Why RAG Isn’t Enough Without the Full Data Context



Oh no! Your flight is delayed! You’re going to miss your connection and you need to change flights ASAP. Ever the savvy traveler, you start chatting with the new AI-powered customer support chatbot in the airline’s app. But does the chatbot know enough about you and your situation to help with your next move?
Generative AI has high potential for valuable use cases. But are you using LLMs for customer-facing applications in production, or are you still stuck in the experimental phase? If your models aren’t useful enough for primetime, it’s probably because they don’t have the full context to provide a relevant response. LLMs are smart on general knowledge, but not on your business and what’s happening in real time.
Take air travel. Customers make real-time decisions, which means the window of opportunity for revenue and retention is real-time. When a flight is delayed, can the airline react quickly enough to take action? Or will the customer get frustrated and book with a different carrier? And if an app hallucinates a response and steers the customer wrong, will the airline foot the bill?
It depends on whether the airline’s app can deliver relevant, real-time support. Which means the context the LLM receives needs to be relevant, accurate, and real-time. Context is the information a model uses to understand a situation and make decisions. Context can take various forms, including features, embeddings (numerical encodings of data), engineered prompts, and more.
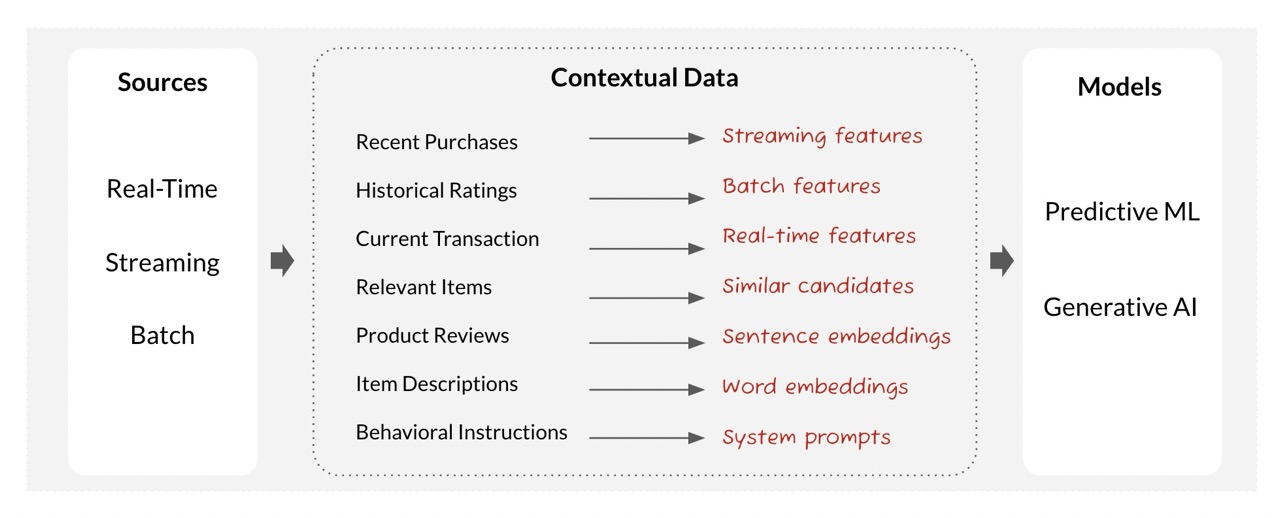
So how do developers building production AI apps give LLMs the context they need? The common approach is to start with RAG – but you shouldn’t stop there.
