High-Scale Feature Serving at Low Cost With Caching





The proliferation of AI model-driven decisions over the past few years comes with a myriad of major production challenges, one of which is enriching AI models with context at high scale (i.e., low latency, high throughput) at a low cost.
For instance, this challenge is faced by modelers creating recommendation systems that personalize feeds and need features for millions of users and hundreds of thousands of products to make >10^5 predictions per second.
To tackle the challenge of high-scale feature serving at low cost, we’re excited to announce the Tecton Serving Cache, a server-side cache designed to drastically reduce infrastructure costs of feature serving for machine learning models at high scale. By simplifying feature caching through the Tecton Serving Cache, modelers get an effortless way to boost both performance and cost efficiency as their systems scale to deliver ever-larger impact.
In this post, we’ll discuss the different use cases for caching features, give an overview of how to use the Tecton Serving Cache, and share some benchmarking results that show up to 80% p50 latency reduction and up to 95% cost reduction compared to the baseline of a common AI feature retrieval pattern.
Tecton Serving Cache use cases
Common AI applications, such as recommendation systems, personalized search, customer targeting, and forecasting, would significantly benefit from caching. These high-scale applications are willing to trade slightly stale feature values from the cache for major reductions in latency and cost.
For example, in an ecommerce site’s product recommendation model, one of the features might be the average number of daily cart additions by customers for a given product over a week. This feature would be unlikely to change drastically over an hour, so it could be cached for an hour.
More generally, caching features would be beneficial in the following scenarios:
- High-traffic, low-cardinality key reads: Caching is ideal for use cases with high traffic (>1k QPS) where the same keys are repeatedly read. Repeat access of the same keys means a high cache hit rate, which reduces response times and the access cost for a request.
- Complex Feature Queries: Caching would be beneficial for features that are slow or expensive to compute, such as features with large aggregation intervals that require long computation times (>100ms).
Enabling the Tecton Serving Cache in two simple steps
To use the Tecton Serving Cache, simply add two pieces of configuration: one in the Feature View and one in the Feature Service that contains the cached Feature View. Modelers can configure the Tecton Serving Cache to retrieve pre-computed feature values from memory.
from tecton import CacheConfig, batch_feature_view, FeatureService
cache_config = CacheConfig(max_age_seconds=3600)
@batch_feature_view()
def my_cached_feature_view(cache_config=cache_config):
return
fs = FeatureService(
feature_views=[my_cached_feature_view, ...],
name="cached_feature_service",
online_serving_enabled=True,
enable_online_caching=True,
)- The
max_age_secondsparameter in theCacheConfigdetermines the maximum number of seconds a feature will be cached before it is expired. - The
enable_online_cachingparameter determines whether the Feature Service will attempt to retrieve a cached value from cached Feature Views. If a Feature View with cache options set is part of a Feature Service with caching disabled, then that Feature View will not retrieve cached values. - The
include_serving_status=truemetadata option in a request helps verify that a value is being retrieved from the cache. - The server response metadata will include a
statusfield that indicates whether the value was retrieved from the cache or not.
Benchmarks
To quantify the latency and cost reduction that the Tecton Serving Cache delivers, we ran a set of tests. In this benchmark, we queried sample feature services to measure the performance with different simulated cache hit rates, a measure of how frequently features can be found in cache memory rather than needing to access the online feature store. Several common AI applications, such as recommendation systems, typically have high queries per second (QPS) and high cache hit rates, therefore the benchmarks below are done with 10,000 QPS.
Latency Reduction
The table below lists the feature retrieval latencies (P50, P90, P95, P99) for 10,000 QPS for different cache hit rates.
| Total QPS | Cache Hit Rate | P50 FS Latency | P90 FS Latency | P95 FS Latency | P99 FS Latency |
|---|---|---|---|---|---|
| 10,000 | 0% | 7ms | 12ms | 16ms | 29ms |
| 10,000 | 50% | 5.5ms | 7.5ms | 9ms | 22ms |
| 10,000 | 95% | 1.5ms | 5.5ms | 6ms | 8ms |
DynamoDB Cost Reduction
This online store read cost is a major component of the total cost of running high-scale, real-time AI applications. The table below lists the monthly read costs of DynamoDB while using the Tecton Serving Cache at different cache hit rates for 10,000 queries per second.
| Total QPS | Cache Hit Rate | DynamoDB Read Cost/Month |
|---|---|---|
| 10,000 | 0% | $36700 |
| 10,000 | 50% | $18350 |
| 10,000 | 95% | $1835 |
The benchmark details are as follows:
- Feature Service contains 10 Aggregate Feature Views, each backed by a DynamoDB online store on us-west-1 with 3 Aggregate Features (sum, count, and mean), for a total of 30 aggregate features.
