Introducing Low-Latency Streaming Pipelines for Real-Time Machine Learning


We’re excited to announce that Tecton now automates low-latency streaming pipelines to help organizations quickly and reliably build real-time machine learning models.
What is real-time machine learning (ML)? Real-time ML means that predictions are generated online, at low latency, using real-time data; new events are reflected in real-time in the model’s predictions. Real-time ML is valuable for any use case that needs very fresh data, such as fraud detection, product recommendations, and pricing use cases. These use cases need to make predictions on the events that happened over the past few seconds, not just the past day.
Tecton low-latency streaming pipelines allow data teams to:
- Automatically process features from streaming sources like Kafka or Kinesis, eliminating the need to build and operate custom pipelines
- Provide sub-second feature freshness
- Automatically backfill features from batch sources
- Process time aggregations efficiently at scale
In this blog, we’ll talk about the common challenges of processing ML features from streaming sources, then go into more detail on the new Tecton capabilities.
Challenges of streaming pipelines for real-time ML
Streaming platforms like Apache Kafka and AWS Kinesis are the most common data sources for real-time machine learning use cases. They provide raw data with latencies on the order of milliseconds. However, streaming data is much more difficult to operationalize than batch data and presents the following technical challenges:
- Building streaming pipelines. Most data scientists lack the expertise to build streaming pipelines, which require production-grade code and specialized stream processing tools like Spark Streaming, Apache Flink, or Kafka Streams. So data scientists hand off their features to highly skilled data engineers to build custom streaming pipelines that reimplement the data scientist’s feature logic. This process can add weeks or months to the lead time for deploying a new model.
- Combining batch and streaming data. The streaming pipelines continuously process fresh feature values which can be served online for real-time inference. But we still need to process historical data to generate training datasets, and to backfill the feature values during cold starts. Without the backfill, it may take weeks or months of processing to completely populate an online store from the stream.
The historical data often doesn’t reside in the stream itself, because streaming platforms are typically configured to retain only a limited amount of data. So data engineers need to build batch pipelines that efficiently process large-scale data from offline sources (e.g. data lake, data warehouse) that mirror the stream (event logs, or materialized tables of historical value). This in turn introduces more complexity. How do we ensure parity between the streaming and batch transformation logic? How do we ensure time consistency between online and offline data? When these requirements aren’t met, features suffer from training-serving skew which ultimately reduces prediction accuracy. - Processing time window aggregations. As explained in our blog “Real-Time Aggregation Features for Machine Learning (Part 1),” processing rolling time window aggregations for real-time predictions in production poses a difficult problem: How can you efficiently serve such features that aggregate a lot of raw events (> 1000s), at a very high scale (> 1000s QPS), at low serving latency (<< 100ms), at high freshness (<< 1s), and with high feature accuracy (e.g. a guaranteed and not approximate time window length)? This is a very hard problem that data engineers have to solve for every time aggregation feature that gets rolled out to production.
Because of these challenges, many organizations choose to use only batch data for their features. Alternatively, some organizations decide to build custom streaming pipelines, often at the cost of adding weeks or months to deployment timelines, and potentially limiting prediction accuracy due to training / serving skew.
Tecton low-latency streaming pipelines
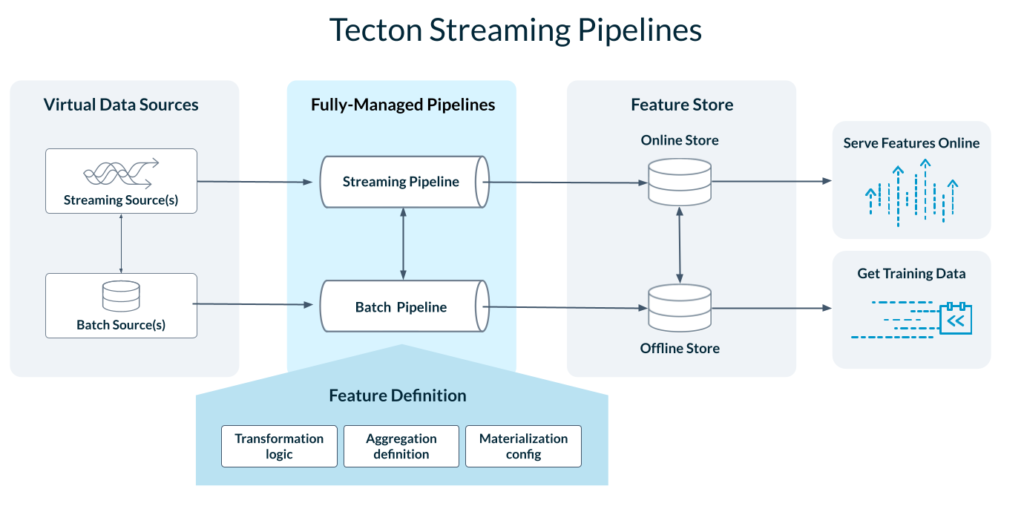
Tecton allows data teams to define their transformation logic in simple feature definitions, then automatically orchestrates the streaming pipelines to transform the data.
