Powering Millions of Real-Time Rankings with Production AI





At GetYourGuide, we make over 30 million ranking predictions daily, shaping the journeys of millions of customers. Each prediction plays a crucial role in presenting the most relevant and personalized results for search queries in the blink of an eye – we deliver these rankings in under 80 milliseconds. This ranking system is an important part of discovery throughout GetYourGuide’s search features, influencing everything from the home page to specific destination pages, and it’s a critical driver of business impact.
Creating a machine learning system that meets such demands and maintains performance is no small feat. We faced several challenges while building our search ranking system:
- Diverse Feature Types: Our ranking algorithm utilizes features, ranging from activity-level information such as historical performance and activity content to user interactions like activity views and bookings, to personalize each search ranking to best match a visitor’s unique interests. These features combine multiple data warehouse tables and kafka events, and they are not always easy to compute on the fly.
- Running Realtime Feature Pipelines: Historically, we used only batch-computed features served at inference time. However, over time, we realized that features generated in real-time in response to visitors exploring our activity selection were extremely valuable. Implementing and maintaining such features can be challenging as they require complex data streaming infrastructure, robust feature engineering, and tight performance monitoring.
- Cost-Efficient Serving: Our traffic patterns are significantly seasonal, which requires adaptable and scalable infrastructure to remain cost-efficient.
- A/B Testing: We constantly test new ideas, which means comparing new features to the old and gaining clear insights into what works and what doesn’t.
- Drift Detection: Data changes, behaviors shift, and our model must adapt to maintain high performance. Spotting and adjusting for these changes is a daily challenge and key to our ML operations.
We adopted Tecton as our feature platform and Arize for model observability to tackle these challenges. They fit nicely with our existing tech and help us create new features for user personalization while also giving us a clearer view of how our models perform in production and whether any changes in features or model behavior need addressing.
In this post, we’ll take you behind the scenes of creating a mission-critical feature for personalizing rankings. We’ll leverage the power of Tecton and Arize to seamlessly integrate it into production, monitor the model performance, and quickly alert you to model issues and address them whenever they arise.
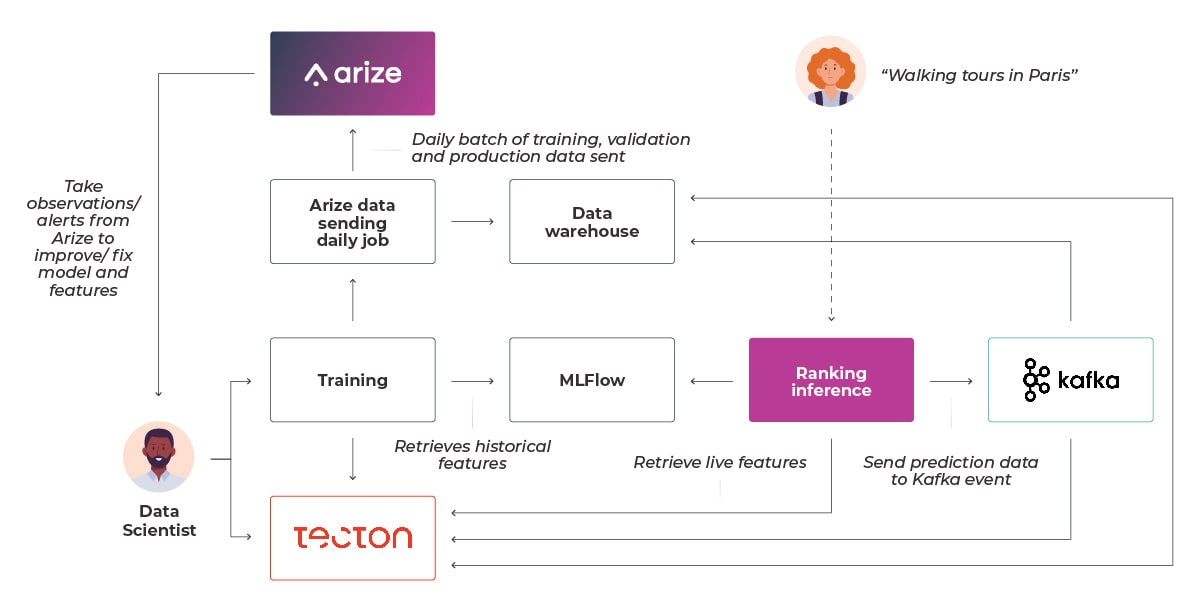
Feature Engineering
We start our modeling by exploring our diverse, real-time data sources – Kafka streams capturing everything from user impressions and clicks to actual bookings. This rich activity data allows us to paint a comprehensive picture of user engagement, informing our offline analytics and the features powering our production ML models for personalizing each user journey in our platform.
