Transfer Learning: Lessons from Predictive ML for Agentic AI


What 10 Years of ML Infrastructure Teaches Us About the Next Generation of AI
Ten years ago, shipping Predictive ML felt like making a rocket out of duct tape and good intentions. The models were promising. The impact was clear. But the infrastructure was brittle and chaotic.
Since then, we built abstractions like feature stores, model registries, data science workbenches, and ML observability tools to productionize ML. Now we’re entering the era of agentic systems. LangChain calls them Ambient Agents, Confluent expects a world of event-driven agents, and Salesforce expects Agentforce to power the “digital labor revolution”. Their form factor has shifted, but their data infrastructure needs look remarkably similar.
Below, I’ll briefly revisit the challenges of predictive ML, map them to agentic systems, and then show how they converge on the Context Store: an evolution of the Feature Store that serves data to agents via MCP.
Data Infrastructure Requirements for Predictive ML
The challenges of scaling predictive ML in production were mostly about data and deployment. I helped build Uber’s ML Platform in 2016. Since then, at Tecton, we have worked with hundreds of teams across companies like Coinbase, Block, Atlassian and Signifyd to put predictive ML applications into production.
The basic architecture of a real-time ML application typically looks like this today:
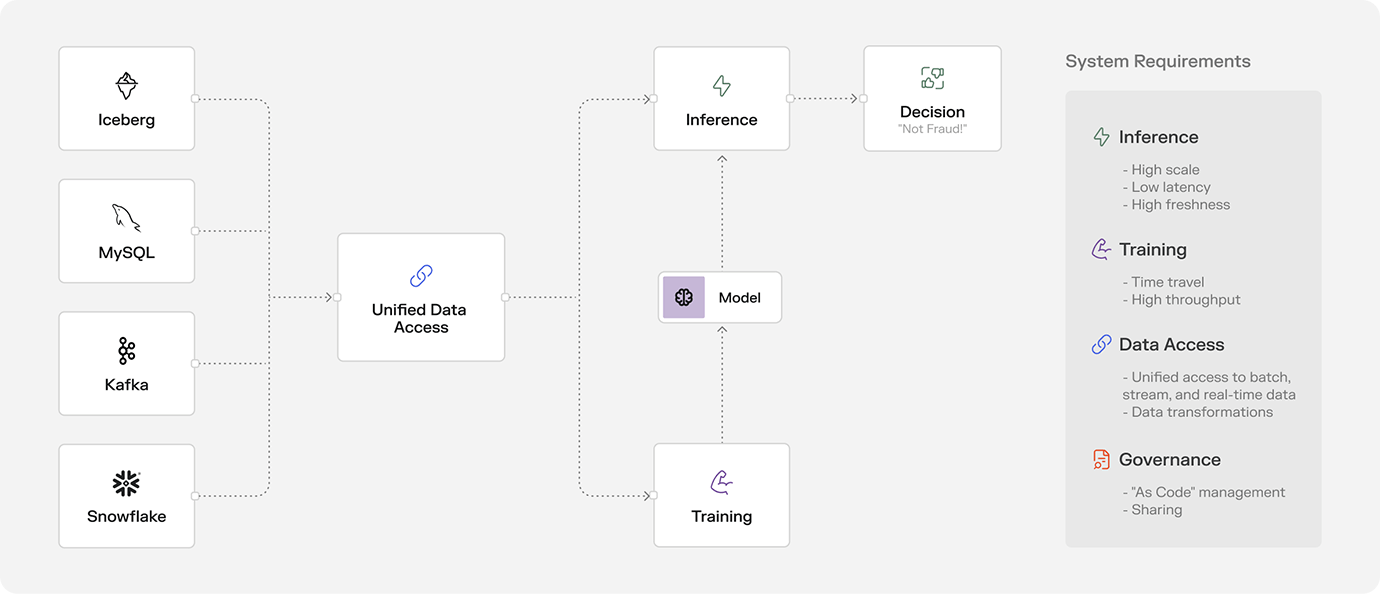
And here’s what these systems nearly always need:
| Requirement | Why It Matters |
|---|---|
| Unified data access | To make a prediction, a model needs access to data – also known as “features”. ML models rely on features that need to be computed from a mix of data sources across streaming events, batch tables, 3rd party APIs etc. Once computed, those features need to be served via a unified and reliable access layer. |
| Low-latency serving | Predictive models have to respond in milliseconds, but most upstream data sources can’t respond quickly enough. Models cannot wait for minutes until a SQL query that calculates a credit card user’s lifetime transaction count has been calculated. As a result, features from “slow sources” (e.g., warehouses) are eagerly precomputed, while features from from streaming sources (e.g., kafka) are computed in near real time. Finally, the features are then served from a KV store that’s optimized for low latency. |
