Tecton: The Data Platform for Machine Learning



Today, Jeremy Hermann, Kevin Stumpf and I are excited to introduce Tecton, the company we founded just over a year ago. Tecton’s mission is to make it easy and safe to put machine learning into production to power smart product experiences. This means bringing the best practices of machine learning development to everyone, and enabling every team to build with the speed, trust, and power of the industry’s most capable applied ML organizations.
Our founding team met at Uber, where we created Michelangelo, the internal platform for building, deploying, and managing ML systems in production. We worked with dozens of teams tackling hundreds of business problems with ML, from user experiences like ETA prediction to operational decisions like fraud detection. Across these efforts, we kept seeing the same pattern: data science teams would build promising offline prototypes, but would end up taking months (or quarters) of back-and-forth with engineering to actually get things fully “operationalized” and launched in production.
Michelangelo addressed these problems with its integrated feature store and model management systems. The platform connected a collaborative development environment with battle-hardened production infrastructure, enabling a Cambrian explosion of ML at Uber, where thousands of models and feature pipelines now run in production.
We’ve since heard from countless companies across a variety of verticals, and they all reference the same familiar pains with deploying ML. Some tech companies have developed custom internal solutions after wrestling with these problems for years. For everyone else, powering customer experiences in production with ML is still an extremely complex, expensive, and often insurmountable task. Most of that complexity originates in the data layer for ML (feature engineering, sharing, serving, monitoring, and much more), an area underserved by today’s ML tools.
That’s why we’re building Tecton, to make operational ML achievable for every organization. Tecton is an enterprise-ready data platform specifically built for ML, expanding on the ideas behind Michelangelo’s feature store. It accelerates and standardizes the data workflows that support the development and deployment of ML systems. The goal is to improve time-to-value, increase ROI on ML efforts, and fundamentally change how ML is developed within data science organizations.
Making machine learning operational
Machine learning has definitively left the lab and is now transforming how we develop software and what that software can do. It’s starting to power new customer experiences across nearly every industry, from predicting the availability of hospital beds to matching players of similar skill in online gaming. For high-value problems like recommendations, real-time pricing, personalized search, fraud detection, and supply chain optimization, ML is bringing step function improvements that weren’t possible with traditional software.
These examples represent operational uses of ML, which is new terrain for most software teams. Many teams have experience with offline, analytical uses of ML, which enable human decision-making through answering questions, generating insights, and exploring data. In contrast, with what we’ve begun to call “operational ML,” the goal is to enable machine decision-making. Operational ML drives systems that make automated decisions in the product to power the customer experience, at scale and in real-time.
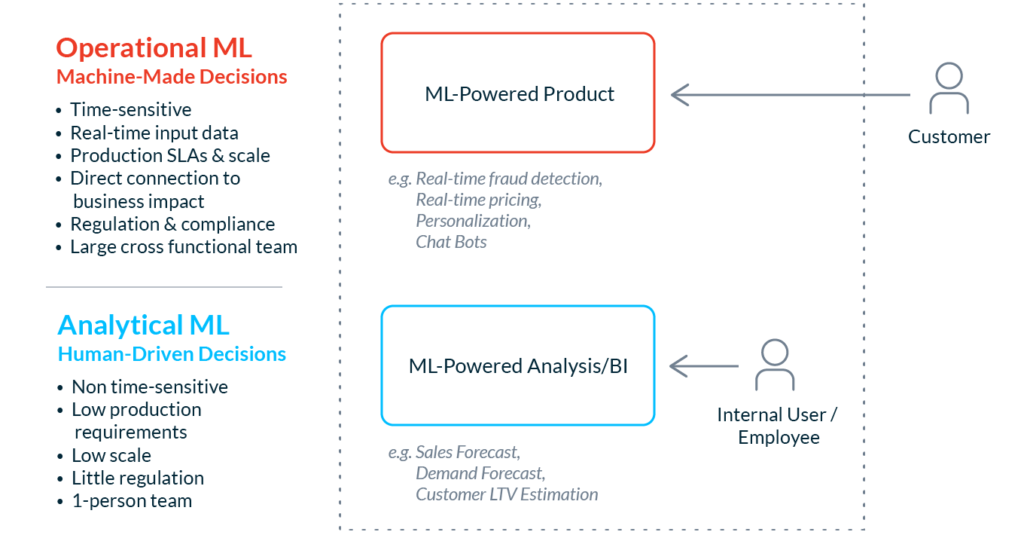
- Operational ML systems need to be battle-tested and fully productionized. These systems have production SLAs, and make predictions at low latency (<100ms) and high scale. They need to be thoroughly vetted to be trusted to drive the customer experience. They often require integration with multiple software components and collaboration across several development teams.
