The Importance of Canary Testing to Ensure Feature Correctness



At Tecton, we’ve been fortunate to build a top-notch Platform Engineering team full of seasoned and talented infrastructure engineers. This has been vitally important because our customers depend on our feature platform to inject predictive capabilities into their applications so they can provide their end users with a more personalized experience.
Given the importance Tecton plays in our customers’ data stack, a top objective for our team is to ensure Tecton publishes accurate and correct feature data. Why? Because if Tecton is writing incorrect feature data, it means that our customers’ predictions will be inaccurate and negatively impact their business. The mission of our Platform Engineering team is to build the foundation for a reliable, high-performance, and scalable feature platform.
🕷As my webbed friend once said, “With great platform comes great responsibility.” (Or something along those lines.) 🕷
A major part of ensuring platform stability and reliability is having a test-first approach to development. Besides the obligatory unit and integration tests (which are table stakes for every engineering team), we are big believers in our canary pipeline, which provides signals into whether our latest changes impact our customers’ materialized feature data. This is important for us to measure because we never want our customer’s feature values calculated incorrectly due to an error or regression in our services. To help solve this problem we designed an internal canary pipeline.
Before diving deeper into our design, it’s important to take a step back and understand what an industry-standard canary release process is and why it’s valuable.
What is a canary deployment?
Traditionally, a canary deployment is a technique used by software teams to reduce the risk of introducing unstable or buggy releases into production by rolling out the changes slowly to a small subset of users before making it generally available to all users. As confidence is gained in the release candidate, it is deployed onto the remaining production infrastructure and begins handling all customer traffic.
A main benefit to a canary deployment is that it allows teams to conduct capacity testing and monitor important metrics as customer traffic ramps up. Teams can also quickly roll back to the previous stable version if there are issues identified with the latest release candidate.
It’s important to highlight that the concept of canary testing is widely adopted in distributed systems. However, applying canary testing to data accuracy and integrity is a fairly innovative approach and requires creativity to design. So without further ado…
How did we design the canary process at Tecton?
Given the nature of our product (a machine learning feature platform), we have an exact understanding of how our customers leverage our platform based on knowing how they define their features and materialize their data. While a canary deployment typically involves routing a small percentage of traffic to instances to guarantee web server correctness, our top priority is data integrity and correctness. Thus, the goal of our canary pipeline is to ensure the behavior of our customers’ data pipelines remain correct.
Our goal in designing our canary process is to make sure computed feature values are correct with the candidate release. Let’s walk through an example to paint a picture for what this means in practice:
Imagine a feature that is the trailing three-day sum of clicks by a user that is updated daily with the source data living in a Hive table with daily partitions. For batch computation, we would need to run a job each day that computes the clicks per user for the day for the latest daily partition. To get the three-day sum for a user, we would add up the last three days of precomputed data for that user. Because these jobs represent the ground truth for the customer, we need to make sure that changes to our feature computation library do not change the results.
The way we can test these jobs is by running two copies of a previous materialization job: one with the currently deployed stable (base) release and another with the candidate (new) release. We then compare the output of these two jobs and make sure they’re equivalent. In this case, we would run the latest batch job, which is the January 3 job, and compare to confirm that the output values are the same for each user.