| High freshness | A fraud detection model can’t rely only on yesterday’s behavior. It needs to know what is happening right now. Therefore, ML models need a way to react immediately to new events on a Kafka stream or read data at prediction-time from a real-time API. |
| Time travel | Training a model requires having an accurate representation of the past. For every labeled event, you need to recreate the exact state of the world at decision time to avoid the dreaded online/offline skew. And you need to do it quickly – because nobody likes starting at a slow or potentially OOMing Spark job when they’re trying to quickly iterate on a new idea. |
| Sharing | Different models often need the same inputs. Without shared infrastructure, teams often ended up duplicating work and paying for redundant compute & storage. |
| Governance | Enterprises need to know where each feature comes from, who built it, and when it changed. The best way to accomplish this is with a centralized system that enables compliance, auditability, and debugging. |
| DevOps compatibility | As models entered production, the surrounding pipelines needed GitOps: define all pipelines as code, and use CI/CD to automatically test, roll-out and rollback any changes. |
These common requirements led to the rise of the feature store: a centralized system for managing ML data pipelines, for precomputing feature values when necessary, and for serving features for model inference and training. Whether built in-house or bought, whether named feature store or “anonymous web of custom pipelines and storage systems”, feature stores became the backbone of reliable, scalable ML.
Data Infrastructure Requirements for Agents
Agentic systems are a new class of AI-powered apps. They can reason, take action, and interact with the world. You can get to a working prototype remarkably quickly. However, similar to ML, when thinking about production, the story gets more complicated. Here’s what the early production systems I’ve seen in the wild tend to look like:
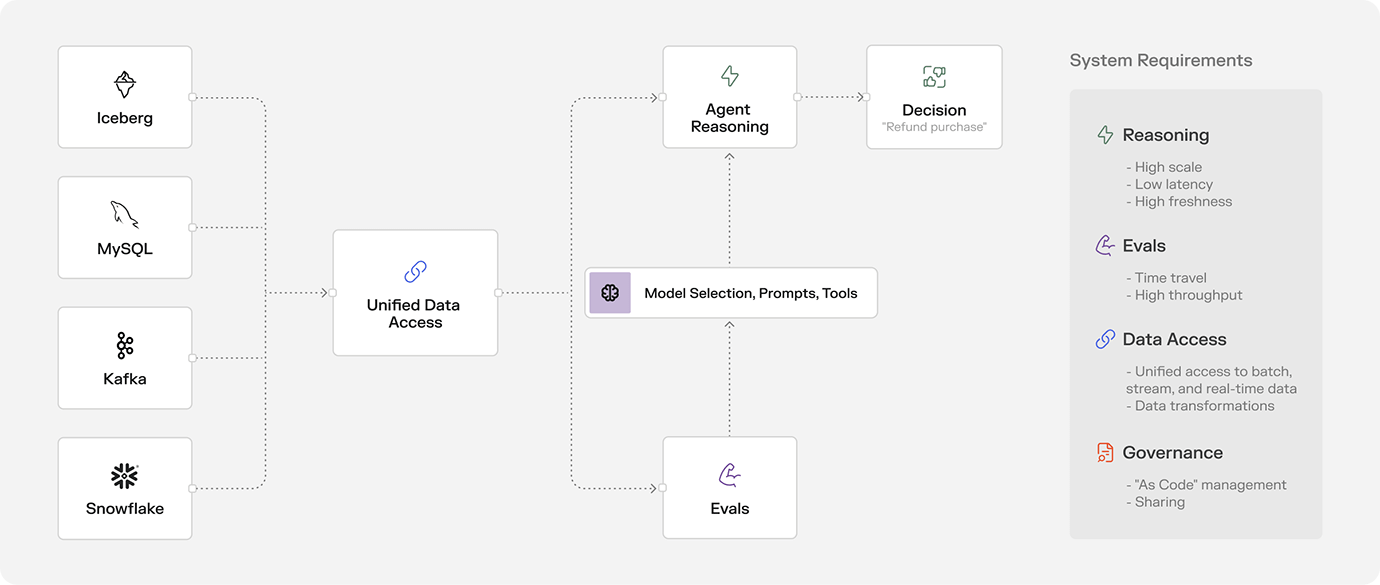
Let’s start with the biggest difference to predictive ML systems: you don’t need to train a domain-specific model for every use case and custom data set anymore. You only need to choose an off-the-shelf model that best meets your cost/latency/reasoning-quality needs and you’re off to the races. It’s a massive force multiplier that lowers the barrier to adopt these systems.
Outside of that, the data needs are similar to Predictive ML:
| Requirement | Why It Matters |
|---|---|