Using our in-house events catalog tool, data scientists can quickly identify promising events and examine their historical records within our data warehouse. After an event has been identified, data scientists use Tecton to develop ML features by setting up the data source and defining feature views.
A recent example of our feature engineering approach is the “discounted ranking impressions” feature we created for our activity ranking system. This feature maintains an up-to-date count of each visitor’s impressions for specific GetYourGuide activities while also factoring in the position of the activity on the page where the impression occurred. We opted for a relatively short 7-day lookback window as user behavior changes rapidly. We used a Stream Feature View to aggregate the Kafka stream of activity impressions in real-time on a visitor level and the activity positions on the search result page. Subsequently, we used Tecton’s On Demand Feature View to process this stream further to extract the final position-discounted impression count for each visitor-activity pair.
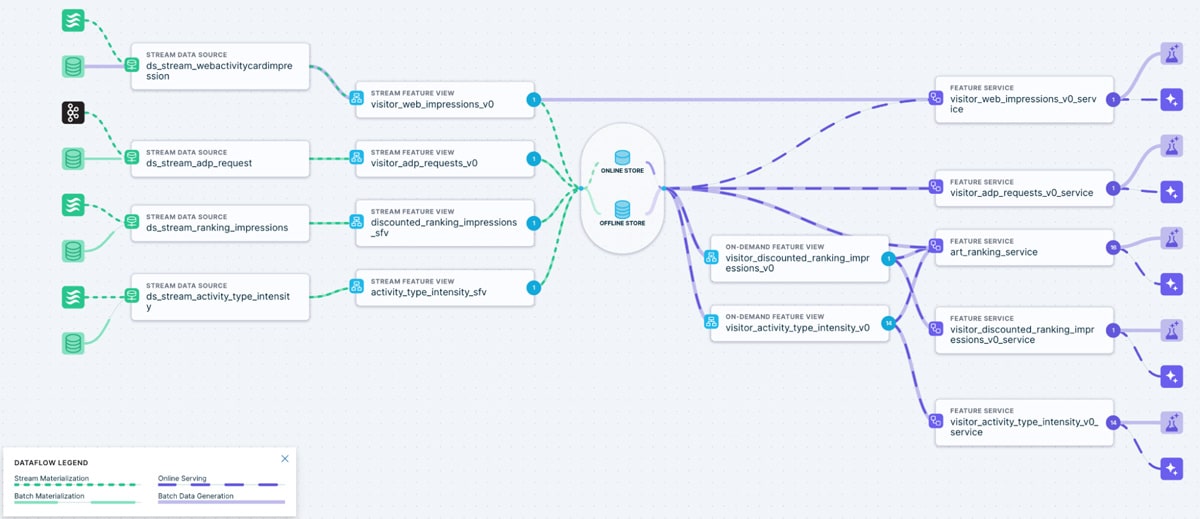
When working on feature engineering tasks with Tecton, we typically employ an iterative approach in which we apply an entity-level filter during the initial stages of the feature’s development. This ensures that only a small subset of entities are materialized, so that any potential feature rematerializations during development will have minimal impact on cost and Kafka cluster stability. Before a full-scale materialization, we validate the feature and perform a final check by testing it against live events from our Kafka streams using Tecton’s built-in .validate() and .run_stream() functionalities. This allows us to identify any occasional discrepancies in event structures that could later surface in the fully materialized feature, such as schema differences across platforms like iOS and Android. After the final checks, we remove the entity filter used during development and deploy the feature to production. Tecton automatically performs the full materialization and takes care of all necessary backfills.
Training
Our search ranking model pipeline leverages Airflow to orchestrate dataset generation, automate model training, and deploy a fresh model daily. This ensures that our production models capture the latest user interaction trends and are always up-to-date with ever-evolving user preferences.