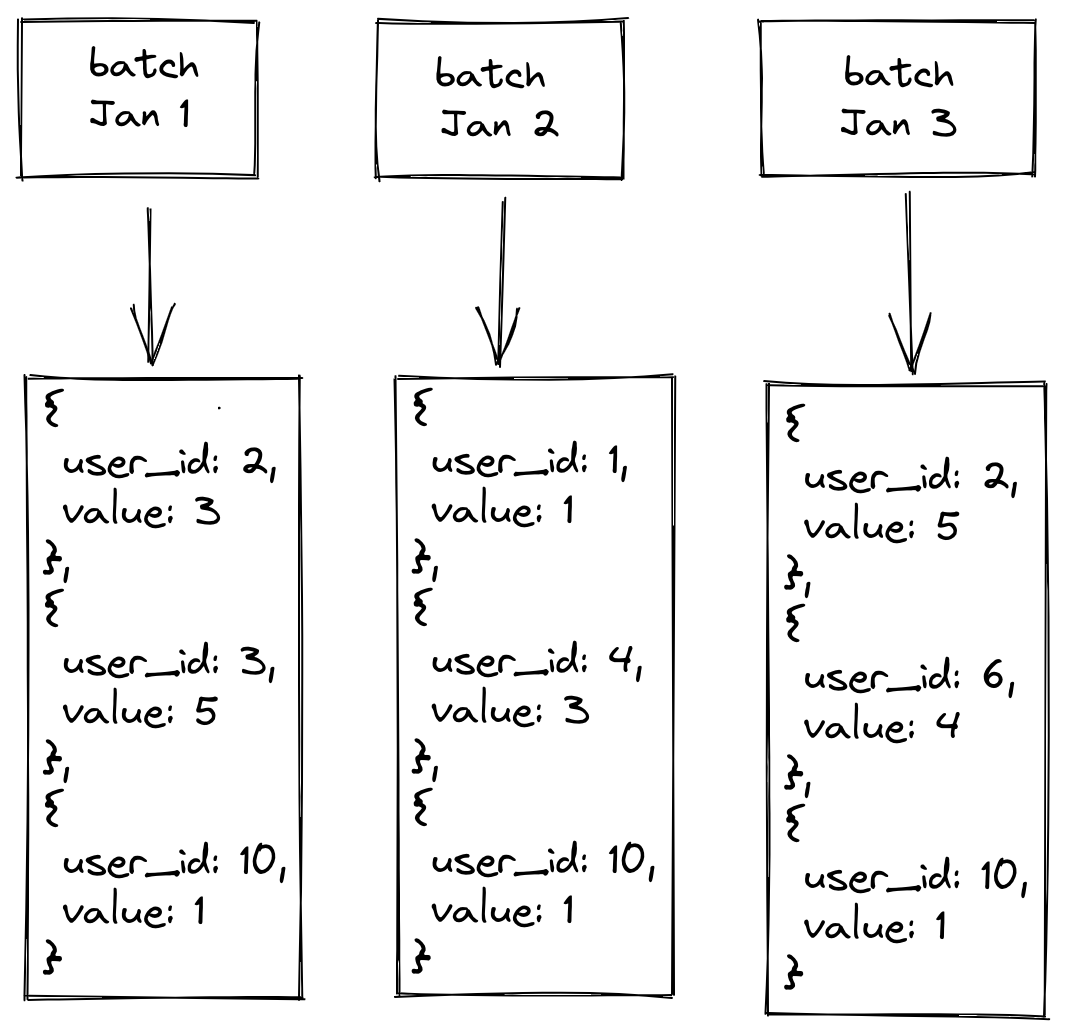
However, running this validation for each feature across all of our customers before every release would be very cost prohibitive from an infrastructure standpoint. In practice, we select a subset of features per customer and use criteria such as data source type and feature type to try to select a representative group to maximize the number of configuration permutations Tecton supports.
In addition to making sure this is cost effective, we also must ensure the process is reliable enough so that it’s easy to distinguish between legitimate differences in feature values and false positives.