| Unified data access | To make a good decision, an agent needs access to data that goes beyond a hard-coded system prompt (commonly referred to as context). It’s information about customers, merchants, transactions, products, the weather – you name it. It comes from the familiar messy multiverse of Kafka topics, Snowflake tables, operational databases, APIs, and more. In contrast to ML, agents need static and dynamic access to context:
|
| Low-latency serving | Agents may not need ML’s 10ms response times today, but they can’t wait 10 seconds either. Real-time serving of context will be essential for interactivity and a delightful user experience. Whenever the upstream data source is unable to meet those latency requirements, the transformation needs to be precomputed and served from a store that’s built for reliable and low-latency serving. |
| High freshness | Agents will make better decisions with fresher data. For example, a customer service agent needs to know right now which food delivery is late – not which one was late yesterday. The agent needs a way to react immediately to new events on a Kafka stream or read data at decision time from a real-time API. |
| Time travel | While you don’t need to train an LLM, you will need to run model evaluations when you experiment with a different model provider (switch from OpenAI to Gemini?), a different system prompt, or a different set of tools. To make this successful, you will need to simulate agent behavior (decisioning and tool calls) on historical context before rolling out the changes. Similarly, when you want to fine-tune LLMs for your domain-specific use cases, you will need historical data. |
| Sharing | Multiple agents across departments will rely on overlapping context. Without shared pipelines and governance, duplication and drift will spiral. |
| Governance | Agents are non-deterministic. That means strict guardrails, audit logs, and change management will be even more critical. |
| DevOps compatibility | Agents are software, too. They need source control, automated testing, CI/CD, and observability, just like microservices and ML pipelines. |
Context Stores and MCP will power Agents and ML alike
Agentic systems and predictive ML both rely on structured, fresh, low-latency data to drive decisions. The key difference is how that context is consumed: ML models consume features. Agents consume context through prompts or call tools via protocols like MCP. But the hard problems of ingesting messy upstream data, transforming it consistently, keeping it fresh, and governing access remain unchanged.
