Serving 100,000 feature vectors per second with Tecton and DynamoDB



There is a class of Machine Learning models that require real-time data to make predictions – the process by which these models make predictions is known as Online Inference. Examples of these types of models are models that detect fraudulent credit card activity at the time of purchase or make purchasing recommendations based on a customer’s recent browsing history. The speed with which features are served to the model is of the utmost importance.
Tecton is a feature store that is built to pull in data from a variety of sources (batch and streaming) and serve those features to production models. In this blog post we’ll benchmark Tecton’s online feature serving capabilities, and show how Tecton is able to serve feature values at low latency (<< 100ms) even at very high load (> 3 million DynamoDB requests per second)
Tecton Terminology
As we review the results of our benchmarks there are some Tecton specific terms that need to be described:
Feature View – A Feature View encapsulates a data source, transformation logic and information about how often to refresh the feature. There are Feature Views for Batch and Streaming data sources as well as Feature Views that are specific to deriving aggregates from the data sources. The features used for online serving are by default stored in a DynamoDB table on AWS (other options are available). More details on Feature Views can be found in our documentation.
On Demand Feature View – A unique type of Feature View is the On Demand Feature View. It’s different from the other feature views in that the end result isn’t precomputed and stored in a DynamoDB table. Rather, as the name implies, this feature is calculated on demand at the time of the feature request.
Feature Service – A grouping of all the Feature Views necessary for a model. Typically there is 1-1 mapping between a Feature Service and a model. The Feature Service is accessed via an HTTPS Rest endpoint. Additional details can be found in our documentation.
How are features served in Tecton
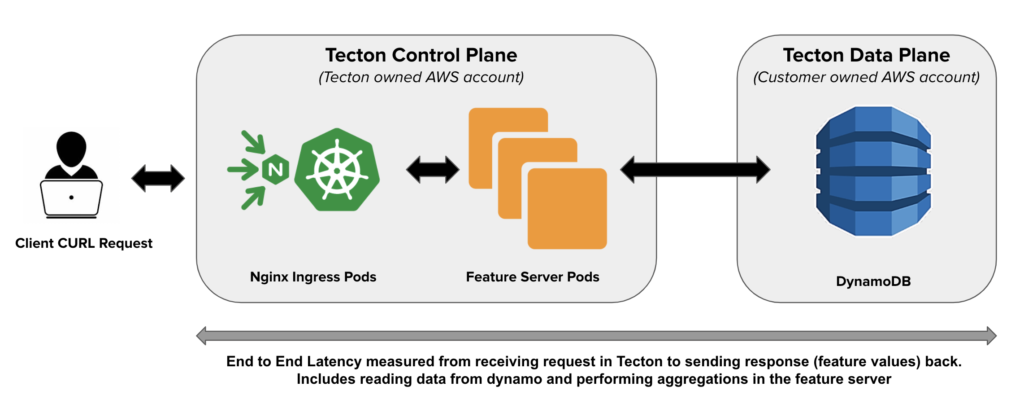
Tecton is deployed in a Hybrid SaaS model. There is a control plane that runs in Tecton’s AWS account, and a data plane that lives in the customer’s AWS account. When a request for a feature service is made it interacts with our control plane which consists of an Nginx ingress layer backed by our feature serving application that is deployed on Kubernetes. This application then makes the request for data that is in DynamoDB (typically in the customer’s account). The Feature Servers are stateless and do not share state. This allows us to scale out the Feature servers horizontally to handle large QPS. The primary responsibility of feature servers is serving data from DynamoDB after filtering and aggregations at low latency.
One important note to make is that one Feature Service request can result in many requests to DynamoDB. As an example if a feature service has 50 Feature Views then the 1 feature service request results in 50 underlying requests to DynamoDB. These details are noted in our results section when we differentiate between feature service queries per second (FS-QPS) and the resulting DynamoDB queries per second (DDB-QPS).