- Each aggregate feature has a time window of 30 days and a 1-day aggregation interval.
- Each Feature Service uses 3 entity keys.
- Seven of the feature views use 2 entity keys and 3 of the feature views use the other entity key.
- Each load test was run with 10 minutes of random traffic at a constant 10,000 QPS.
A glimpse into some optimizations
Our caching methodology employs Redis as a backend, utilizing Redis Hashmaps to significantly enhance efficiency and performance over traditional Redis keys.
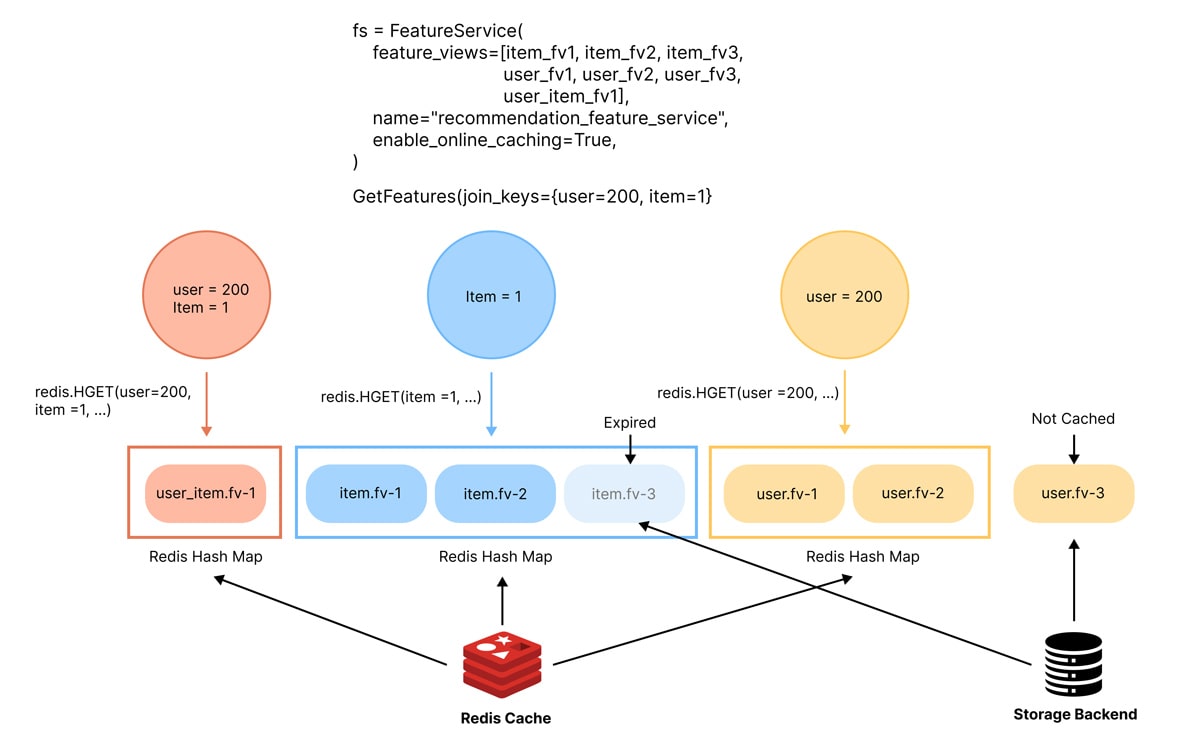
We use entity-level caching in the Tecton Serving Cache because both Feature View-level and Feature Service-level caching exhibit limitations. Feature View-level caching, which generates one key per feature view plus entity key combination, results in an excessive number of keys, consuming more storage and computing resources. In contrast, Feature Service-level caching, involving one key per Feature Service and entity key combination, is overly precise. This specificity can be a drawback, as many models share features, and any modification to a Feature Service might invalidate the entire cache, leading to performance issues.
Entity-level caching strikes a balance between these two approaches, aligning well with most caller patterns in AI applications. This method significantly reduces the number of keys requested from Redis, thus easing the load on the backend. Additionally, it uses less storage compared to Feature Service-level caching, making it a more efficient and resource-conscious option in various machine learning scenarios. The diagram below shows how a Feature Service with caching enabled containing Feature Views derived from Item and User entities would interact with entity-level caching.
What’s next
At Tecton, one of our highest priorities is to improve the performance and flexibility for production AI applications. In the coming months, we will add improvements to the Tecton Serving Cache along these dimensions:
- More flexibility
- Request-level cache directives to control caching behavior, including functionality to explicitly skip the cache for better debuggability.
- More options to control caching behavior.
- Better performance
- Further improvements to the latency of cache retrieval.
We can’t wait to see the Tecton Serving Cache power more production AI use cases—reach out to us to sign up the private preview!