How to Integrate With Tecton



Many of Tecton’s customers are mature or rapidly growing engineering organizations that have spent years building infrastructure and best practices to suit their needs. This often includes established code review workflows, custom data pipelines, deployment processes, or data scientist environments.
Therefore, the most common consideration when adopting Tecton is how seamlessly it will integrate with an organization’s existing infrastructure and processes.
Tecton’s product ethos has always been to offer simple solutions, complemented by flexible options for more complex requirements. In this post, I’ll walk through tradeoffs to consider when integrating with Tecton, beginning with:
- Configuring Tecton’s Declarative API
- Data ingestion patterns
- Managed and manual orchestration
Note: This post is focused on Tecton’s Spark-based solutions, but these patterns also apply to Tecton’s other data platform integrations, such as Snowflake.
Configuring Tecton’s Declarative API
Tecton is an end-to-end feature platform that uses a Python-based Declarative API to define and iterate on features. from creating feature pipelines to training data generation and real-time feature serving. Tecton repositories can be organized in isolated workspaces that allow users to iterate in parallel. It can also be integrated with CI/CD systems for more robust production deployments.
Repositories
Tecton’s CLI is used to create repositories based on the Declarative API, which can be registered with Tecton using tecton apply. Once repositories are registered, Tecton will orchestrate jobs and pipelines on your existing infrastructure.
It’s easy to get started interactively: install the Tecton CLI, log in, create a repository, and apply it to Tecton.
$ pip install "tecton[pyspark]"
$ tecton login
Tecton Cluster URL: https://acme.tecton.ai
$ tecton init
$ tecton applyThe CLI workflow is a great way to get started and iterate on feature definitions with Tecton. tecton apply syncs and pushes your changes to a Tecton workspace on demand. In practice, mature ML teams often have dozens of data scientists and engineers iterating in parallel, which requires a process to merge changes safely without affecting production environments.
Workspaces
Tecton workspaces provide isolation between users as well as environments (e.g., production and development). Users can create and iterate using “development” workspaces, which can eventually graduate to “live” workspaces, which enable production feature serving for real-time feature serving.
For example, at an e-commerce company, Alice on the fraud team and Betty on the recommendations team are developing use cases on Tecton. Both teams already have real-time use cases in production. Using workspaces, Alice and Betty can independently iterate in separate development workspaces before promoting their features to isolated live workspaces serving their team’s production data.

The next step is deploying changes to production. The simple option is interactively using tecton apply to push changes to the production environment.
CI/CD Integration
Many engineering teams have established processes for production changes. This means ensuring changes are well-tested, reviewed, auditable, and sequenced to prevent merge conflicts.
CI/CD integration with Tecton is the recommended strategy for safely pushing changes to production. CI/CD systems authenticated with a service account can safely merge and apply changes once they land in version control, which allows teams to manage Tecton using their engineering organization’s established code review and testing processes.

Tecton’s Declarative API also supports unit testing that can be run on-demand or as a pre-commit hook before pull requests are merged. Now, making changes to Tecton looks a lot like the common software engineering workflow: make some changes, write some unit tests, create a pull request, get it reviewed, merge it, and let your CI/CD system apply changes to Tecton.
In summary, there is a spectrum of options when configuring Tecton’s Declarative API:
- Simple option: Install Tecton CLI and apply changes to a live workspace.
- Flexible option: Use multiple live and development workspaces to isolate users and environments. Integrate with CI/CD to meet an organization’s code review, unit testing, and audit requirements.
Data ingestion patterns
At the heart of any real-time ML application is fresh, highly available feature data derived from one or more data sources. While the industry is converging on a set of batch (e.g., Snowflake, Databricks Delta Lake, BigQuery) and streaming (e.g., Kinesis, Kafka) options, there remains a long tail of storage and data pipeline patterns that need to be supported for a feature platform to be effective.
For ingesting data, Tecton supports two paradigms: pulling or pushing data.
Pushing data into Tecton
Pushing data into Tecton’s feature store eliminates many prerequisites for reading directly from data sources (e.g., IAM policies, cross-account permissions, etc.).
Tecton’s options for pushing data are Feature Tables and Ingest API. Feature Tables are effective for ingesting large volumes of infrequently updated batch data. Ingest API provides a low-latency, high-availability HTTP API for row-level data ingestion from stream processors or other clients.

With Tecton’s Ingest API, row-level data is pushed into Tecton using a simple HTTP request:
$ curl -X POST https://acme.tecton.ai/ingest\
-H "Authorization: Tecton-key $TECTON_API_KEY" -d\
'{
"workspace_name": "prod",
"push_source_name": "click_event_source",
"push_record_map": {
"user_id": "C1000262126",
"clicked": 1,
"timestamp": "2022-10-27T02:05:01Z"
},
}'With Feature Tables, DataFrames (Pandas or PySpark) can be pushed into Tecton in batches using the Python SDK:
import pandas
import tecton
from datetime import datetime
df = pandas.DataFrame(
[
{
"user_id": "user_1",
"timestamp": pandas.Timestamp(datetime.now()),
"user_login_count_7d": 15,
"user_login_count_30d": 35,
}
]
)
ws = tecton.get_workspace(“prod”)
ws.get_feature_table("user_login_counts").ingest(df)Pulling data into Tecton
To pull data directly into Tecton, several data source integrations are natively supported. Tecton can connect directly to batch sources (S3, Glue, Snowflake, Redshift), as well as stream sources (Kinesis, Kafka).