Traditional RAG is an incomplete solution for production use cases
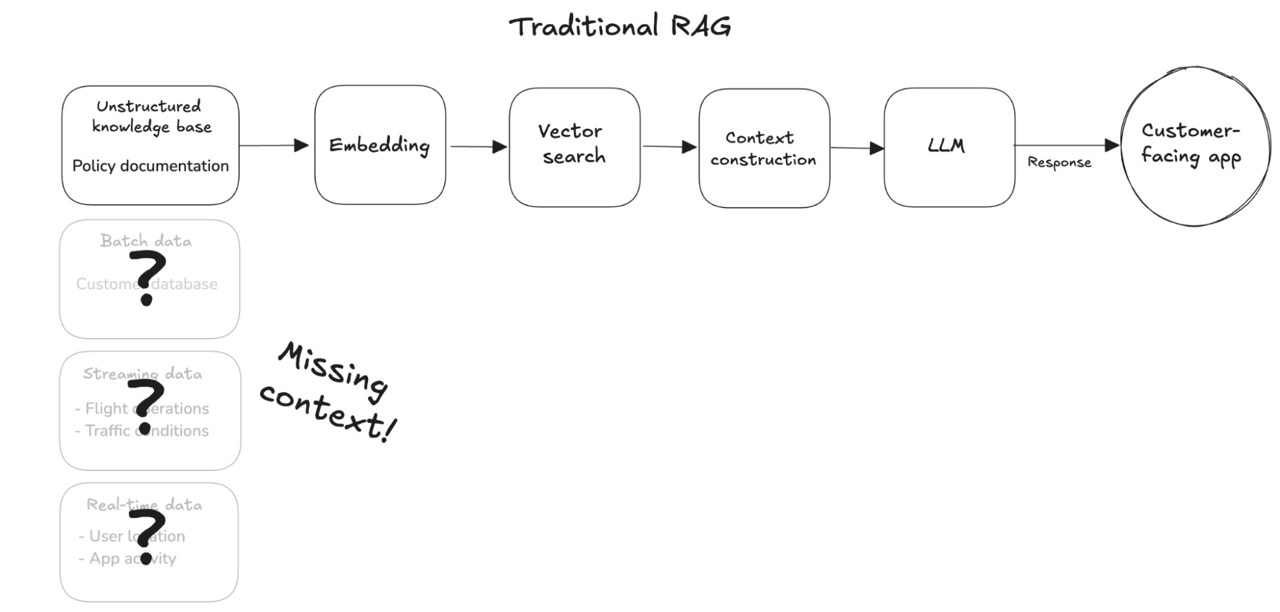
RAG (retrieval-augmented generation) has emerged as the standard for improving an LLM’s contextual knowledge. Traditional RAG systems do a vector search, retrieving information from a vector database to supply relevant knowledge to the model.
Most vector searches are implemented as similarity searches. Existing documents or chunks of text are converted into embeddings and stored in a vector database. When a user query comes in – like an airline customer asking a chatbot how to change flights – the query embedding is compared to the stored document embeddings. The most similar text chunks are retrieved and ranked based on their similarity scores, and the selected text augments the LLM’s generated response.
But a similarity search falls woefully short in situations where there is rich structured knowledge available and evolving rapidly. Because a vector database is a single store of unstructured data, it doesn’t capture relationships between the many different data points in a business. It’s also limited to existing indexed content, so it doesn’t have timely information about the user or the situation, such as recent purchases and live location.
In other words, it’s missing the full range of enterprise data.
To productionize AI faster, developers building AI applications need a way to turn all enterprise data sources – including streaming and real-time data – into production-grade context.
Why production-grade context matters: Customer support example
How does context make the difference between lost revenue, and a lifetime customer? Let’s see what it looks like when an airline implements an LLM-powered customer support app using a RAG approach, with different levels of context.
Level 0: Traditional RAG with vector search
Let’s say the airline uses a traditional RAG to retrieve policies and procedures documentation from a vector database. Existing documentation has been converted into embeddings, and stored in a vector database.
When a customer asks about rebooking, the RAG system performs a similarity search to retrieve the closest matches to rebooking information and rank the best candidates. It might see “rebook” in the user query, match it with “Rebooking Policies” in the existing documentation, select it as the best candidate, feed that to the LLM, and generate a response based solely on the generic, static rebooking documentation.
No other knowledge – like flight operations and traffic – is taken into consideration.
THE RESULTING CHAT:
Customer: My flight is delayed and I’m going to miss my connection. Can you help me rebook?
