Building Production-Ready Machine Learning Features on Snowflake with Tecton’s Feature Store




We are excited to announce the integration of Tecton’s enterprise feature store and Feast, the popular open source feature store, with Snowflake. The integration, available in preview to all Snowflake customers on AWS, will enable data teams to securely and reliably store, process, and manage the complete lifecycle of machine learning (ML) features for production in Snowflake.

Tecton allows data teams to define features as code using Python and SQL. Through our integration with Snowpark for Python, currently in private preview, users are able to run transformations in Snowflake to get the performance, ease of use, governance, and security of the Data Cloud regardless of language.
Data Challenges in Production ML
To build an ML application, you first need to transform raw data into features. Those features need to be served consistently for model training and inference, whether that happens in batch or in real time for use cases such as recommendations in an ecommerce website or fraud detection.
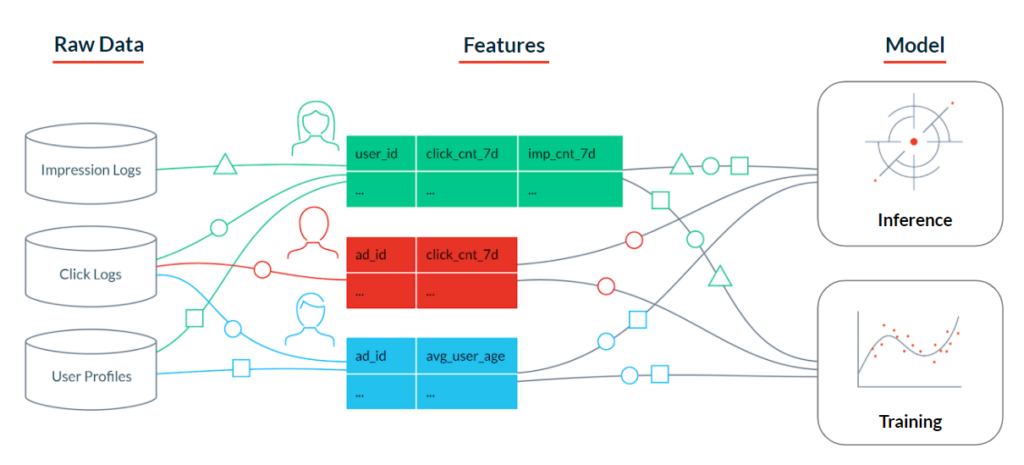
Data scientists will often do exploratory analysis and feature engineering in local notebooks. While notebooks are great for fast experimentation, they can be extremely challenging for engineers who later need to put that code into production. Under this workflow, organizations lack standardized definitions for features and have no central source of truth. Without a better solution, engineering teams often re-engineer data science code into production pipelines to feed machine learning models. Teams end up with two distinct pipelines, duplicating work and increasing complexity.
When it comes to generating data for training, data scientists need to construct complex queries to ensure data is joined correctly. Data leakage, a problem unique to machine learning, is often introduced in this process. Data leakage occurs when the dataset used for model training contains information that will not be available to a model at the time of prediction, leading to poor model performance in production.
Discrepancy in how data is handled for training and serving pipelines introduces training-serving skew. This becomes even more prevalent as organizations transition from batch to real-time model inference. Without a cohesive platform, teams have to maintain consistent definitions and processing of features while managing integrations between multiple tools to handle things like batch processing, orchestration, online retrieval, and offline storage.
Tecton + Snowflake
Tecton serves as the interface between your Snowflake data and your model training and serving environments.

Centralize feature logic and simplify feature management
With Tecton, users define and manage features as code using a declarative framework. Features are written in Python or SQL and live in a Git repository so features can be treated as any other code assets: they can be version controlled, unit and integration tested, and deployed through CI/CD processes. Users can also observe lineage and discover features through a web interface. For training and batch inference, features are stored and processed in Snowflake to maintain consistent governance and security of your data.
Fast and accurate retrieval of training data sets of any size
Users can leverage Snowflake’s powerful processing engine to make training datasets instantly available for any number of features across millions of rows with only two lines of code via Tecton’s Python SDK. Tecton guarantees features are joined with point-in-time correctness to eliminate data leakage.
Incorporate real-time data into production without training-serving skew
In addition to making batch features available for online consumption in a low-latency store, Tecton also builds pipelines that can automatically process raw data and serve features in real-time. In Tecton, real-time feature transformations are defined using Python. With Snowpark for Python, users are able to efficiently execute those same transformations in Snowflake to build training datasets.
Feast, the open source feature store, now also supports Snowflake natively and serves as the interface between Snowflake and your ML models. To learn more about the important differences between Tecton and Feast, check out our comparison page.
Get Started
To learn more about how you can use Tecton with Snowflake, check out our tutorial and sign up for our preview:
If you’re interested in an open source solution, see our tutorial for an example Feast project using Snowflake.