- Operational ML use cases need decisions now, not in a report next week. Dynamic prices, risk decisions, smart responses, and personalized experiences need to be generated and delivered in real-time. These models don’t have the luxury of time to wait for complete or corrected data. If something goes wrong, there’s no time to investigate and debug, so additional business logic (edge case handling, graceful degradation, etc.) needs to be deployed with the model.
- Operational ML use cases are high-stakes and affect the bottom line. The product use cases that require ML tend to be high-value and directly tied to revenue or cost savings. Performance issues have direct business impact. The behavior of these models drive the behavior of your product. Problems here mean costly mistakes and embarrassing customer experiences.
Operational ML represents uncharted territory for most organizations. Teams that haven’t historically been “machine learning teams” are now asked to deploy and manage ML in production. Teams that produce ML-powered analytics or insights are now asked to integrate those insights in the product directly. Teams that have historically defined system behavior with rules engines or other manually-authored decision-making logic are asked to replace it with ML.
These changes are happening fast, and they’re happening right now, because ML-driven user experiences are defining a new state-of-the-art for software products. The companies that are quick to adopt ML operationally are differentiating and building a sustainable competitive advantage.
Building operational ML systems is very hard today
Meeting the requirements for operational ML is an overwhelming challenge for most teams, despite the fact that data scientists are comfortable building models, and engineers deploy software daily. It’s new and it’s hard: The majority of ML projects never make it to production.
In our experience, there are several reasons why putting ML into production is so tough:
Development
Development and production environments are nothing alike. It’s hard to develop for an environment you can’t access, and data scientists can’t access production. They develop in isolated environments, often on their laptops, which are quite different from the environments in which their ML applications will run (e.g. different data, hardware, service integrations, etc.). It’s trivially easy and very common for these differences to render features or models completely useless operationally.
Constraints from existing infrastructure and tools stifle ML impact. Operational ML efforts tend to require non-trivial engineering work, and data scientists constantly face limiting technical constraints from engineering, e.g. “only use data from this source,” or “you can’t use these libraries.” Such constraints, and the high effort needed to overcome them, force data scientists to operate within a limited solution space. Without a path to deploy the optimal solution, projects tend to “overfit” on what’s easy to support right now and miss opportunities for long-term impact.
Deployment
Operational ML deployments are complex. Deploying ML applications requires the synchronized deployment of multiple artifacts: not just code (e.g. the business logic surrounding the application), but also the model and the data. Such multi-artifact deployments complicate the requirements around versioning, logging, auditability, reproducibility, and other properties needed for compliance.