App: I apologize for the inconvenience. We will attempt to rebook you on the next available flight to your final destination, subject to seat availability. For specific rebooking options, you will need to speak with a customer service representative at the airport. They can access your booking details and provide you with available alternatives. Is there anything else I can help you with?
You’ve probably already had it with this airline! Even though a vector search helps supply relevant knowledge, the model is still missing lots of important context.
Level 1: Vector search + batch features
We can fill in some of that context with batch features to make our response more helpful, such as customer user data (flight booking details, preferences, loyalty status). We want to tell the model more about the user; perhaps we’ve computed features like duration_of_membership.
Here is what the chat might look like now:
Customer: My flight is delayed and I’m going to miss my connection. Can you help me rebook?
App: I’m sorry to hear about the delay. I see you’re traveling from LGA to NRT with a connection in SFO. As a Gold status member for over 12 years, you have priority rebooking. You can click here to reach our VIP customer service hotline.
More helpful, for sure. But it’s still not very actionable – we want to make it frictionless for a customer to book. Let’s tap into more missing context.
Level 2: Vector search + batch + streaming features
Our hypothetical airline has streaming features like flight operations (delays and cancellations) and traffic conditions, which can help the model surface alternative flights with up-to-date information about today’s flight availability and travel time.
Customer: My flight is delayed and I’m going to miss my connection. Can you help me rebook?
App: I apologize for this situation. I see your flight LGA-SFO (1234) is delayed by 2 hours due to air traffic control issues, causing you to miss your connection to NRT. As a Gold status member for over 12 years, you have priority rebooking.
I’ve identified some alternatives, including options from nearby airports:
- Option from LGA: I can rebook you on a later connection. Flight 3579 departs at 10:55 PM, arriving in SFO at 1:20 AM. There’s an aisle seat available in Economy Plus.
- Alternative from JFK: There’s a direct flight to SFO (6584) from JFK Airport departing at 7:50 PM. JFK is about 10 miles from LGA, and travel time is approximately 25 minutes given current traffic conditions.
Now we’re getting somewhere. But there’s still one more thing we can add to help our customer get to their flight: Real-time context.
Level 3: Vector search + batch + streaming + real-time context
Real-time context like dynamic user signals (such as location coordinates) can complete the full picture for the LLM. In this case, we can give the model the context that the customer is currently in a different terminal from the one the new flight is in.
Customer: My flight is delayed and I’m going to miss my connection. Can you help me rebook?
App: I apologize for this situation. I see your flight LGA-SFO (1234) is delayed by 2 hours due to air traffic control issues, causing you to miss your connection to NRT. As a Gold status member for over 12 years, you have priority rebooking.
I’ve identified some alternatives, including options from nearby airports:
- Option from LGA: I can rebook you on a later connection. Flight 3579 departs at 10:55 PM, arriving in SFO at 1:20 AM. There’s an aisle seat available in Economy Plus.
- Alternative from JFK: There’s a direct flight to SFO (6584) from JFK Airport departing at 7:50 PM. JFK is about 10 miles from LGA, and travel time is approximately 25 minutes given current traffic conditions.
Customer: (Clicks on LGA flight option)
App: Great! You’re all set. I see you’re currently in Terminal A. The new flight is in Terminal B, so look for the signs near Gate 32 pointing to the Skylink tram that will take you to your new assigned gate.
The combination of batch, streaming, and real-time features gives the model the context it needs to not only help the traveler find a better flight option, but also have a positive experience that makes them a more valuable lifetime customer.
This goes for any production GenAI use case. For instance:
- If you’re building a product recommendation engine for an e-commerce platform, real-time context could be the difference between a binge watch on your platform or a binge watch on the competitor’s.
- If you’re a financial services company sending personalized offer emails to customers, context could be the difference between an upsell and junk mail.
A production-grade app needs production-grade context. Otherwise, you have a missed connection between your app and your user!