That’s why the same architectural foundation applies: Enterprises that industrialized real-time ML solved these challenges with feature stores. To support agentic systems, that foundation needs to be extended. By exposing data via MCP, a feature store evolves into what could be called a context store: a unified system for defining, computing, storing, sharing, and serving context. This decouples agents from the underlying data infrastructure and enables them to operate on fresh, reliable context in real time and at scale:
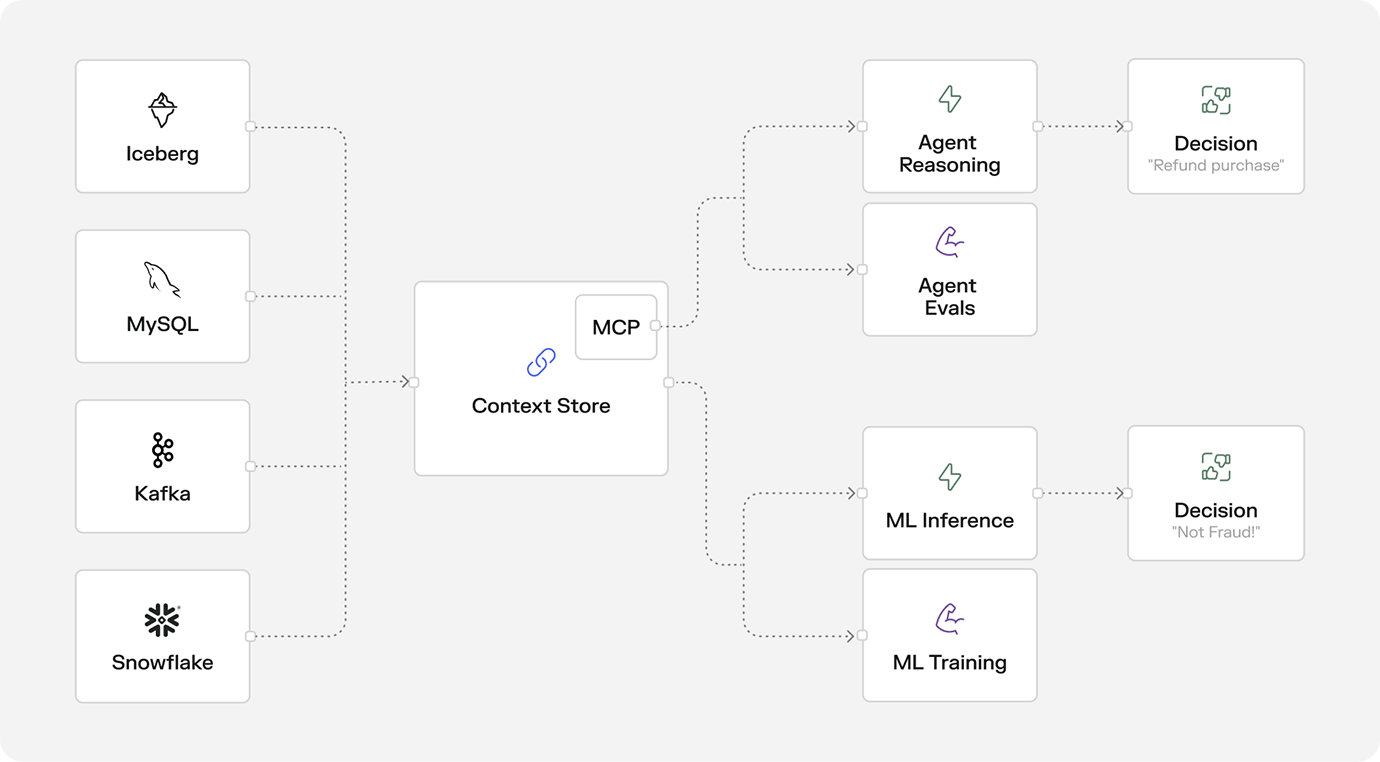
At Tecton, we’re very actively helping our customers evolve their data infrastructure to support agentic systems. If you’re building agents that leverage streaming or real-time data, please get in touch, I would love to chat.