Breaking down the key capabilities, Tecton:
- Automates streaming ML pipelines. Tecton eliminates the need to build pipelines using stream processing engines like Apache Flink and Spark Streaming. Instead, data teams use simple Tecton primitives to define their transformation logic. Tecton automatically executes the transformation logic in a fully-managed data pipeline, using an appropriate stream processor like Spark Streaming. Tecton delivers sub-second freshness and ensures enterprise-grade uptime, latency, and throughput.
- Combines streaming and batch sources to backfill features. Streaming features need to be backfilled to generate training data and to populate the feature store during cold starts. Tecton orchestrates batch pipelines to generate the backfills. These pipelines use batch data sources that mirror the streams (event log, materialized tables of historical values). Tecton applies the same transformation logic and ensures point-in-time consistency between the batch and streaming pipelines to eliminate training / serving skew.
- Provides efficient and scalable time window aggregations. As outlined in the blog entry “Real-Time Aggregation Features for Machine Learning (Part 2),” Tecton provides an optimized approach to processing time window aggregations – by far the most common feature type used in real-time ML applications. Older events are pre-processed and compacted into tiles, while the latest events are aggregated on-demand at serving time. The optimized implementation combines the benefits of fresh feature values (sub-second), fast serving times (sub-10 ms), cost-efficient compute and memory, and support for backfills. Most importantly, these optimizations come out of the box.
With Tecton, ML teams who are already using streaming sources can now build and deploy models faster, increase prediction accuracy by eliminating training / serving skew, and reduce the load on engineering teams, as described in the Atlassian case study. ML teams that are new to streaming can now build a new class of real-time ML applications that require fresh feature values, such as fraud detection models.
Conventional streaming pipelines vs. Tecton low-latency streaming pipelines
The table below provides a summary of the problems typically encountered with custom streaming pipelines vs. the advantage of using Tecton.
| | Custom pipelines (typical problems) | Tecton low-latency streaming pipelines |
|---|---|---|
| Lead time and effort to build | Weeks to months required to build and deploy | Hours to deploy |
| On-going pipeline management | Self-managed without SLA guarantees | Fully-managed by Tecton |
| Feature freshness | Sub-second achievable for simple transformations | Sub-second, including for time aggregations |
| Feature serving latency | Not built in – requires additional plumbing to a serving store | Sub-10 ms |
| Training data | Risk of Training / serving skew Plumbing required to store features in an offline store that’s used for training | Guaranteed Training / serving parity Built-in support to store historical features in an offline store |
| Backfills | Backfills from offline sources (e.g. data lake) require manual plumbing | Automated backfills |
| Temporal aggregations | Difficult to achieve scale (>1000 QPS) with high freshness (<1 second) and low serving latency (< 100 ms) Infrastructure costs can be prohibitive | Highly scalable (>1000 QPS) with high freshness (<1 second) and low serving latency (<100 ms) Cost-optimized |
Conclusion
Many organizations want to deploy real-time ML, but struggle with its operational requirements. Processing real-time data into fresh features is often the hardest part of implementing real-time ML. Building custom streaming pipelines can add weeks or months to a project’s delivery time.
At Tecton, we’ve been hard at work building the most complete feature store in the industry. With our new low-latency streaming pipelines, we automate the most difficult step in the transition to real-time ML: the processing of features from streaming data sources. We have several customers using our streaming pipelines in production, and are excited to bring this capability to all our users.
If you’re building real-time ML models and want to learn more, please shoot us an email at hello@tecton.ai, reach out on Slack, or request a free trial. We’ll be happy to discuss your project in more detail.