Real-Time Aggregation Features for Machine Learning (Part 2)



Solution: Tiled Time Window Aggregations
Part 1 of this blog series discussed the importance of time window aggregations for ML use cases. In the following sections, we describe an approach to solving these challenges that we’ve proven out at scale at Tecton, and that has been used successfully in production at Airbnb and Uber for several years. The discussed approach explains Tecton’s implementation which relies entirely on open source technologies.
At a high level, the solution breaks the time window aggregation over one full-time window up into a) several compacted tiles of smaller time windows that store aggregations over the tile interval, and b) a set of projected raw events at the head and tail of the aggregation time window. The compacted tiles are pre-computed. At feature request time, the final feature value is on-demand computed by combining the aggregations stored in the tiles as well as aggregations over the raw events:

Feature Configuration
The configuration of these tiled time window features requires the following details:
- The selection and projection of raw events from one or several raw event sources
- The aggregation definition of those projected events
The aggregation definition of those projected events
Tecton allows users to select and project events using SQL. The query allows the user to select the raw source(s), strip the raw events of all unnecessary data, and perform in-line transformations. An example transformation may look like this:
select
user_uuid,
amount,
timestamp
from
TransactionsThis SQL can typically be executed natively by a stream processor like Apache Spark or Flink. Tecton by default uses Spark Streaming in continuous mode.
Aggregation Definition
Tecton allows users to define the aggregation information using a simple DSL. Following the example above, the user may want to create several sum aggregations over the amount column:
aggregation_type: sum
aggregation_column: amount
time_windows: 2h, 24h, 48h, 72hYou can browse our docs to see a real-world example of such a feature definition in Tecton. The definition above is enough to orchestrate a set of ingestion jobs that load the newly defined feature into the online and offline feature store.
Streaming Ingestion to the Online Store

Tecton uses Spark Structured Streaming to write recent data from a streaming data source into the Online Feature Store. The user’s SQL transformation is applied to the streaming input to project the events and strip them of all data that is unnecessary. The result is written directly to the Key-Value store with no further aggregation.
By default, we use DynamoDB as the online store (with Redis as a supported alternative).
Batch Ingestion to the Online and Offline Store

Streaming Ingestion only forward-fills recent events from the streaming source to the online store. Everything else is the responsibility of offline batch ingestion jobs. This includes:
- Backfilling and Forward-filling the offline store
- Backfilling the online store
Batch ingestion also uses Spark but in batch mode rather than streaming mode. The batch jobs read from a batch source that is the streaming source’s offline mirror (e.g. a Hive or DWH table) and are expected to contain a full historical log of the streamed events. Tecton uses Delta Lake as the default offline store (with data warehouses as a supported future alternative).
Compaction of raw events to tiles
So far, we have only talked about writing raw events straight to the online or offline store. Of course, this naive implementation by itself could lead to unacceptably high query latencies in the online serving path. A lot of data may be required to serve an aggregation, particularly in the case of long aggregation windows or a data source with a high volume of updates. This could have serious consequences for the latency of the serving path, similar to querying a transactional store directly in production. In order to mitigate this problem, you need to periodically compact raw events into tiles of different interval lengths (Footnote: An efficient compaction implementation can also compact tiles of smaller granularity into tiles of larger granularity).
The result is that the online and offline feature store will contain two different categories of data:
- Uncompacted data: A projection of the raw events
- Compacted data, which is the result of compacting one compaction interval worth of data using the user-configured aggregation operations. In practice, typical compaction intervals are 5min as well as one “long” interval that spans the longest complete multi-day tile for a given aggregation window
The uncompacted data are produced as part of the regular flow described in the Batch/Streaming ingestion sections above. Compacted data is produced by a separate periodic batch Spark job that reads from the streaming source’s offline mirror:

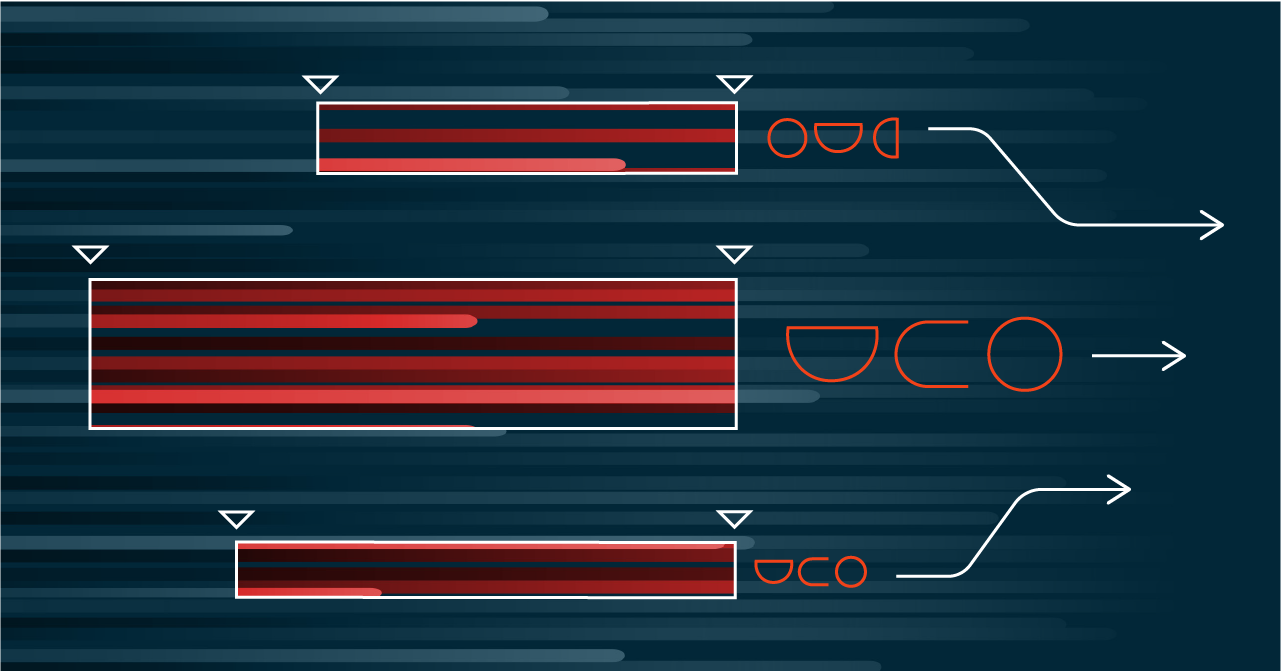
At offline or offline serving time, a mix of uncompacted and compacted data must be fetched from the store, as can be seen in the following diagram:

As can be seen in the figure, compacted rows are fetched for the middle of the aggregation range. In general, there will be time ranges at the head and tail of the aggregation which are only a partial part of a compacted row, and for these, we fetch uncompacted rows to complete the aggregation. This optimization reduces the worst-case number of rows that have to be fetched from the offline or online store.
Note:
The blog has so far addressed solving the problem of serving ultra-fresh feature values (<1s). As a result, it’s required that you stream a projection of raw events into the store. The curious reader may have noticed that you could already write pre-computed tiles, instead of raw events, to the online and offline store. In this case, the tile length defines the ultimate freshness of the feature: The larger the interval, the lower the guaranteed feature freshness. Further, the tile length controls the write-frequency to the store: The larger the interval, the lower the write-frequency. At the limit, you can choose a tile size of “None”, which results in a write to the store for every event, resulting in maximal freshness and the highest write-load. Therefore, the minimal tile size really gives the user a knob to tune the cost/freshness-tradeoff of a given feature.
Online Serving
During online serving, the Feature Server receives a request containing the join keys to be retrieved. From these join keys Tecton generates an online store query for all of the data for the given join keys in the time range [Now – (aggregation time window), Now). This results in a series of compacted tiles as well as raw events, which are then aggregated by Tecton’s Feature Server to produce the final feature value.
Offline Serving
Offline Serving requests consist of a DataFrame with the following columns:
- Join Key Value(s)
- A Timestamp. Unlike Online Serving which always aggregates as of the current time, Offline Serving requests are able to aggregate as of a different time for each row. This is an important capability for generating training data sets and providing point-in-time correctness via time travel.
The Offline Serving process is similar to the Online Serving process, except that it is executed as a batch Spark query.
Advantages Summary
To conclude, the discussed implementation provides the following benefits:
- Backfilling is now solved as the discussed solution allows you to backfill from the batch source and forward-fill from the event stream
- Long-running time windows are easily supported
- Ultra-fresh features are supported, because, at request time you can always take into account events that have been streamed into the store up until the very moment of the prediction
- Compute and Memory-cost efficient processing:
- You only write updates to the store when new events come in and when you write tiles to the store
- You only compute tiles – not complete time windows. The former is cheaper and requires a smaller memory footprint
- Compute and Storage-efficient processing of multiple time windows:
- You can recombine tiles into time windows of varying length: e.g. you can store 1h tiles, and you can get 2h, 12h, 24h, 7d, etc. aggregations without materializing the full-time windows in the store
- Fast feature retrieval: Both offline and online, you don’t aggregate (only) raw events at request time. You aggregate over precomputed tiles, making the whole operation faster
Deep Dive on Advanced Performance Optimization: Sawtooth Window
By Nikhil Simha (Airbnb)
As discussed above, the concept of combining precomputed tiles with projected raw events was pioneered by the team behind Airbnb’s Zipline. The next iteration of this approach is what they have called Sawtooth Windows.
One implication of the aforementioned approach is that the online store has to keep raw events at the tail of the window, as well as for the entire window to facilitate the sliding of the window forward with time. As windows get larger(180d+) this becomes a storage scalability bottleneck.
To avoid this bottleneck, you can slide the head of the window, but hop the tail of the window (tile-by-tile). The implication of this is that the window size varies with time by the hop size. Not all workloads can tolerate this variation, but in Airbnb’s experience, machine learning applications tolerate this pretty well – and maybe even benefit slightly due to the regularizing effect of this noise in feature data.
A 30day window with a 1-day hop would only need to store 30 daily partial aggregates(tiles) and 1 day’s worth of raw data. Previously, Airbnb stored 30 days worth of raw data to facilitate the sliding of the tail of the window. This is an order of magnitude reduction in storage requirement for raw data.
As a consequence, the actual window length varies between 30days to 31days. We call these windows “Sawtooth Windows”: A hybrid of hopping and sliding windows with low space requirements and high freshness. By simply allowing windows to vary in length by a small fraction of their defined size it’s possible to improve storage size and latency simultaneously without affecting freshness.
Conclusion
In sum, we’ve shown how you can solve an extremely common and challenging ML feature type by combining pre-computed data assets with an on-demand transformation in a performant, cost-efficient as well as online/offline consistent way. The curious reader may have realized that this pattern of combining pre-compute with on-demand-compute can be generalized beyond just time-window aggregations and extend to completely user-defined transformation steps. This generalized approach allows you to finally express computation DAGs that span the analytical offline world, as well as the operational online world:

In a future blog series, we’ll discuss the benefits and possibilities of this powerful DAG concept, and how you can use Tecton today if you want to take advantage of it for your ML application. If you’re curious to learn more about the technical details of this implementation, feel free to shoot us a Slack message here.
A note on other technologies: What we’ve described above, is of course not a completely novel implementation. We describe the common process of “view materialization” and show how it can be implemented using open source streaming/batch processing technologies that can plug directly into an organization’s existing key-value store as well as an existing offline store (like a data lake or data warehouse). Tools like timescaledb, ksqldb, materialize, or Druid, take advantage of a similar strategy. You may be able to build your application directly on top of these tools depending on your existing stack, your willingness to introduce a new storage technology, your need for a consistent offline and online store, and your need to efficiently backfill your features from a batch source.
It’s also worth noting that the solution above solves for the constraints laid out in the introduction, which are commonly found in high-value operational ML applications: feature aggregations over a lot of raw events (> 1000s), that need to be served at a very high scale (> 1000s QPS), at low serving latency (<< 100ms), at high freshness (<< 1s), and with high feature accuracy (e.g. a guaranteed and not approximate time window length). Simpler versions of the architecture discussed above can be used if some of those constraints do not apply to your use case. Ping us on Slack to discuss in more detail.