Comparing the data
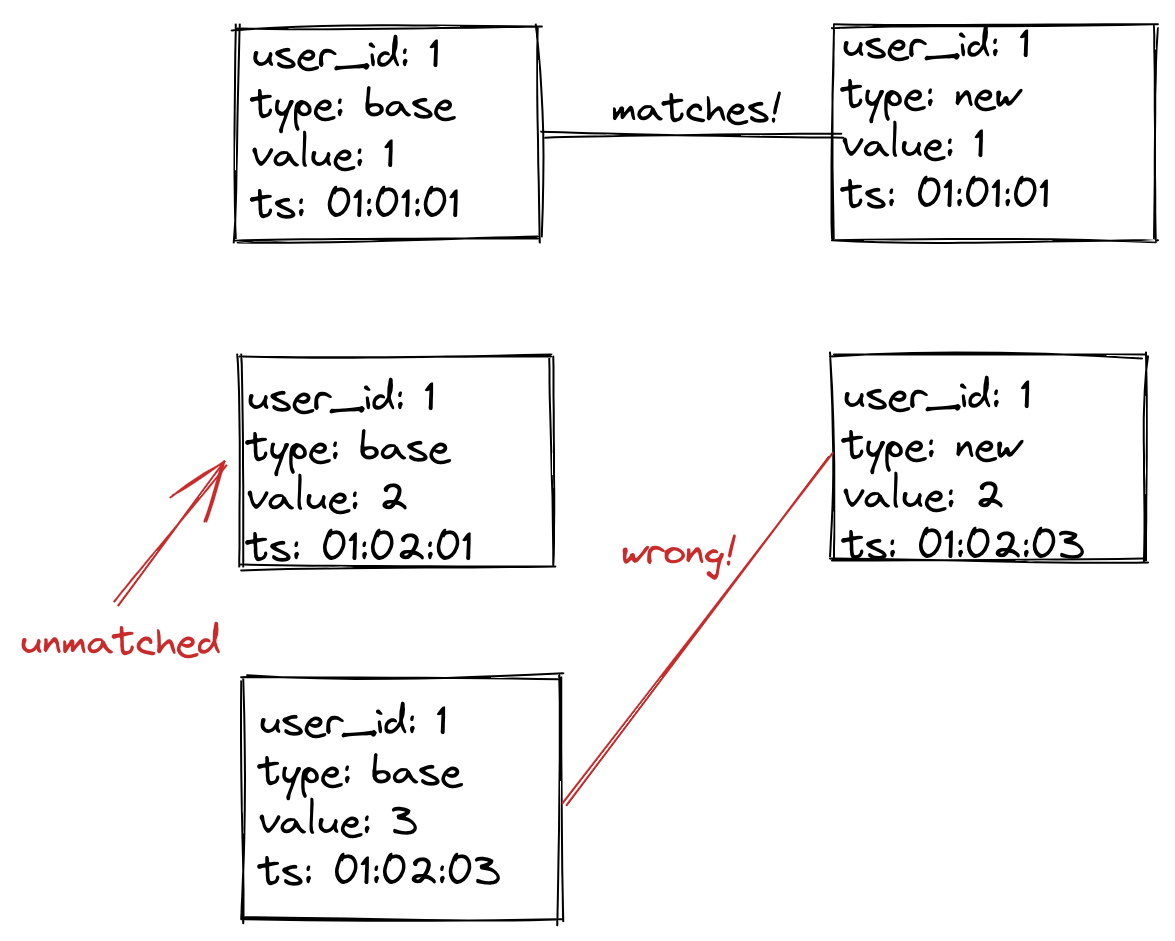
To compare data, we must match data from the join key and the timestamp. For example, our join key here is user_id and our timestamp is ts. If the join key and timestamp match, the row corresponds to the same observation.
In the above image, we have three unique join key/ts pairs. The first pair (user_id=1,ts=01:01:01) has a match, while (user_id=1,ts=01:02:01) has no match. The pair (user_id=1,ts=01:02:03) has a match, but the actual value does not match. With three unique join keys and only one having a match, we say this example has a diff of 67%. For a batch job, we would expect 0% diff, meaning we have zero tolerance for deviations. For streaming jobs, things can be a bit more tricky (more on this below).
