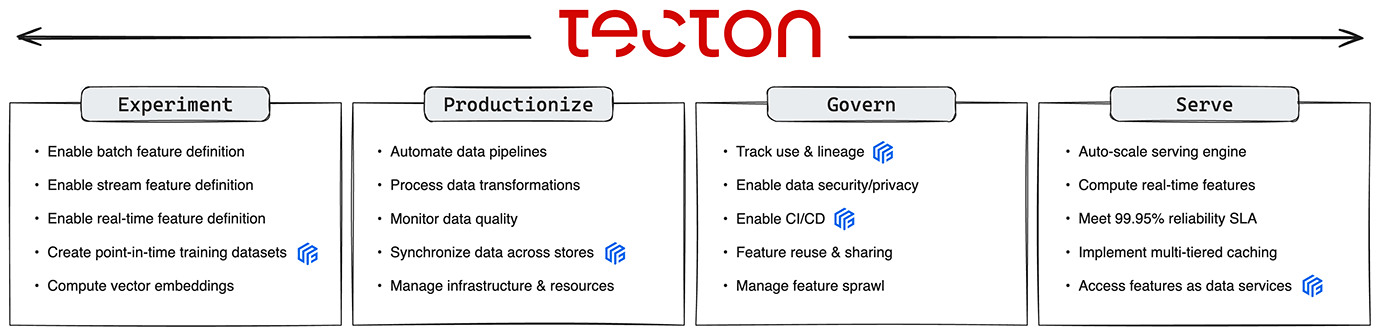
Tecton and Feast both centralize how features are stored, managed, and served for ML models. But only Tecton removes the complex engineering across the entire feature workflow from experimentation, productionization, governance, and serving.
Learn more in this technical talk
When to Choose Tecton or Feast
Feature stores are essential when productionizing AI, serving as the backbone for managing, storing, and serving features for model training and deployment. Yet, productionizing AI requires more than just managing features—it involves significant data engineering work to turn raw data into features and serve them quickly and accurately for training and inference.
While Feast provides the basics of storing and serving features, teams are still responsible for transforming raw data into features, creating and maintaining data pipelines, pipeline observability, and integrating data from batch, streaming, and real-time sources. Additionally, Feast limits projects to a single offline source (e.g. Amazon Redshift, Google BigQuery) and one online store per project. For example, it’s not possible to have one feature in Feast retrieving data from Redshift and another feature pulling from Snowflake, and then combine them in a single feature service.
On the other hand, Tecton is a fully managed feature platform that extends far beyond the functionality of a feature store. Designed for enterprise-scale AI deployment, Tecton automates the data processing of raw data into engineered features and serving them at any production SLA, abstracting away all of the data engineering complexity. By orchestrating the entire data journey from raw data ingestion to serving engineered features to models, Tecton helps ML teams rapidly define, productionize, manage, and serve features for any ML application with consistency and reliability.
Feature Development
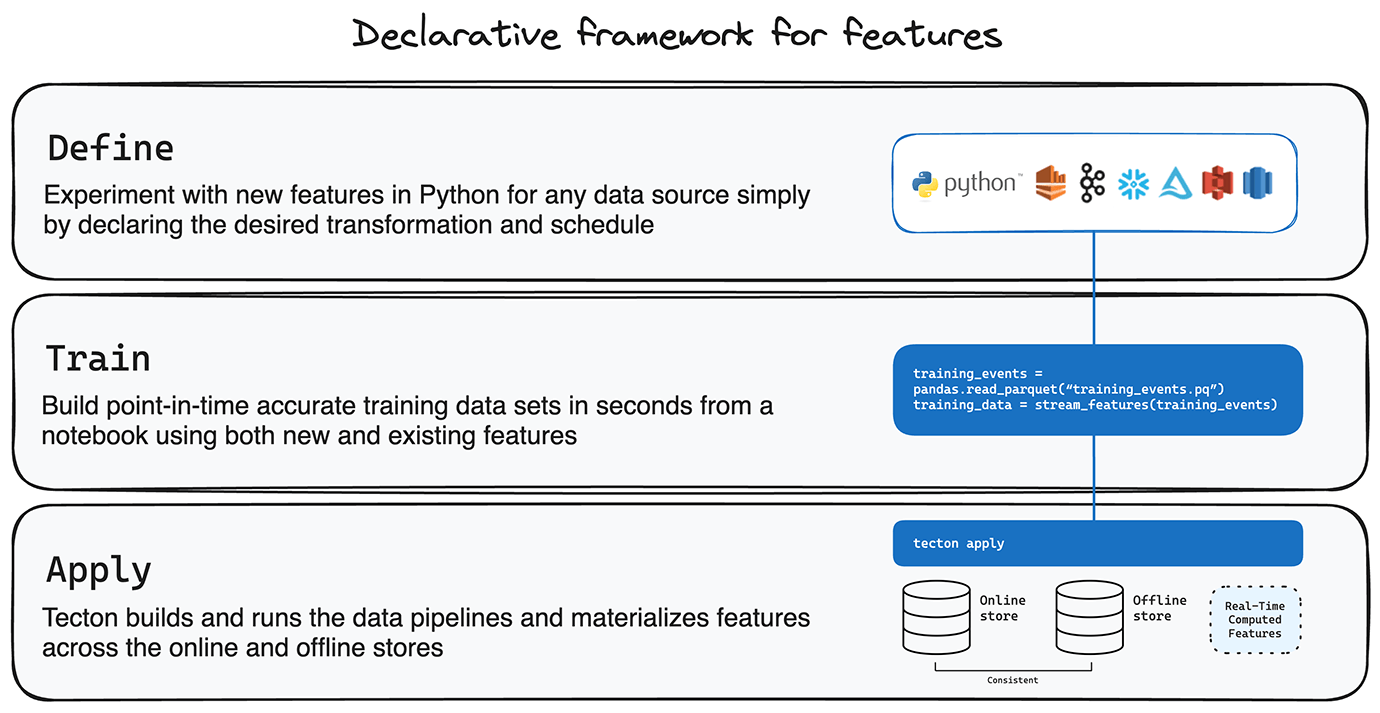
With Tecton’s Python-based declarative framework, data scientists and ML engineers can rapidly define and experiment with new features from any data source (batch, streaming, real-time) in a notebook environment and materialize features in a single command. They simply have to specify the desired end state of a feature, rather than detailing all the procedural steps in various data processing systems to achieve it. This is done in a concise, readable way using Python code.
