today, which will need to be backfilled for the entire time window we want to train the model on. Feature platforms run these transformations automatically when defining new features, enabling fast iteration cycles in the development process.

Feature store
Feature stores have become increasingly popular since we first introduced the concept with Uber Michelangelo in 2017. They serve two purposes: to store and serve features consistently across offline training and online inference environments.
When features are not stored consistently across both environments, the features the model is trained on might have subtle differences from the features it uses for online inference. This phenomenon is called train-serve skew, and it can derail a model’s performance in silent and catastrophic ways that are extremely difficult to debug. By having consistent data in both environments, a feature store solves this problem.
For offline training, feature stores need to contain months’ or years’ worth of data. This is stored in data warehouses or data lakes like S3, BigQuery, Snowflake, or Redshift. These data sources are optimized for large-scale retrieval.
For online inference, applications need to have ultra-fast access to small amounts of data. To enable low-latency lookups, this data is kept in an online store like DynamoDB, Redis or Cassandra. Only the latest feature values for each entity are kept in the online store.

To retrieve data offline, feature values are commonly accessed through a notebook-friendly SDK. For online inference, a feature store delivers a single vector of features containing the most up-to-date data. While the amount of data in each of these requests is small, a feature store must be able to scale to thousands of requests per second. These responses are served in milliseconds to live applications through a REST endpoint. Performant feature stores must provide SLAs on availability and latency.
Monitoring
When something goes wrong in an operational ML system, it’s usually a data problem. Because feature platforms manage the process from raw data to models, they are uniquely positioned to detect data problems. There’s two types of monitoring that feature platforms support:
Data quality monitoring
Feature platforms can track the distribution and quality of incoming data. Are there significant shifts in the distribution of the data since we last trained the model? Are we suddenly seeing more missing values? Is this impacting the model’s performance?
Operational monitoring
When running production systems, it’s also important to monitor operational metrics. Feature platforms track feature staleness to detect when data is not being updated at the expected rate, along with other metrics related to feature storage (availability, capacity, utilization) and metrics related to feature serving (throughput, latency, queries per second, error rates). A feature platform also monitors that feature pipelines are running jobs as expected, detects when jobs are not succeeding, and automatically resolves issues.
Feature platforms make these metrics available to existing monitoring infrastructure. Operational ML applications must be tracked like any other production applications, which are managed with existing observability tools.
Bringing it all together
Part of the magic of a feature platform is that it allows ML teams to quickly productionize new features. But the explosion in value happens when the feature platform is being used by multiple teams and powering multiple use cases.
A feature platform allows data engineers to support a larger number of data scientists than they otherwise could. We’ve talked to many teams who needed 2 data engineers to support 1 data scientist without a feature platform. A feature platform allowed them to more than flip that ratio. Once a feature platform has been adopted widely, data scientists can easily add features that are already being computed into their models. We’ve seen the same pattern repeat itself: teams take a few months to fully deploy their first use case, a few weeks for the second use case, and only a few days to deploy new use cases or iterate on existing use cases after that.
When (and when not) to adopt a feature platform
I began this article by describing how difficult it is to keep up with the entire ecosystem of MLOps tools that have emerged in the past few years. The reality is that you should keep your stack as simple as possible and only adopt tools when they’re truly necessary.
We see teams find value from a feature platform when they:
- Have experienced the hand-off process between data scientists and data engineers and the pain associated with re-implementing data pipelines for production.
- Are deploying operational machine learning applications, which need to meet strict SLAs, achieve scale, and can’t break in production.
- Have multiple teams that want to have standardized feature definitions and want to re-use features across models.
Teams should avoid adopting a feature platform when they:
- Are in the ideation or development phases, and not ready to ship to production.
- Have only a single team working only with batch data.
How to get started
There are a few options to get started:
- Tecton is a managed feature platform. It includes all of the components described above, and our customers choose Tecton because they need production SLAs and enterprise capabilities, without the need of managing a solution themselves. Tecton is used by ML teams ranging from tech startups to multiple Fortune 500 companies.
- Feast is the most popular open source feature store. It’s a great option if you already have transformation pipelines to compute your features, and want to store and serve those features in production. Over time, Feast will continue adding feature pipeline and monitoring capabilities that will make it a complete feature platform.
I wrote this blog post to provide a common definition of feature platforms as they are now consolidated as a core component of the stack for operational machine learning applications. If you want to keep learning more about feature platforms and operational ML, you can sign up for our monthly newsletter, where we share the latest news, events, and product updates.
Also, if you’re interested in learning about a fraud detection use case firsthand, you won’t want to miss this live webinar, where Hendrik Brackmann, VP Data at Tide, will share how using a feature platform solved critical challenges on their path to deploying real-time models for fraud detection and credit approval decisions.