Build AI apps with production-grade context using Tecton
A system that provides production-grade context is more valuable than basic RAG, but way harder to build. It can be a herculean undertaking to activate all of your enterprise data.
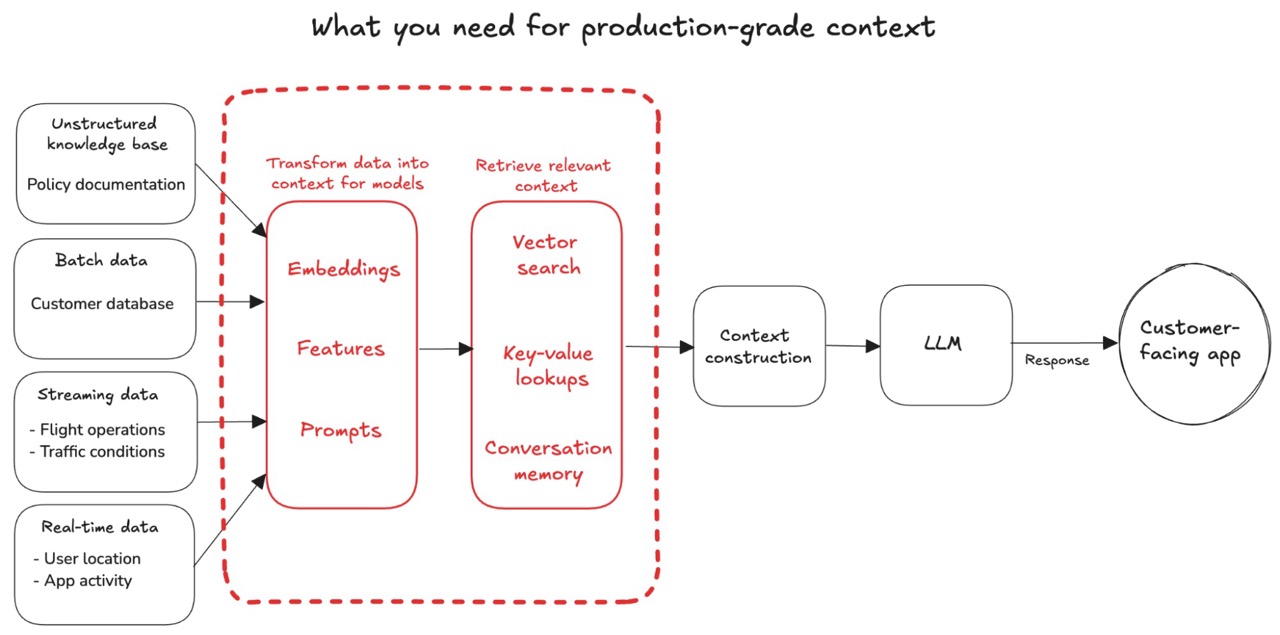
You need to be able to construct the relevant context from disparate sources, each with different engineering needs. You have to build and maintain the pipelines to get data into usable shape for an LLM, perhaps building thousands of embeddings and features. Not to mention orchestrating, evaluating, and monitoring all of the above. On top of that, you need to ensure data freshness, be able to retrieve context at low latency, backfill data, and more.
Does it sound too hard to pull off? That’s what Tecton is for.
Tecton unifies this process for all of your enterprise data, abstracting away the engineering needed to compute, manage, and retrieve context for AI. With Tecton, you can incorporate multiple data sources and approaches in one common framework to give your LLM the complete picture:
- Simplify the entire lifecycle of context production, retrieval, and governance via a single declarative framework, universal for all data sources
- Extract signals from batch, streaming, and real-time data
- Create, centralize, and serve features, including aggregations
- Efficiently generate embeddings for unstructured data
- Brings DevOps best practices to LLM prompts with dynamic prompt engineering
Only 5% of companies report using generative AI in regular production. Production-grade context can be the difference between being part of the 5%, and the 95% still stuck in the prototype phase.
Interested in getting your LLM-powered apps into production? Chat with a Tecton expert to learn more.