The training dataset consists of historical ranking event logs and subsequent user interactions on the ranked activities, such as page views and bookings. This data is then joined with the features in Tecton’s offline store, including our newly created discounted ranking impressions feature, which the model utilizes during training to determine optimal rankings. Tecton’s offline store enables us to easily fetch the point-in-time accurate feature values for each unique entity at the exact time of the historical ranking event. This capability is extremely valuable as it simplifies feature experimentation by eliminating the hassle of backfilling and the risk of data leakage.
After successfully producing a production-ready model, we commit it to MLFlow, our model repository. During this step, we also send our training and production data to Arize for observability purposes, where two datasets are dispatched:
- Counterfactual Dataset: A dataset with predictions from the newly trained model, providing insights into its potential performance.
- Production Data: A batch of the previous day’s production data serves as a benchmark for the new model’s performance.
Below, we’ll cover in more detail how we use Arize to monitor model performance and the quality of feature data, ensuring our users consistently receive relevant recommendations.
Serving
Packaged as a Docker image with FastAPI, the trained model is deployed with both control and treatment models retrieved from MLFlow for A/B testing. Once deployed on our Kubernetes cluster, services can seamlessly invoke the correct model variant as needed.
Every ranking inference request uses the visitor ID to retrieve Tecton’s up-to-date features. In the case of our new feature, this would be the list of position-discounted impressions for each activity ID, updated every time a visitor produces more impressions as they browse through GetYourGuide’s activity selection. Using Redis as the online store, we achieve p99 latencies of just under 7ms per request; this low latency lets us adhere to our service’s tight SLOs. We track the feature freshness and latency using Tecton’s specialized feature monitoring dashboards to ensure that we constantly receive fresh data for each call. Further, by leveraging Feature Server autoscaling, we cut down roughly 50% of the costs (compared to over-provisioning) while handling spiky and seasonal traffic patterns effortlessly.

At serving time, our ranking service produces a Kafka event on a dedicated topic so that we can later ingest realized predictions to Arize and monitor feature and model accuracy drift. This data is ingested from the Kafka stream and stored as a table in Databricks.
Observability
