Enriching LLMs with Real-Time Context using Tecton



Large language models (LLMs) have revolutionized natural language AI, but they still face challenges when it comes to accessing up-to-date information and providing personalized responses. In Tecton 1.0, Tecton introduces innovative solutions to address these limitations by enriching LLM prompts with real-time context and giving the LLM scalable and robust data retrieval through feature pipelines. In this post, I’ll explore the use of two powerful techniques: enriched prompts and features as tools.
- Enriched prompts allow you to include up to date information related to the session context. Examples include relevant account or user activity information like insurance policy status & coverage or user information that is generally applicable for the LLM in responding to questions.
- Features as tools provide additional data retrieval capabilities to the LLM so that it can answer specific questions related to the session context. In insurance, for example, it might be coverage or claims processing data.
Tecton’s agent service is the interface that an LLM framework interacts with to retrieve enriched prompts and feature retrieval tools. It contains the list of prompts and tools that provide these capabilities to an attached LLM workflow.
Tecton Agent Service
Tecton is known for enabling production grade data pipelines through a declarative framework. This makes it easy to define ongoing streaming, batch and real-time transformation of raw data into rich features that describe the current state of any business entity. Tecton also provides agent services as part of the declarative framework to provide up-to-date context for LLMs. The agent service encapsulates the retrieval of context for generative AI application by building on-demand prompts enriched with feature data and also by delivering access to features as LLM tools. Agent services can be developed and tested from the comfort of a notebook and then deployed to the Tecton platform for low-latency and auto-scalable online serving.
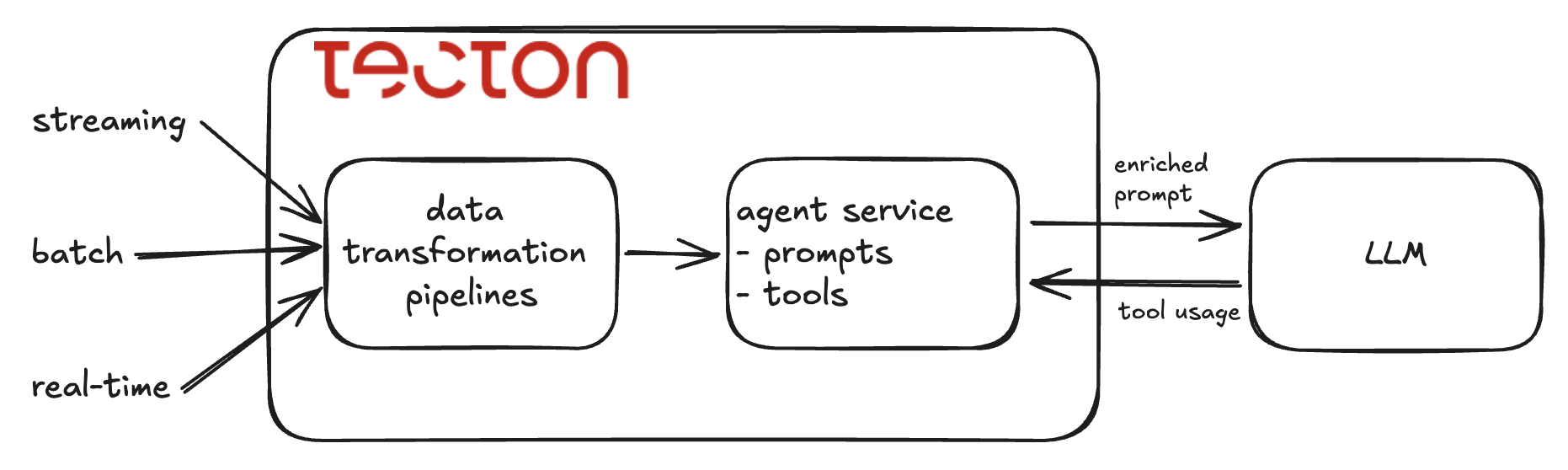
Now let’s dive into how you can use the agent service to build enriched prompts and features as tools.
Enriched Prompts
A prompt for an LLM acts as a guiding input that shapes the model’s output. It provides context, instructions, or examples that direct the AI to generate relevant responses. Effective prompts can control the focus, style, and role of the LLM’s output, serving as a crucial interface between the user’s intent and the model’s vast knowledge base.
Tecton’s enriched prompts allow you to inject data in real-time into your LLM’s system prompts, enabling personalized and timely responses. You provide the session context, such as a user_id and/or a location and the agent service retrieves the current value of features to build the system prompt. The declarative framework provides the @prompt decorator to define prompts and the AgentService to service it. Here’s an example of a restaurant recommendation prompt and its agent:
# create a request time input parameter to get current location
location_request = make_request_source(location=str)
@prompt(sources=[location_request, user_info])
def sys_prompt(location_request, user_info):
name = user_info["name"]
food_preference = user_info["food_preference"]
location = location_request["location"]
return f"""
You are a concierge service that recommends restaurants.
You are serving {name}. Address them by name.
Respond to the user query about dining.
When recommending a restaurant also suggested menu items.
Suggest restaurants that are in {location}.
Unless the user provides a cuisine, choose a {food_preference} restaurant.
"""
recommender_agent = AgentService(
name="restaurant_recommender",
prompts=[sys_prompt],
)
location_requestis an example of a request-time data source.- The
sys_promptfunction is decorated with@promptwhich specifies the data sources it needs to build the prompt. In this case it uses thelocation_requestand theuser_infofeature view. - The prompt template incorporates dynamic user data and location into the instructions it provides to the LLM. The user_info feature view is the source for the user’s “name” and their latest “food_peference”.