Test Data
As discussed in a previous post, Tecton uses a “tiling” mechanism for computing aggregate features. The size of the aggregation window impacts serving latency.
For the following scenarios we retrieved a variety of features. These features were a combination of sum-aggregations and simple look up features.
| Feature Type | Number of Features |
| Non- Aggregate | 1250 |
| 28 Day Aggregate | 1250 |
| 7 Day Aggregate | 1250 |
| 1 Day Aggregate | 1000 |
| 356 Day Aggregate | 250 |
| Total: | 5000 |
Results
Scenario 1
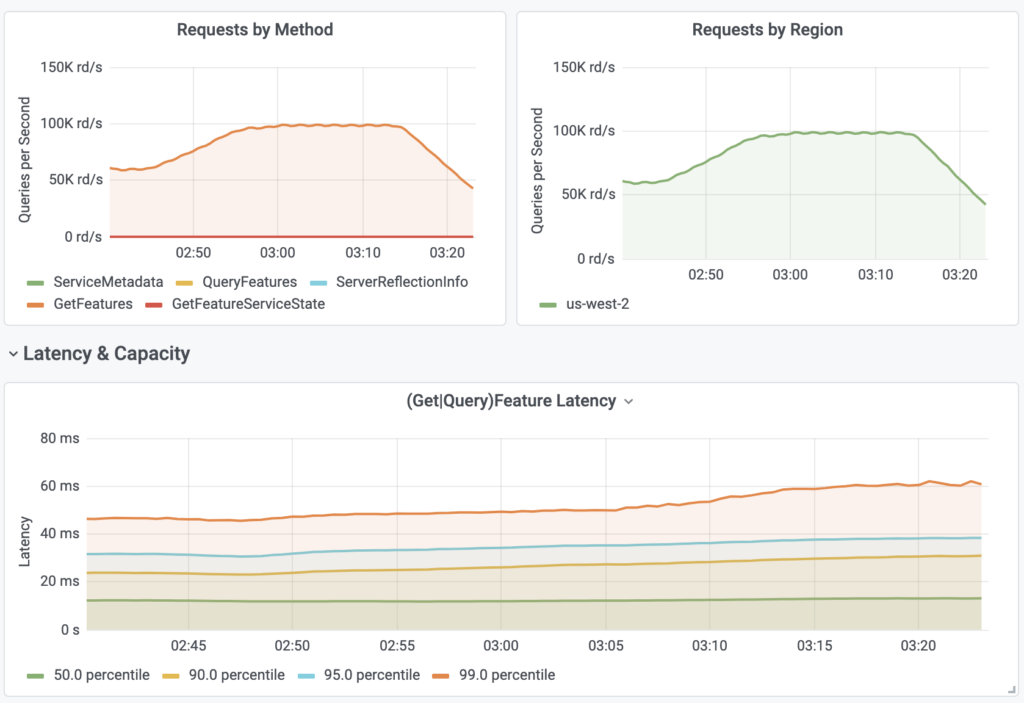
The first scenario targeted multiple Feature Services with a varying number of Feature Views and total features.