Infrastructure
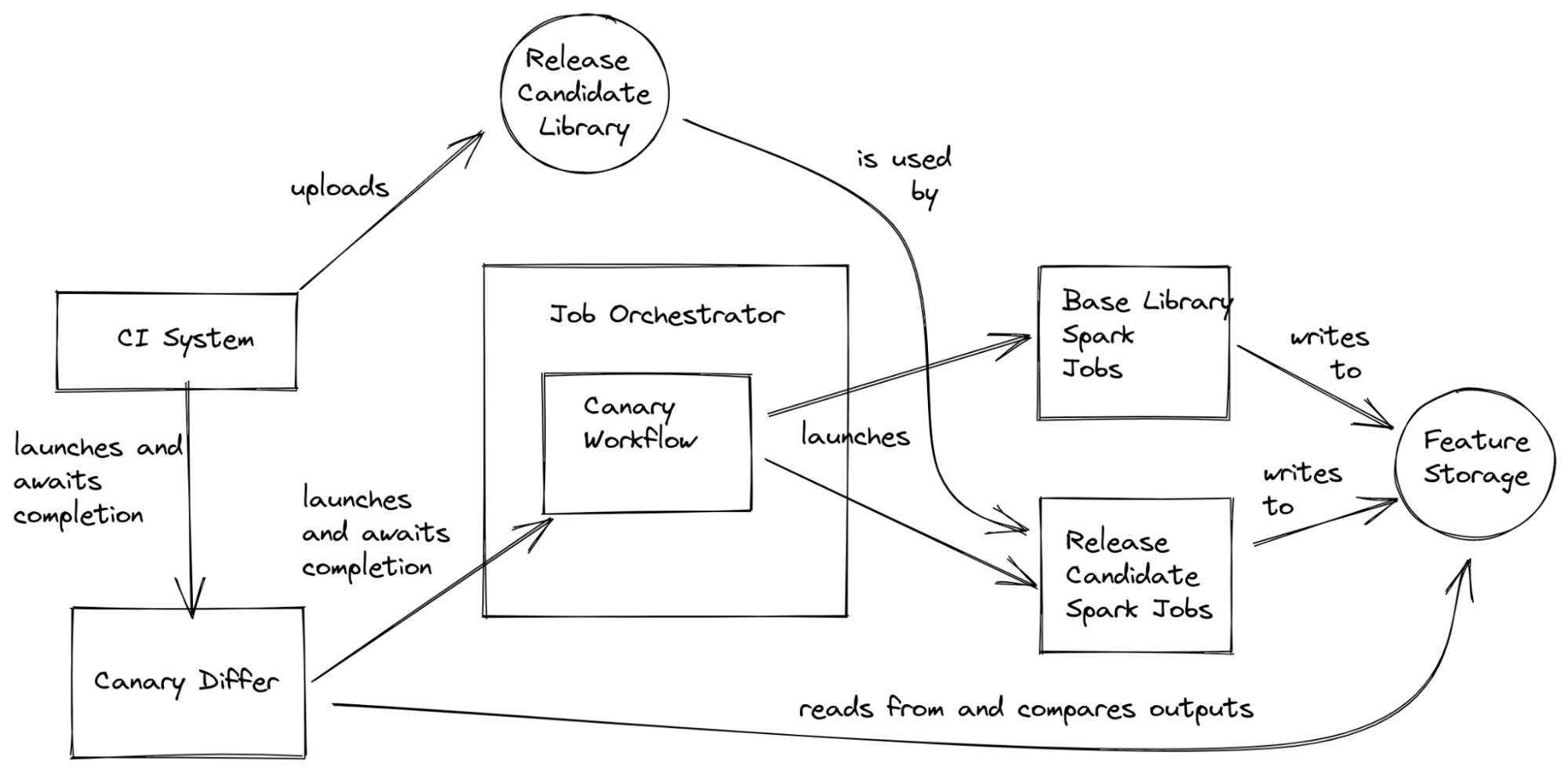
In practice, running our canary process requires touching many systems. Our CI system kicks off the canary process before doing a release by first uploading the candidate library to our library store, then launching a CanaryDiffer job. The CanaryDiffer job submits a workflow to our job orchestrator, which then takes care of launching and monitoring the compute materialization jobs, as well as cleaning up any resources after our canary process completes.
From here, the base and new candidate jobs write data to storage. The CanaryDiffer reads the state of the Canary Workflow, and when it’s time to compare, it reads the data from storage and compares the values. If everything looks good, the CanaryDiffer command reports a success, and the CI system will release the new build after acceptance by our on-call engineer. Otherwise, it reports a failure and the on-call engineer looks into the logs to try and figure out what went wrong.
Canary testing streaming jobs
In addition to conducting this validation for batch processing, many of our customers also leverage streaming data sources to power their machine learning.
Streaming data is unpredictable because data arrives sporadically and certain partitions can lag behind. Additionally, we need the two stream jobs (base and new) to start reading data at exactly the same point. Also, it is not feasible to cut off the stream processing at the exact same time. This means we must do our best to align the beginning and end of our stream output data.