Feast requires users to define how data transformations should occur manually. Users write detailed code to specify each operation in the external data processing workflow. This involves explicitly scripting how data is extracted, transformed, and loaded into the feature store using Python code and Feast APIs. The necessity for in-depth coding means that ML engineers or data scientists must meticulously craft the entire logic and sequence of transformations, which can be both time-consuming and prone to errors.
Feature Productionization
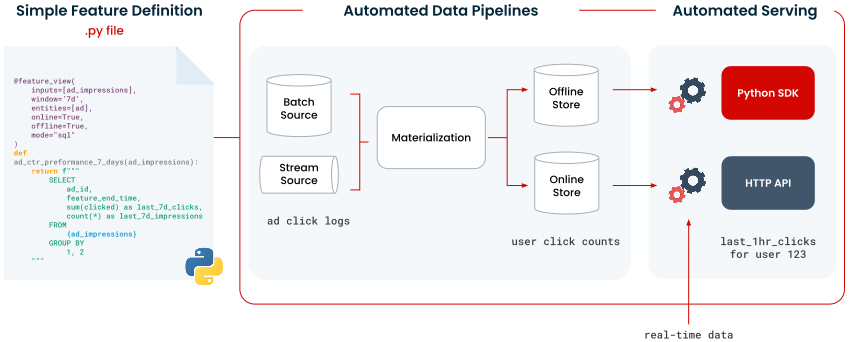
Once features are defined, Tecton automatically generates and manages the data pipelines needed for processing data to meet the specified end state of each feature. This includes scheduling, managing dependencies, handling errors, and ensuring data consistency across online and offline stores. For batch pipelines, backfill and incremental pipelines are automatically scheduled, provisioned, and monitored. For streaming pipelines, consuming transformations are provisioned and configured for auto-scaling, and automated tracking and alerting systems are put in place. Event time pipelines for on-demand features are integrated into the serving system.
Feast does not build the data pipelines for data transformations, backfilling, or forward-filling. Instead, users need to perform transformations before ingesting the data into Feast via external systems. It also does not automate the creation, management, or orchestration of data pipelines. Therefore, ML engineers must manually set up and maintain the pipelines needed to process data before it enters Feast, typically using additional tools or platforms.
Serving Performance
Tecton has a powerful, unified serving system that not only orchestrates but also provides the underlying data infrastructure required to retrieve pre-computed features, compute real-time features, and serve the final feature vector—ensuring data consistency across training and inference environments. It provides end-to-end reliability with a 99.95% availability SLA.
Feast provides an API for accessing stored features but lacks a comprehensive feature serving system like Tecton’s, which supports advanced operations such as real-time transformations and performance-optimized serving. Consequently, teams using Feast must embed real-time feature transformation logic directly within their applications, involving hardcoded data queries and transformations. This complicates updates, as any changes to feature logic necessitate significant involvement from software engineers, potentially leading to rigid and error-prone implementations. Moreover, while Feast does offer a Python-based feature server, it falls short in efficiency, especially in high-performance environments needed for production.