After deploying our model and making online predictions, we still need to ensure it functions well in production. Our ranking model has 51 features describing a wide range of activity and user properties, split between many different types and ranges of values. To ensure that our model behaves as expected, we need to monitor the input features during training and inference, as when problems arise, they can often be traced back to the data itself. To help us keep an eye on this, we use Arize to create data quality and drift monitors for our features so that we can promptly get alerted on Slack in case there are any significant deviations in data quality or distributions. In particular, the feature drift monitors are very valuable as feature drift can be very common in the real world, and it’s easy to remain undetected while our model is in production. Arize can measure the feature drift using a reference dataset, which we have set as the last two weeks of production data in a moving window manner. Drift monitors then compare model feature distribution over time using metrics such as PSI, KL Divergence, and more.
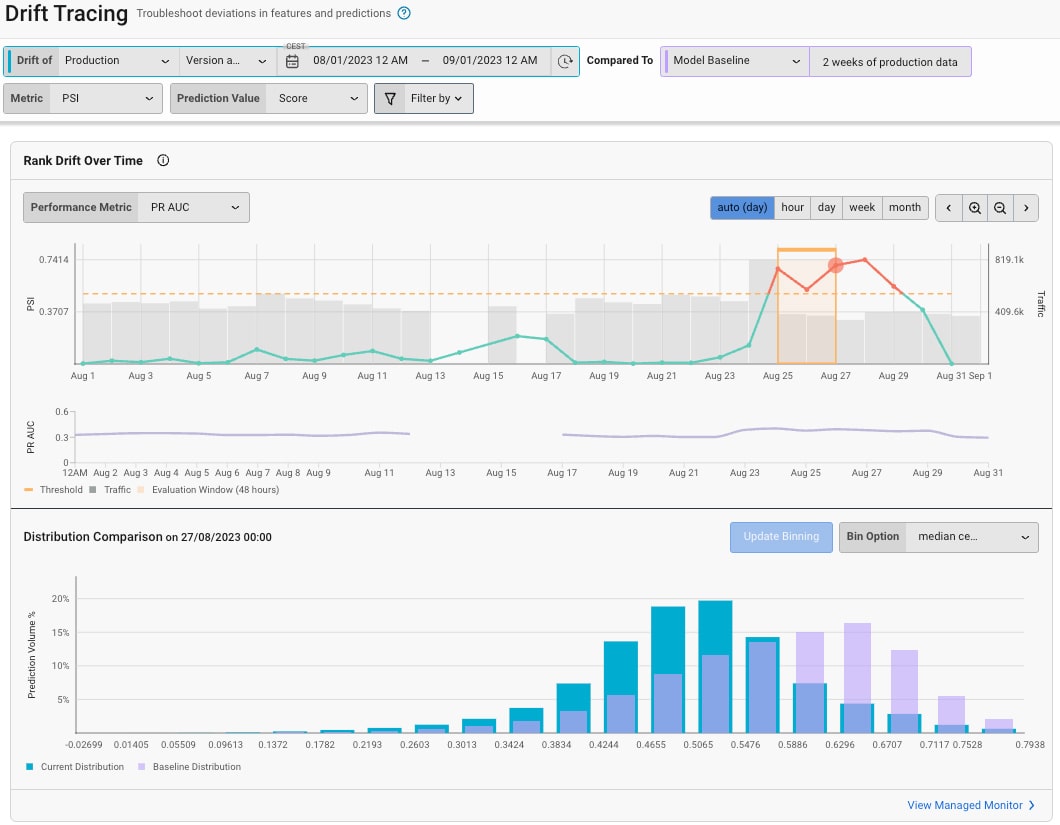
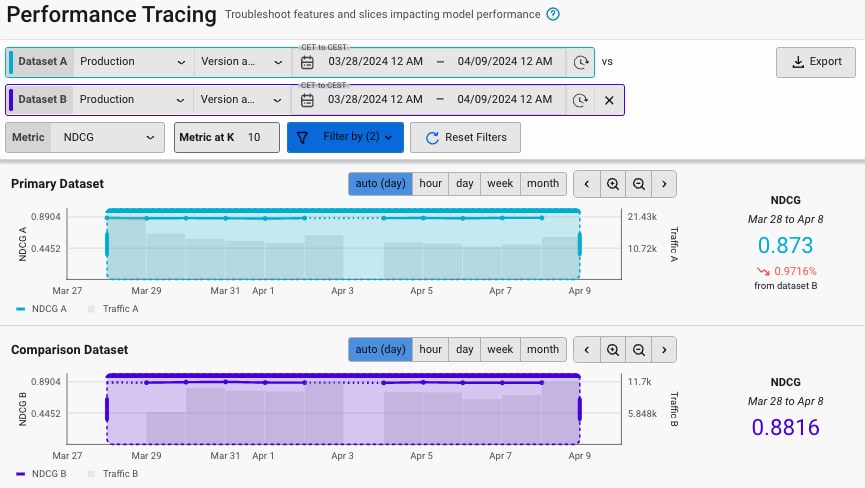
Finally, we also use Arize to help us monitor how our model’s performance changes over time. We are constantly iterating on our production ranking model to improve activity relevance and personalization for our users’ unique preferences. As we launch A/B tests, we track the Normalized Discounted Cumulative Gain (NDCG) as our primary performance metric, and Arize gives us the ability to break the performance further down into different data segments and highlight which features contribute to the model’s predictive performance the most. This gives us a broad overview of our ranking model’s overall performance at any time and allows us to identify areas of improvement, compare different datasets, and examine problematic slices.
Conclusion
Building a business-critical AI system that powers millions of daily predictions involves complex challenges. It’s not just about having robust infrastructure; it’s crucial that dynamic performance and cost efficiency are also supported while enabling rapid iteration and experimentation. Through our current infrastructure, we efficiently create a variety of feature types and operate real-time feature pipelines, all the while maintaining keen oversight on model performance and observability.
Looking ahead, we are always on a mission to further enhance our machine-learning infrastructure. In the near future, our focus is on fully embracing embeddings and providing more robust support for deep learning models. This continuous evolution will empower us to keep delivering exceptional travel experiences for our customers around the globe.
This post was originally published on the GetYourGuide blog and can be viewed here.