| FS-QPS | # of Feature Views | DynamoDB Tables | DDB-QPS | # of Features | |
| Feature Service 1 | 60,000 | 50 | 50 | 3,000,000 | 5000 |
| Feature Service 2 | 20,000 | 5 | 5 | 100,000 | 500 |
| Feature Service 3 | 20,000 | 10 | 10 | 200,000 | 1000 |
| Total: | 100,000 | 65 | 65 | 3,300,000 | 6,500 |
Latency
| P-Value | Observed Latency |
| p50 Latency | 14ms |
| p90 Latency | 28ms |
| p95 Latency | 37ms |
| p99 Latency | 55ms |
Availability

Scenario 2
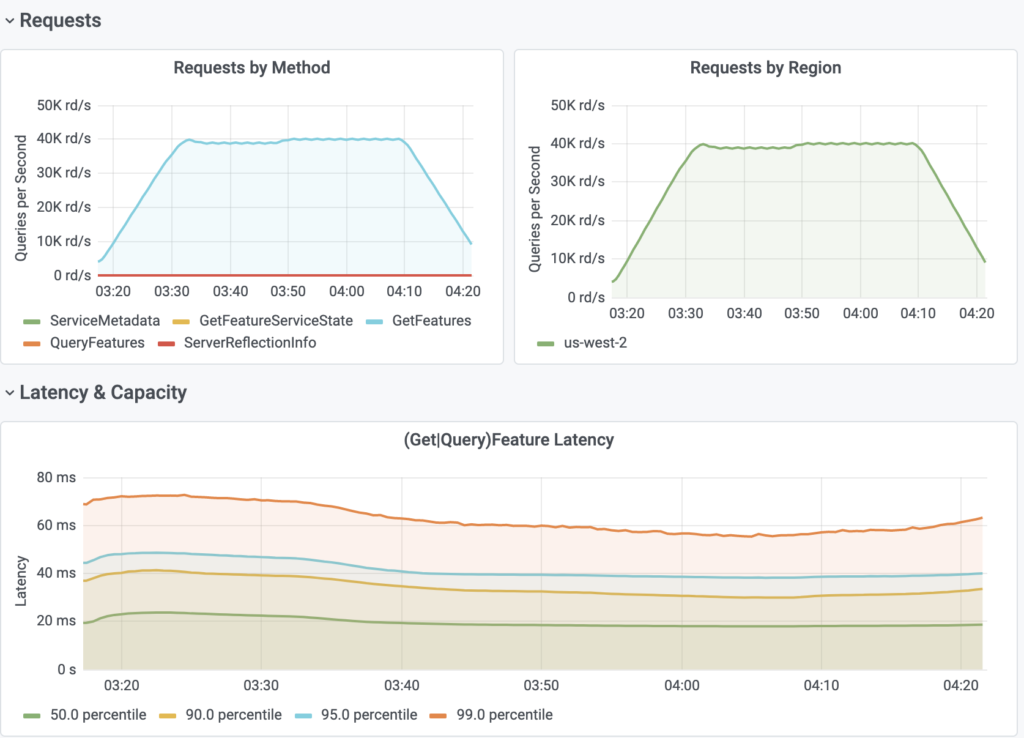
Scenario 2 tested our On Demand Feature View. As noted earlier this type of Feature View does not rely on DynamoDB to store the computed value as the value is computed at the time of request.
The On Demand Feature View was written in Python and calculated the Jaccard Similarity between two sets of data. The data in the two sets was the result of two queries to the same datasource with different primary keys. The Jaccard Similarity was then calculated On Demand for these two sets of data. The primary keys were randomly selected to ensure that the same query wasn’t repeated.
| # of Feature Views | # of Features | DynamoDB Tables | DDB-QPS | FS-QPS | |
| Feature Service 1 | 1 | 1 | 0 | 0 | 40,000 |
Latency
| P-Value | Observed Latency |
| p50 Latency | 20ms |
| p90 Latency | 35ms |
| p95 Latency | 40ms |
| p99 Latency | 70ms |
Availability

Conclusion
Reviewing the results we can notice that in all use cases latency was under 75ms per request. We can also appreciate the fact that the error rates were < 0.00001% meaning that in a test where we’re doing 100,000 queries per second we can expect a single digit failure rate (~99.9999 availability). With these details we can see that Tecton meets its stated SLA’s (p99 < 100ms and 99.9% uptime) under a variety of high load scenarios.
Tecton is built to scale to the volumes needed by the largest and most sophisticated ML organizations on the planet. At Tecton we continue to push the boundaries of scale and performance to achieve lower latency. We are currently working on adding support for other stores like Redis which will further lower our p99 latency and provide lower total cost of operations. We will be following up with those numbers in a future blog. If you’re curious to try Tecton out for yourself, check out tecton.ai.