Total Cost of Ownership
Tecton significantly reduces the Total Cost of Ownership (TCO) for AI operations by automating data pipeline orchestration, provisioning optimized compute resources, and managing data flow efficiently. This automation reduces computational demands and virtually eliminates the manual labor typically required to maintain the data pipelines needed for features, thus cutting operational and labor costs. This approach enhances the scalability and efficiency of AI deployments, offering substantial infrastructure cost savings over traditional ETL tools or custom-built feature platforms.
Feast, in comparison, requires hands-on setup and management of data pipelines. It does not inherently provide optimizations such as automated data flow management or compute resource allocation, placing the onus on the user to manage these aspects effectively. Consequently, while Feast offers flexibility and control, it may also result in higher operational expenses and labor costs due to the extensive manual setup and maintenance required.
Infrastructure Operations
Tecton simplifies the management of compute resources needed for AI operations across streaming, batch, and real-time data with its unified computing engine, Rift. By integrating these functionalities into a single, fully managed system, Tecton eliminates the need for multiple specialized technologies like Apache Spark for batch processing and Apache Flink for streaming. This reduces complexity and cuts down on the overhead associated with maintaining diverse computing technologies.
In contrast, teams using Feast have to maintain expertise in several distinct computing technologies and manage their integration across different data types. This leads to increased infrastructure complexity and higher costs, as teams must ensure operational consistency across systems that are inherently designed for different tasks.
Security and Control
Tecton offers enterprise-readiness features that include sophisticated audit logging and robust security measures like SOC 2 compliance and access controls, right out of the box. These capabilities ensure that your organization can manage and protect data effectively, facilitating safe and scalable AI/ML deployments.
Access control is critical for:
Security: Ensuring that sensitive data is only accessible to authorized users.
Compliance: Meeting legal and regulatory requirements that protect data from unauthorized access.
Data integrity: Preventing unauthorized modifications that could lead to data corruption or loss.
Feast does not implement its own system for managing who can access or modify data and features within the feature store.
Summary
Tecton is a comprehensive feature platform that surpasses basic feature stores like Feast by automating data transformations and streamlining the entire AI data lifecycle, from initial data ingestion and transformation to feature serving and management. Unlike Feast, which requires significant manual effort in data infrastructure setup and orchestration, Tecton automates data pipelines for transformations across various data sources (batch, streaming, real-time) and also provides a unified system for both managing and serving features effectively. This enables several key business outcomes:
Significantly faster time to market, evidenced by an 80-90% reduction in development time compared to homegrown systems.
Lower production costs by freeing up 50% of resources typically needed to maintain a homegrown system.
Exceptional reliability, with Tecton having managed over 2.5 trillion predictions last year for mission-critical applications.
Experience Tecton’s feature platform first-hand by signing up for our interactive demo, where you can explore Tecton’s web UI and use the Tecton SDK to build features, train models, and make predictions.
A feature store is a centralized repository designed to store, manage, and serve features (data attributes) for machine learning models. While it supports the consistency of features across training and production environments, enhancing model accuracy and efficiency, it does not handle the transformation of raw data into features.
A feature platform facilitates the entire data journey from raw data ingestion and transformation to serving engineered features to models, helping teams rapidly define, productionize, and manage features across various data environments with consistency and reliability.
Feature stores simplify the AI development process by providing a systematic way to manage data attributes (features) across different machine learning models. This centralization improves data quality, reduces duplication of effort, and supports robust model performance by maintaining consistency between training and production environments.
No. Feast is not the unmanaged version of Tecton. Tecton is NOT built on Feast. Tecton and Feast have independent roots, were started by different companies, and were built on different architectures. Feast is an open-source feature store, and Tecton is a managed feature platform.
Yes, Tecton is designed to be highly compatible with existing data ecosystems. It supports integration with various data sources and ML tools, providing flexible and robust interfaces for data ingestion, feature computation, and serving. This makes it easy to adopt and integrate within your current technology stack without disrupting existing processes.
Tecton’s customer base includes Fortune 500 companies and digital native organizations like Coinbase, Plaid, and HelloFresh that often deal with complex data environments and require a reliable, secure, and scalable feature platform that can support high-volume, high-velocity data workloads. Read more about our customers here.
Tecton is Preferred By Leading Companies
Book a Demo
Contact Sales
Interested in trying Tecton? Leave us your information below and we’ll be in touch.
Unfortunately, Tecton does not currently support these clouds. We’ll make sure to let you know when this changes!
However, we are currently looking to interview members of the machine learning community to learn more about current trends.
If you’d like to participate, please book a 30-min slot with us here and we’ll send you a $50 amazon gift card in appreciation for your time after the interview.
Interested in trying Tecton? Leave us your information below and we’ll be in touch.
Unfortunately, Tecton does not currently support these clouds. We’ll make sure to let you know when this changes!
However, we are currently looking to interview members of the machine learning community to learn more about current trends.
If you’d like to participate, please book a 30-min slot with us here and we’ll send you a $50 amazon gift card in appreciation for your time after the interview.