Maintaining Feature Pipelines With Automated Resolution of Compute Failures



Customers rely on Tecton for providing uninterrupted access to their machine learning features. Tecton orchestrates and manages the data pipelines that compute these features, insulating the end user from their complexity. However, the pipelines run user-provided transformation code on cloud infrastructure (AWS), which opens them up to a wide range of failure scenarios. In this post we describe why the jobs that compute feature pipelines might fail, and how we built a solution to either automatically resolve these issues or surface alerts so users can directly intervene when automation is impossible. We finish the article with an example of how this system works in a real-world deployment with one of our customers.
The problem
How hard could it be to keep track of a few daily ETL pipelines computing ML features? Not too difficult. What if the pipelines run hourly, to make features fresher? Multiply by 24. What if your data science team is experimenting with dozens of feature variants—which is very easy to do in Tecton—and want the features to update in minutes, and not hours? We’re now talking about hundreds of hourly jobs.
When a job fails, features are no longer being updated, and stale features will negatively impact the user’s experience.
Examples of real-world failures:
- org.postgresql.util.PSQLException: ERROR: permission denied for relation trips
- AWS_INSUFFICIENT_INSTANCE_CAPACITY_FAILURE(CLIENT_ERROR): aws_api_error_code:InsufficientInstanceCapacity, aws_error_message:There is no Spot capacity available that matches your request.
- An error occurred while trying to determine the S3 bucket’s region com.amazonaws.services.s3.model.AmazonS3Exception: Access Denied (Service: Amazon S3; Status Code: 403; Error Code: AccessDenied;
- Lost task 0.0 in stage 3.0 (TID 6) (ip-10-38-2-182.us-east-2.compute.internal executor 2): java.util.concurrent.ExecutionException: java.lang.IllegalArgumentException: Unsupported json type for string: NUMBER
Types of failures
There are several types of failures that we have observed:
- Failure to allocate cloud instance
- Termination by a cloud provider, which is quite frequent for cheaper Spot instances
- Data volume spikes causing jobs to have OOM errors
- Configuration changes, e.g., permissions revocation
- Human errors in transformation code
Failures fall into two categories – transient and permanent. A job that failed transiently (examples 1 and 2 above) will usually succeed upon a retry. Permanent failures are going to persist across retries, until some additional intervention is made, e.g., switching to a bigger instance for OOM errors, adjusting ACLs, or fixing the feature definition code.
We aggregated long-term data from one of our customers and found that, out of tens of thousands of jobs, 3.7% had transient failures and recovered automatically, while only 0.5% of jobs had permanent failures.
The feature platform approach
At Tecton, we work closely with our customers to ensure that feature data is being computed reliably, and the importance of reliability only grows with the maturing ML use cases that we power. As we grow the number of subsystems that we support (Spark, Snowflake, Kafka, among others), the complexity of use cases, and our customer base, the volume of job failures will increase as well.
A fully manual system would quickly overwhelm the DevOps team. Who wants to be woken up by on-call alerts just to click “retry” or see the job recover on its own? We needed an automatic solution to deal with most of those failures. But certain types of failures are impossible to resolve without manual work, so we also knew that we had to build a solution that combined automatic and manual interventions. We ended up developing a system to triage failures using a hybrid of automatic and manual recovery steps.
The naïve solution would be to automatically retry transient failures and alert the user about permanent failures, but the reality is not that simple.
Handling failures
Even transient failures may have permanent periods. For example, a shortage of instances in the Spot marketplace results in repeated Spot terminations before the job has a chance to complete. Eager retrying leads to excessive compute costs and doesn’t even fix the problem. In this case, a better strategy is to either (1) wait before retrying, or (2) switch to a non-Spot instance at a higher cost. The decision between the two is not trivial and depends on how important the feature is and how problematic it would be if it becomes stale.
Reversely, a permanent data access error due to permission revocation might be resolved quickly by the user, and thus behaves like a transient error.
Therefore, we don’t attempt to exhaustively categorize all errors into transient and permanent. We use a heuristic where we increase the delay between retries and cap the total number of retries. After several failures—let’s call that number N—but before reaching the cap, we send an alert to the user. The user has a chance to remedy the problem, for example by updating data or job ACLs, and let the retrying strategy do the rest.
