apply() Highlight: How Feature Logging Enables Real-Time ML


Generating training data for an online, real-time machine learning system can be tricky. In order to guard against temporal data leakage, training events must use only historical features that were valid as of that point in time. This requires effectively backfilling feature data with correct historical timestamps and complicated joining logic to synthesize accurate training sets. This approach is outlined in our blog: Back to the Future: Solving the time-travel problem in machine learning.
However, there is another way to conveniently generate historically accurate training data without requiring complicated time-travel queries. New feature values can be fetched online at inference time and then logged offline to use for later training.
For example, if we have a model serving product recommendation predictions online and we want to test a new feature, user_click_count_7d, then we can compute and fetch this feature online alongside the other features that the model will use for inference. The products that we then choose to show to the user will become our training events (product impressions) and later we can join in ground truth labels: product clicks. Because we now have the logged set of features for each event, we can simply use those for training our model and know that they are historically accurate.
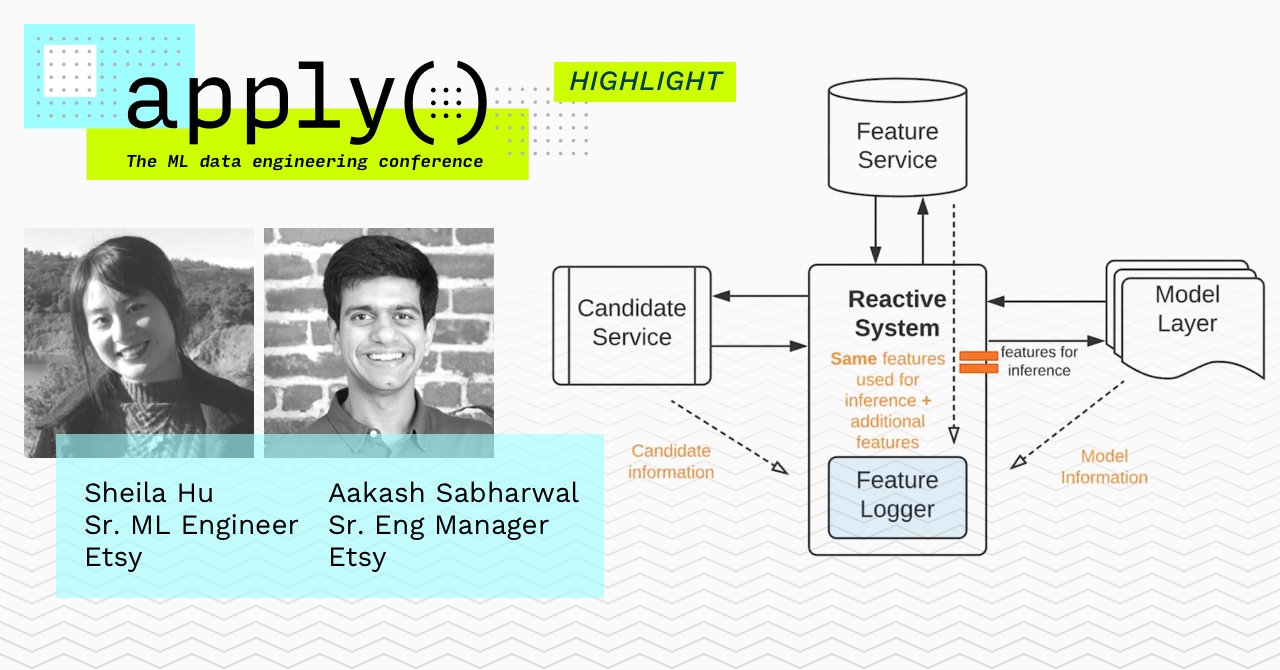
This approach to training data generation is common at many tech companies and works particularly well when new training events can be collected rapidly and teams can afford to wait for new feature logs to accumulate. At the apply() conference in April, Sheila Hu and Aakash Sabharwal spoke about how they incorporated Feature Logging as a critical component in the Etsy ML Platform.
Other Benefits of Feature Logging
Feature Logging also has additional benefits besides training data generation. These logs can be used for auditing and explainability of models as well as custom analysis and data quality monitoring. By running data quality checks on the features that are served to production models, teams can guard against broken data pipelines or unexpected data (e.g. user ages below 0). Additionally, by comparing the distributions of feature data between the feature logs for a model and its training data set, teams can identify and alert on data drift between training and serving (an indication that the model is going stale and needs to be retrained).
Feature Logging in Tecton
Feature Logging capabilities are built natively into Tecton and can be enabled with a single parameter as shown below.
from tecton import FeatureService, LoggingConfig
product_recommendation_service = FeatureService(
name='product_recommendation_service',
features=[
product_ctr,
user_age,
user_click_count_7d
],
logging=LoggingConfig(sample_rate=0.8)
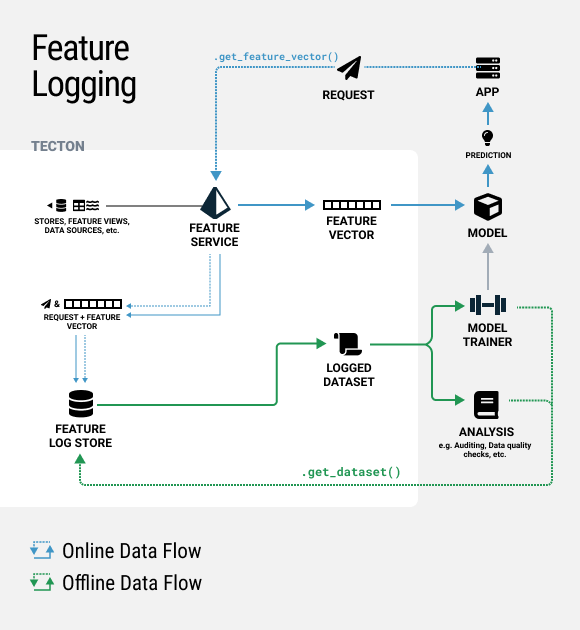
)When enabled, Tecton will log all requests to a Feature Service supporting a given model as well as the returned feature vectors. This dataset can then be easily accessed via Tecton’s SDK in a notebook or found directly on S3 and used for model training or analysis, as outlined in the diagram below
Soon Tecton will also be launching native data quality monitoring capabilities that allow users to create custom validations on feature data and monitor for data drift between training and serving. In the future, we also plan to enhance Tecton’s logging capabilities with custom metadata and label management.
To learn more about how Tecton enables real-time machine learning, read our documentation or sign up for a free trial. To check out more talks from the apply() Conference in April or register for the apply() Meetup in August, click here.