While we could simply filter the output data by the feature timestamp, this won’t cut it because many of our jobs compute aggregations. So if streams start at different points, one may see more data. This is also true for the ending point because an earlier reported aggregation may be updated with late arriving data.
Aligning the beginning of the stream is easy; we just record the position of the stream in production, then use this same position for both the base and new jobs. On the other hand, handling the end of the stream is extremely tricky.
One approach is to look at the latest timestamp written to storage from the stream and use that as a watermark. One might expect that anything before the watermark is complete—but this is not true because data is not always ordered in the stream. Additionally, using wall clock time is also insufficient because data can arrive late. To make things worse, streams actually consist of multiple substreams (called partitions), and these may not be processed at the same rate.
Our approach is a “best effort” one that gives us a good approximation and works well across different streaming sources and platforms (mainly Kafka and Kinesis), with different guarantees and APIs.
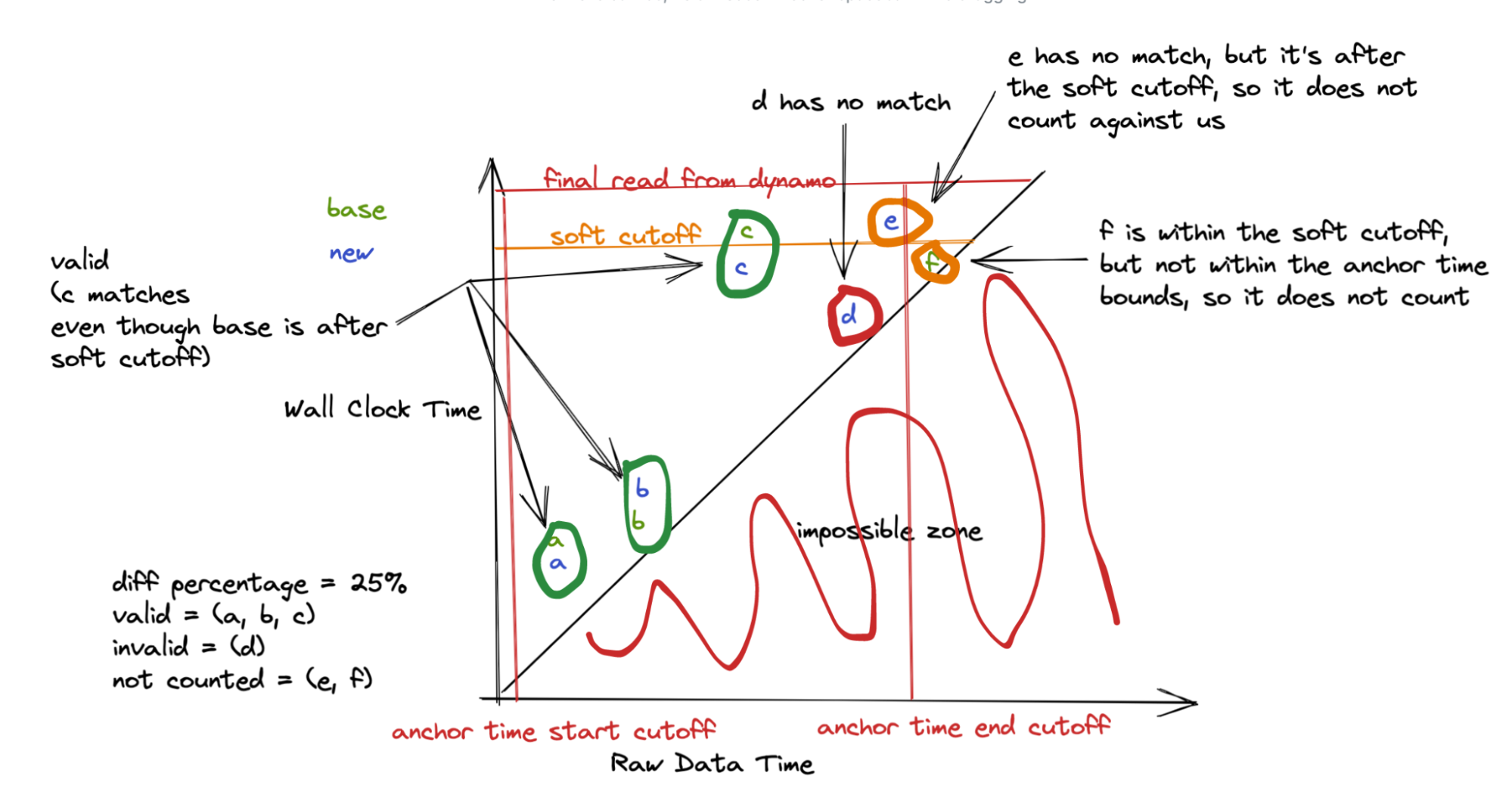
One key observation is that even though data can arrive late and partitions can lag, they usually do not—and if they do, they don’t do it by too much. We also aim to witness a certain range of data. For example, we may want complete data from the start time of the job to 30 minutes after (which we call the end time).