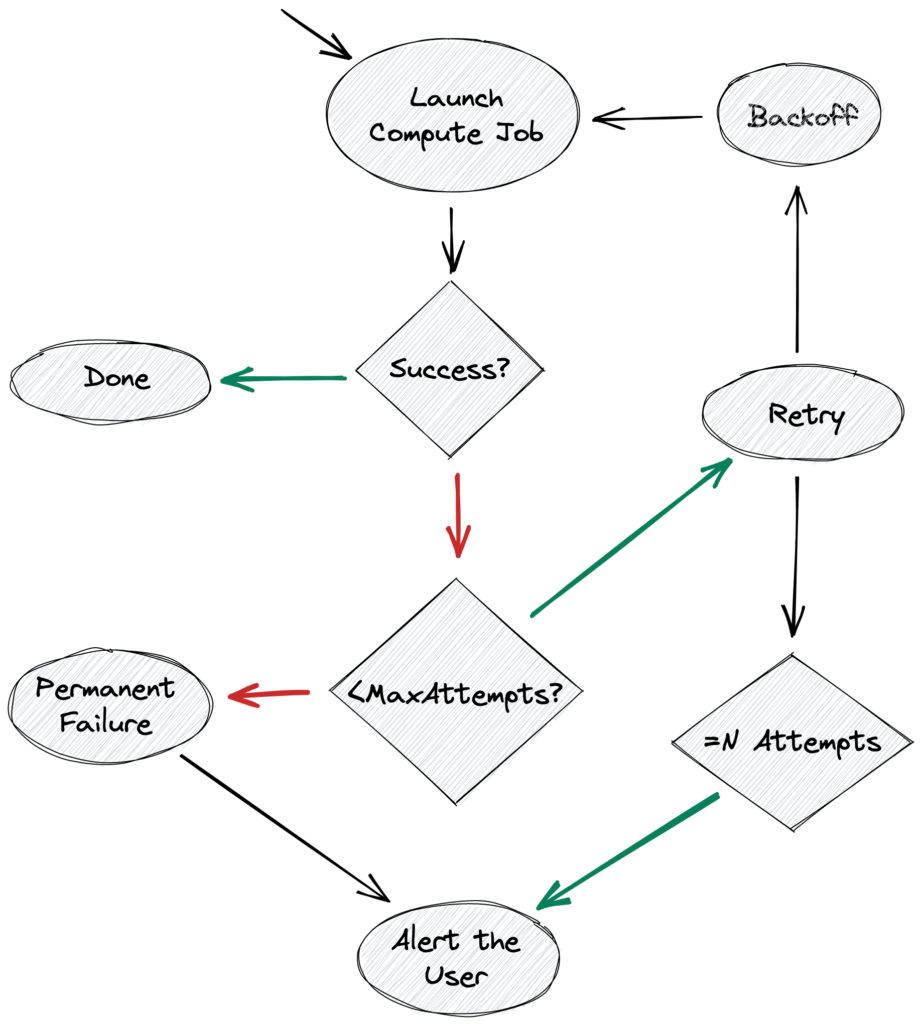
Transient failures. Here is an example job status page where the last two jobs have recovered from transient errors:
Permanently failed jobs. When the cap is reached, the job is moved into a permanent failure state, where it won’t be retried automatically anymore. We proceed to alert the user, and whenever the underlying problem is resolved the job is unblocked manually.
Here is an example job status page with a job being retried and a permanently failed job:

We are continuing to iterate on the retrying and alerting strategy, and plan to expose more of its knobs to our users.
Prevention
Finally, we provide an easy way to look at the history of compute jobs. Our users can look for recent failures and come up with prevention measures. For example, by defaulting to a different instance type with more memory, tweaking ACL policies, or documenting quirks of a data table that requires special handling in transformation code.
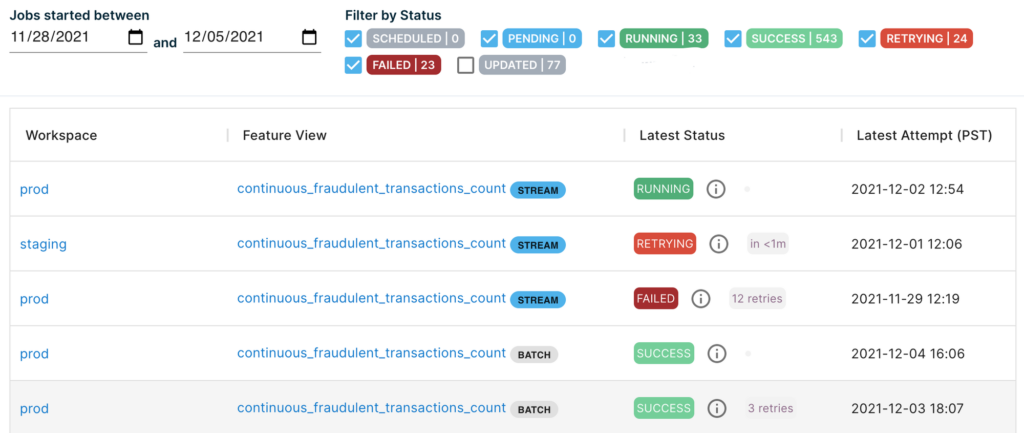
Here is an example of how that history page looks like:
Our system in practice
Here is an example of how this system works in practice, from an actual customer deployment. Our customer had a job failure, was informed via automated alerting and quickly intervened and corrected the issue. No intervention from Tecton’s support team was required.
- T: A change on the customer side revokes data access permission from compute jobs run by Tecton
- T+1: The first data permission error causes job failure
PSQLException: ERROR: permission denied for relation trips - T+2: After N unsuccessful retries an alert email is sent to the customer; features are becoming stale
- T+3: The customer fixes the permission issue
- T+4: The current back-off period expires and the job is retried
- T+5: The job succeeds; features are fresh again
Conclusion
At Tecton, we are solving real, technical challenges at the forefront of ML systems. If you’re interested in learning more about the work we do, or want to come work on exciting problems with us, check out our careers page. We’re hiring!