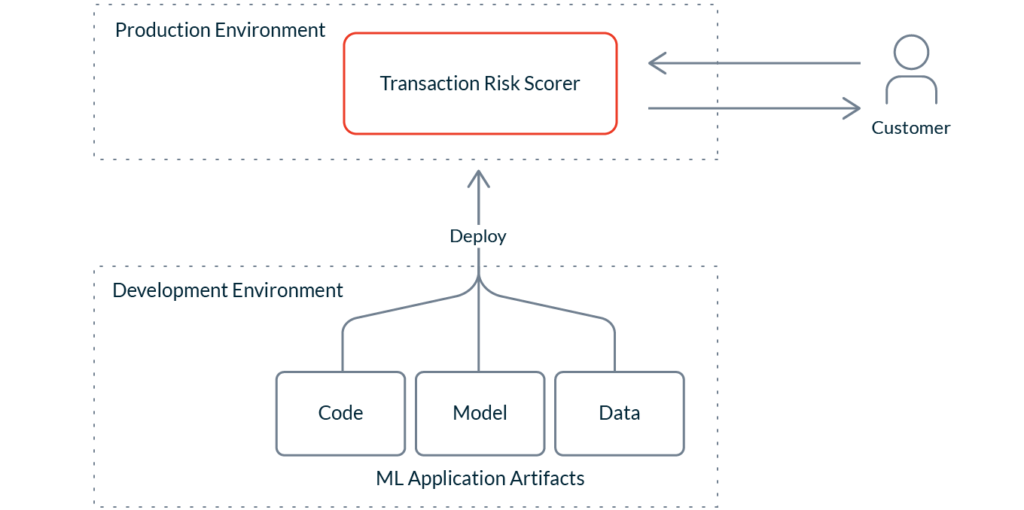
Getting the data pipelines right is messy and expensive. ML applications are data applications. Data dependencies are part of every ML system. My former team at Google observed that for ML, “data dependencies cost more than code dependencies”. Operational ML systems require hardened pipelines for continual — and often real-time — data ingestion, feature computation, and inference. Some pipelines need to precompute features, some extract them from event streams, and others compute and serve them live at prediction time. The wide variety of requirements on these pipelines can significantly complicate operational costs.
Monitoring and validation is not a solved problem. All of this complexity, the hidden gotchas and complex dependencies, make it very easy for operational ML systems to break and compromise the core purpose for which they were designed. It’s very easy for a data pipeline to break silently, and I’ve met more than a handful of teams who have had such issues go years before being discovered. Building ML applications that meet normal software standards requires significant investment in the tools needed to detect, debug, and mitigate issues as they arise.
Collaboration
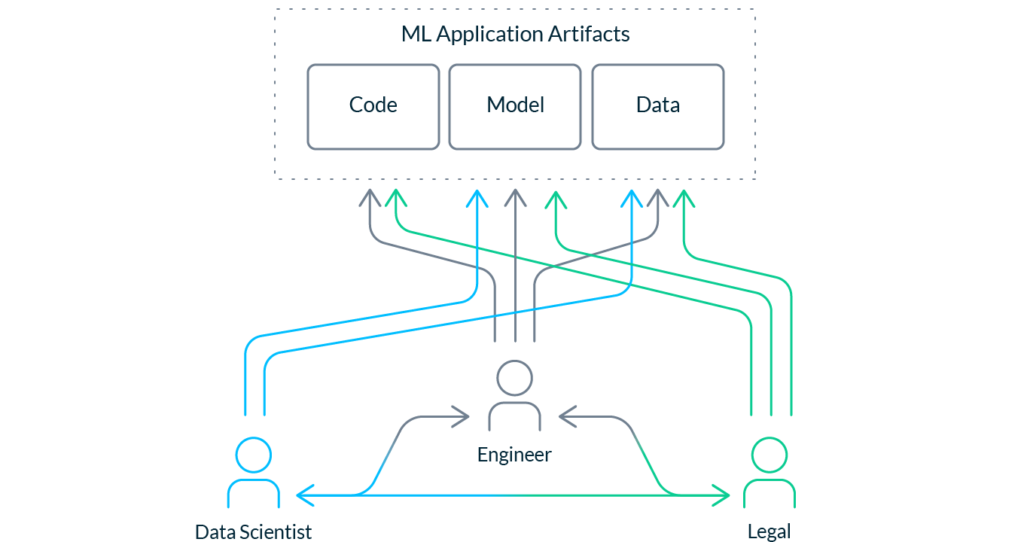
Data scientists and engineers are still learning how to collaborate. On most product engineering teams, the interface between different roles is well-established; e.g., a designer knows how to hand off designs to their engineering counterpart for implementation. Data scientists are new to the mix, and need best practices and tools to better collaborate with engineering. Data scientists typically lack the expertise and authority to touch production. Engineers typically lack the skills to develop the best models. No one can do it alone.