- An
recommender_agentdefines the agent service and what functions it will provide. In this case it only provides thesys_promptfunction as a prompt.
To test it, you can declare an agent client built from the agent service locally:
client = AgentClient.from_local(recommender_agent)To test the prompt, you can set the current context and invoke the prompt as follows:
with client.set_context({"user_id": "user3", "location": "Chicago"}):
response = client.invoke_prompt("sys_prompt")
print(response)Output:
You are a concierge service that recommends restaurants.
You are serving Jane. Address them by name.
Respond to the user query about dining.
When recommending a restaurant also suggested menu items.
Suggest restaurants that are in Chicago.
Unless the user provides a cuisine, choose a Chinese restaurant.Notice that the context contains the “user_id” which represents the session context in this scenario. With it, Tecton can retrieve features for the user that is currently using the application and therefore provide personalization.
Features as Tools: Empowering LLMs with Data Retrieval
Some context makes sense as part of a system prompt. More specifically, it’s context that is relevant to any interaction the user may have with the LLM. But there are also many cases of context that is only needed in order to respond to particular user questions. Consider the restaurant recommendation example again. If the user asks for a new restaurant recommendation, then the LLM will need a list of restaurants that the user has already dined at. But that list of restaurants is not needed if the user just asks for a Chinese or Italian restaurant near them; only their current location is needed for that. By empowering the LLM with a set of data retrieval tools, the LLM can use them only as needed. This helps simplify the prompt and can meaningfully increase the relevant context that the LLM has access to.
Here’s that agent service example with a simpler prompt and the addition of tools for the LLM:
@prompt(sources=[location_request])
def sys_prompt(location_request):
location = location_request["location"]
return f"""
Address the user by name.
You are a concierge service that recommends restaurants.
Respond to the user query about dining.
When recommending a restaurant also suggested menu items.
Suggest restaurants that are in {location}.
"""
recommender_agent = AgentService(
name="restaurant_recommender",
prompts=[sys_prompt],
tools=[user_info_fv, recent_visit_fv], # feature views as toolsThe prompt template above only incorporates the current location. The agent service now includes the prompt and a list of tools. The LLM will use the tools to retrieve the user’s name, their food preference and their recent restaurant visits but only when it needs that information to respond to the user’s request. Granted that it will always need to retrieve the user’s name from the user_info_fv given that we are asking it to “address the user by name”. So perhaps that one would still be better in the prompt.
One of the benefits of using Tecton for this purpose is that the metadata for the feature views is automatically used to provide descriptions of the tools to the LLM. In the case above, the feature views have the following descriptions:
- user_info_fv feature:
"User's basic information." - recent_visit_fv:
"User's recent restaurant visits."
So when the user asks for a “new restaurant”, the LLM will call the recent_visit_fv tool to exclude those restaurants and provide a good recommendation.
Integration with LangChain and LlamaIndex Frameworks
Tecton integrates seamlessly with LangChain and LlamaIndex. Here’s how to set each of them up. I’ve included the output :
LangChain integration
This example creates a LangChain agent using the Tecton client and demonstrates how to use it.
from langchain_openai import ChatOpenAI
langchain_llm = ChatOpenAI(model="gpt-4o-mini")
langchain_agent = client.make_agent(langchain_llm, system_prompt="sys_prompt")
# Example usage
with client.set_context({"user_id": "user1", "location": "Ballantyne, Charlotte, NC"}):
response = langchain_agent.invoke({"input": "Recommend a new place for tonight"})
print(response["output"])Output:
Hi Jim! I recommend trying **The Mint Restaurant** in Ballantyne tonight. It's a great spot for American cuisine, and you might enjoy their **filet mignon** or the **seafood risotto**. For a delightful appetizer, consider ordering the **fried calamari**. Enjoy your dinner!LlamaIndex integration
This example creates a LlamaIndex agent and shows how to use it with the Tecton client. The only difference comes from LangChain and LlamaIndex chat function signatures.
from llama_index.llms.openai import OpenAI
llamaindex_llm = OpenAI(model="gpt-4o-mini")
llamaindex_agent = client.make_agent(llamaindex_llm, system_prompt="sys_prompt")
# Example usage
with client.set_context({"user_id": "user2", "location": "Charlotte, NC"}):
response = llamaindex_agent.chat("Recommend a romantic place for tonight")
print(response)Output:
Since you've recently visited Mama Ricotta's, Villa Antonio, and Viva Chicken, I recommend trying **Fleming's Prime Steakhouse & Wine Bar** for a romantic dinner tonight.
The atmosphere is elegant and perfect for a special occasion. Here are some menu highlights:
- **Filet Mignon**: A tender and flavorful cut, cooked to perfection.
- **Lobster Tail**: A luxurious addition to your meal.
- **Chocolate Lava Cake**: A decadent dessert to share.
Make sure to check for availability and enjoy your romantic evening, John!
Conclusion
By leveraging Tecton’s feature pipeline integration with LLMs, you can create more personalized, relevant, and up-to-date AI interactions. Whether you’re building recommendation systems, customer support chatbots, or other AI applications, Tecton’s real-time context enrichment and data retrieval capabilities can significantly enhance your LLM’s performance.
To get started with Tecton and supercharge your LLM applications, visit explore.tecton.ai and explore our interactive demo and tutorials.