
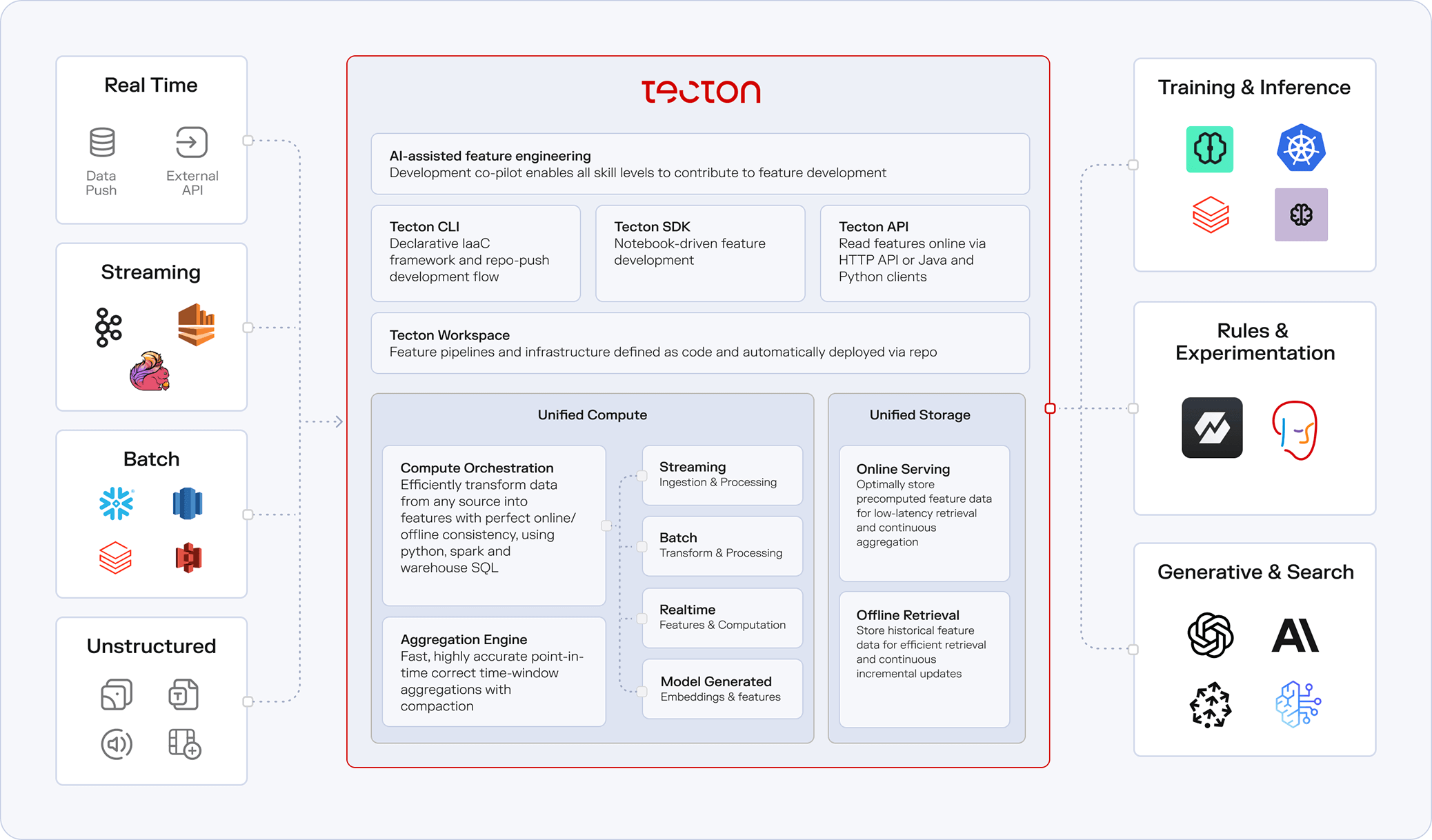

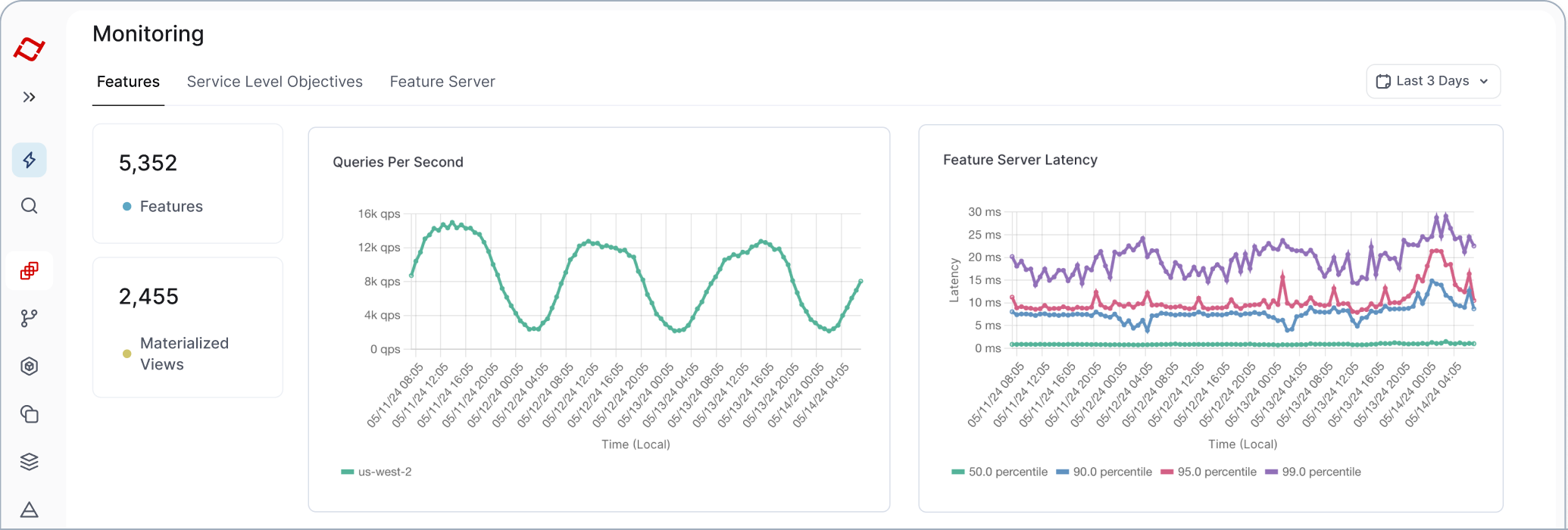
“What shines about Tecton is the feature engineering experience—that developer workflow. From the very beginning, when you’re onboarding a new data source and building a feature on Tecton, you’re working with production data, and that makes it really easy to rapidly iterate.”
Coinbase
Joseph McAllisterSenior Engineer, ML Platform at Coinbase
“When we first started building our own feature workflows, it took months—often three months—to get a feature from prototype into production. These days, with Tecton, it’s quite viable to build a feature within one day. Tecton has been a game changer for both workflow and efficiency."
Atlassian
Joshua HansonPrincipal Engineer at Atlassian
“In just a week or two of work (instead of months of plumbing), we had real-time features feeding our search-ranking models, letting us A/B-test session-level personalization immediately."
HomeToGo
Stephan ClausDirector Data, Machine Learning & Platforms at HomeToGo 
“Whether we actually need to access the latest, most up-to-date feature in real time at inference time, or just access the point-in-time correct historical values when generating data sets, there’s just one single definition. … It then allows me as the data scientist to spend more time on feature and model development and worry less about backfilling and avoiding data leakage."
GetYourGuide
Mihail DouhaniarisSenior Data Scientist at GetYourGuide 
“Prior to Tecton, our features were generated independently with individual Spark pipelines. They were not built for sharing, they were often not cataloged, and we lacked the ability to serve features for real-time inference.”
HelloFresh
Benjamin BertincourtSenior Manager ML Engineering at HelloFresh 
“Tecton makes machine learning and data science teams essentially self-sufficient.”
Block
Niccolò RonchettiStaff Machine Learning Engineer at Block 
“With Tecton as part of our stack, we’re really focused on understanding trends, disrupting fraud rings and delivering near-instant decisions—without having to build and maintain our own feature-freshness infrastructure.”
Signifyd
Nathan AckermanSVP of Engineering at Signifyd
“For credit specifically, we leveraged a roughly 50% increase in approval rate while decreasing losses by about 5%. Fraud transaction monitoring was even more extreme—4× the chance of blocking a fraud transaction while blocking 20% fewer legitimate ones."
Tide
Hendrik BrackmannVP Data at Tide 