Building for scale is not solved — we’re stuck building snowflakes. Data scientists often develop in silos, leading to a proliferation of duplicate features, experiments, and models. Compare this to efforts at top tech companies, which rarely start from zero, because they’ve invested significant resources into making it easy to reuse features, insights, and techniques across projects. The high upfront cost and complexity of productionization makes standardization, discoverability, and reusability paramount for any organization trying to scale ML operationally.
Despite the obstacles, organizations are throwing resources at these problems because they are extremely valuable problems to solve. How much is the perfect personalized recommendation worth to an e-commerce website? How valuable is real-time underwriting to an insurance provider? What products can a team build if it can iterate on ML in production two thousand times per year rather than two? What is the next Google Personalized Search, Uber surge pricing, or Facebook Newsfeed?
Operational ML is only possible with the right tools
Overcoming these hurdles and achieving operational success with ML is only possible with the right tools. In this area, leading tech companies are years ahead of the pack with their internal frameworks and processes (some of which have been under development for more than a decade). The rest of the world doesn’t have the right tools or the resources to develop them. Leading Data Science Platforms provide increasingly good tooling to handle model management (training and deploying models). But there is still no solution for managing the backbone of any ML application: feature and label data.
An ML application is fundamentally just a data application. To make predictions, it relies on features: intelligent, live signals about a product’s customers, users, market, performance, etc. Feature data represents the business’ most curated data, the result of long and expensive processes of cleaning and massaging. This data is the key to success with operational ML; as Stanford professor Andrew Ng famously said, “applied machine learning is basically feature engineering.” But feature data is also very hard to get right.
At Uber, we observed, “Modelers spend most of their time selecting and transforming features at training time and then building the pipelines to deliver those features to production models. Broken data is the most common cause of problems in production ML systems.”
Tackling these problems was a core focus when developing Michelangelo. The most unique and valuable part of the platform was its built-in data management and orchestration system, the feature store. The feature store managed a shared catalog of vetted, production-ready feature pipelines, ready for any team to immediately import and deploy in their own solutions.
From model training to launch, the feature store changed how ML projects were developed at Uber. It introduced standardization, governance, and collaboration to previously disparate and opaque workflows. It unified the feature engineering process with the production serving of those features. The result was faster development, safer deployment, and an exponential increase in the number of ML projects running in production.
Tecton: A data platform for machine learning
As we’ve gotten to know countless ML product and infrastructure teams, we’ve found that data scientists and engineers everywhere are struggling with the same challenges. A system like Michelangelo’s feature store is conspicuously missing from the industry today.