Once we see a feature value that occurs after our end time, we start a timer and record the time as our soft cutoff. At this point, we are waiting for a set amount of time (say, 15 minutes) to allow the streams to catch up. After the time has elapsed, we collect the data. This is our hard cutoff.
We look only at records with a feature timestamp between our start and end time, comprising exactly 30 minutes in this case. Additionally, for any records written at a wall-clock time after our recorded time, we place this to the side. For these late records, we don’t count them against our diff, only using them to match to a corresponding record written before the soft cutoff. This means any record written before the soft cutoff should have a matching record in the complementary stream output, which can be after the soft cutoff (but is before the hard cutoff). But if it is written after, we don’t require a match for it. So as long as our two streams are no more than 15 minutes apart, we will not observe any difference in data.
However, even this approach is not perfect, so we set a small error tolerance to account for these cases to avoid setting off false alarms.
Canary and errors in the real world?
In theory all of this sounds great, but what happens when a customer writes a non-deterministic feature? Or when there’s an outage in one of our cloud providers, causing the data to look incomplete? What if the data gets shuffled differently and our floating point additions happen in a different order?
The real world is messy, and we need our tooling to help our on-call engineers make sense of this. Although we implement canary retries, sometimes errors may persist. There are many external factors that could cause canary failures, such as low spot instance availability, for example. It’s important that we surface these concerns so on-call engineers don’t spend time digging into something that isn’t relevant. When we notice a job terminating many times, we add a warning to the logs.
Sometimes, a customer’s feature pipeline may just have non-deterministic results. For example, they may use the current timestamp in calculation of a feature. In these cases, we have an escape hatch in that we can disable a feature from being selected for canarying.
How the canary process helps us provide a better customer experience
Our canary process is useful for detecting day-to-day regressions, but it’s been even more useful in rolling out large changes with high possibility for breakage. One such project was upgrading our Spark compute version from 2 to 3 across all our customers. Being able to use this process to test the changes across versions was tremendously helpful, saving us manual testing time and helping us suss out issues ahead of time.
For example, we found some customer features relied on timestamp behavior in Spark 2 that changed in Spark 3. For some of these features, the job failed with an error message, but for others, the output features were slightly modified. We were able to then work with these customers to change their queries in a way that would work correctly with Spark 2 and 3, canary it again, and then roll it out.
We were ultimately able to migrate all of our customers successfully, without data correctness issues or jobs failing due to version incompatibilities. In the future, our canary process will help us roll out riskier changes with more confidence—for instance, as we improve our query optimization layer, we want to be sure that there aren’t any unexpected correctness issues.
Our canary process has helped prevent rolling regressions into production as well as increased our development velocity by allowing us to more easily test changes—which enables us to provide Tecton customers with the most reliable and stable machine learning platform.
If you’re a passionate infrastructure engineer or are just interested in learning more about some of the technical challenges we face, keep an eye on our blog—this is the first in a series of engineering blog posts we have planned for the year. Or, if you’d like to help us make Tecton better for everyone, feel free to check out our careers page for opportunities!