from tecton import HiveConfig, BatchSource
fraud_users_batch = BatchSource(
name="users_batch",
batch_config=HiveConfig(database="fraud", table="fraud_users")
)For power users on Spark, Data Source Functions provide complete flexibility when connecting to any Spark-compatible batch or streaming sources (e.g., Delta tables with live stream updates). In general, if data can be read into a Spark DataFrame, it can be read from Tecton.
from tecton import spark_batch_config, BatchSource
@spark_batch_config()
def csv_data_source_function(spark):
from pyspark.sql.functions import col
ts_column = "created_at"
df = spark.read.csv(csv_uri, header=True)
df = df.withColumn(ts_column, col(ts_column).cast("timestamp"))
return df
csv_batch_source = BatchSource(
name="csv_ds",
batch_config=csv_data_source_function
)
In summary, there is a range of options for ingesting data into Tecton.
- Pushing data is simple as it eliminates many data source integration prerequisites while providing flexibility for more complex integrations such as custom stream processors.
- Pulling data directly from stream and batch data sources offers high performance ingestion that supports a growing list of cloud-native data storage options.
Orchestration
Managed schedules
Tecton manages the schedule of materialization jobs that ingest and transform data into the feature store. Simple schedules such as hourly jobs or daily jobs at a specific time are easy to schedule when creating Feature Views.
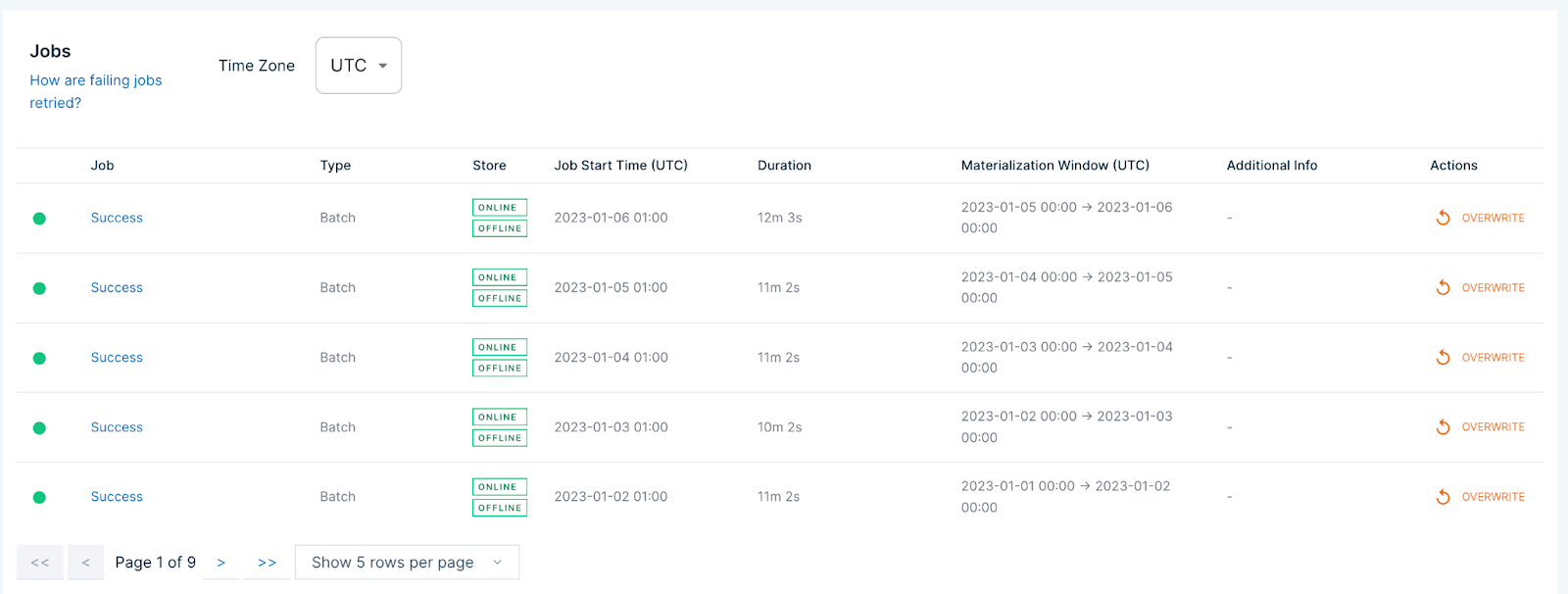
Job progress can be monitored in Tecton’s UI. In the event of upstream data source issues, individual jobs can be re-run to overwrite any invalid data time ranges.
Triggered materialization API
For additional flexibility, Tecton also supports a triggered materialization API that enables data teams to set their own materialization schedule or trigger jobs on demand as part of their own orchestration platform such as Airflow, Dagster, or Prefect. The API also supports re-running materialization jobs over previously materialized time windows.
import tecton
fv = tecton.get_workspace("prod").get_feature_view("user_fraud")
fv.trigger_materialization_job(
start_time=datetime.utcnow() - timedelta(hours=1),
end_time=datetime.utcnow(),
online=True,
offline=False,
)
In summary, there are two options for scheduling in Tecton:
- Simple approach: Managed schedules.
- Flexible approach: Schedule jobs manually using triggered materialization API.
Recap
This post covered a few of the options available when defining features using Tecton and ingesting your data into Tecton’s feature store. We recommend starting simple and incrementally integrating Tecton with your engineering team’s infrastructure and processes as you see fit.
The example below illustrates a simple Tecton integration with a user-managed feature repository that configures batch-only Feature Views orchestrated with managed schedules. Each component (feature repository, data ingestion patterns, orchestration) can be customized to fit the engineering team’s needs.

This is the first in a series of posts covering integration options when integrating with Tecton. In future posts, I’ll cover topics ranging from training data generation to online stores and access controls.
Questions or comments? Join us in our community Slack channel. Or if you’re interested in trying out Tecton for yourself, sign up for a free trial.