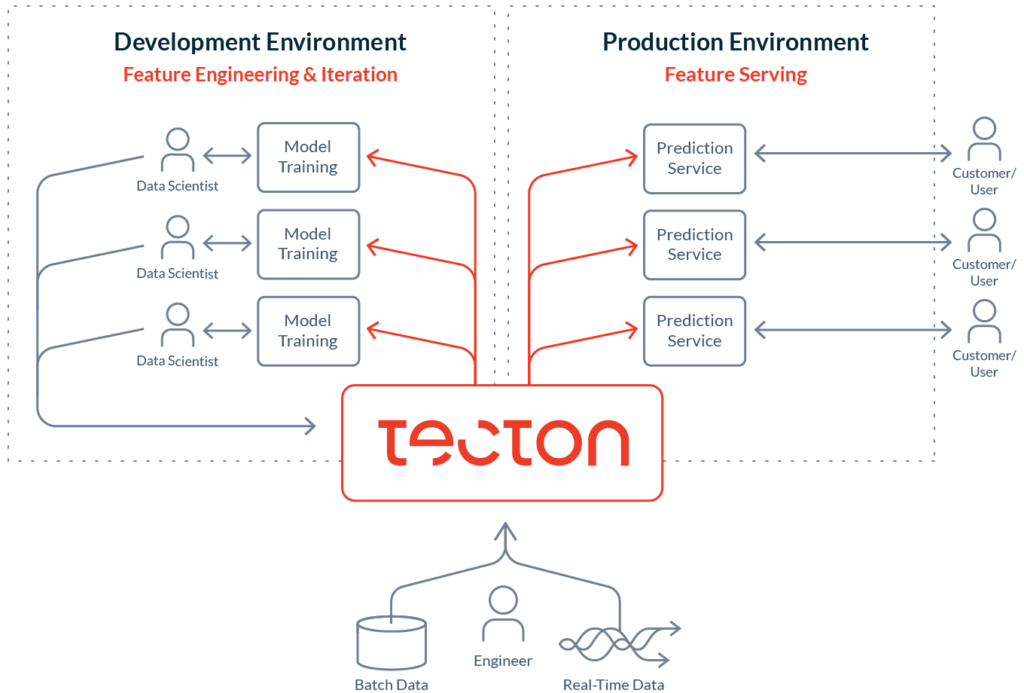
Tecton is a data platform for machine learning. It expands on the feature store architecture developed at Uber, and manages the end-to-end lifecycle of features for ML systems that run in production.
Tecton is designed to help ML teams:
- Develop standardized, high-quality features, labels, and data sets for ML from both batch and real-time data
- Deploy and serve feature data safely to models in production at scale
- Curate and govern an organization-wide repository of standardized, production-ready, and vetted features ready for sharing and reuse across projects
- Monitor feature data to ensure models continue to operate correctly over time
…and accomplish the above with the best practices, reproducibility, lineage, logging, and trust needed for any system on which business-critical functions are built.
The Tecton platform consists of:
- Feature Pipelines for transforming your raw data into features or labels
- A Feature Store for storing historical feature and label data
- A Feature Server for serving the latest feature values in production
- An SDK for retrieving training data and manipulating feature pipelines
- A Web UI for managing and tracking features, labels, and data sets
- A Monitoring Engine for detecting data quality or drift issues and alerting
We’re building Tecton to integrate with any ML stack and allow for smooth collaboration between data science and engineering. We think of it as the heart of the data flow in a machine learning application.
Where we are today and what’s next
I’m extremely proud of what we’ve accomplished at Tecton so far.
We’ve spent the last year building the platform and collaborating deeply with an amazing set of early partners. We’re helping them get their ML into production, safely and at scale. Last month, Atlassian pushed ML built with Tecton into production to power smart ranking and user interactions in Confluence.
We’ve also assembled a truly outstanding engineering team with deep data and ML experience from places like Uber, Google, Facebook, Twitter, Airbnb, Quora, etc. If you’re passionate about the abstractions behind data and ML workflows and are a practical problem solver, check out our jobs page. We’re hiring!
We’re also happy to announce that Tecton has raised $25MM of Seed and Series A funding, co-led by Andreessen Horowitz and Sequoia Capital. These resources will accelerate the development of our core technology and help us bring Tecton to market. Other investors include Fathom Capital, Liquid 2 Ventures, Lux, SV Angel, Florian Leibert, Qasar Younis, and Bucky Moore. We’re appreciative of all of their support so far.
We’re not releasing Tecton publicly just yet. We’re continuing to develop the platform and work with early partners. If your team is battling with putting ML in production and could benefit from a hands-on partnership, please get in touch! We want to work with highly aligned teams with whom we can deeply engage, consult directly, and iterate on feedback quickly.
Expect announcements about general availability later in the year.
This space is moving fast and there is so much we can do to make world-class ML available to every team. This is just the start for Tecton. Stay tuned, there’s a lot more to come!


