Journey to Real-Time Machine Learning



We speak with hundreds of enterprise machine learning teams every year. And we’ve observed a typical pattern for the adoption of machine learning in the enterprise. Not every organization follows the exact same steps, but we’ve seen the pattern validated enough times that it certainly feels like a common adoption journey. This blog post aims to document that journey to help organizations better understand where they are and what the next steps in their evolution may look like.
What is real-time machine learning?
The aspirational objective is to rapidly build and deploy real-time machine learning (ML) models at scale; i.e., hundreds of models serving high volume requests or QPS with low-latency prediction. Real-time ML is characterized by the following attributes:
- Powers mission-critical applications: Models aren’t just used to generate batch predictions for human-in-the-loop decisions (such as sales forecast or churn reports), but are integrated with mission-critical applications. For example, they may be used to support customer-facing real-time pricing or product recommendations, or to automate critical business processes like fraud detection.
- Makes predictions online with enterprise SLAs: Models are deployed in production and serve predictions online, often with millisecond latencies and tight SLAs. These requirements mirror the requirements placed on the mission-critical apps that the models support.
- Uses real-time data with sub-second freshness: While not all models need real-time data, there are many use cases where real-time data can significantly improve prediction accuracy. For example, fraud detection models need data on what a user has been doing for the past few seconds, not just the past few days. Similarly, real-time pricing models need to incorporate the supply and demand of a product at the current time, not just from a few hours ago. Models must be able to consume real-time data sources and make predictions with sub-second data freshness. Real-time (and near real-time) data sources include event streaming platforms like Kafka, or data passed to the model at inference time such as user clickstreams.
Requirements for real-time ML
Real-time ML is an aspirational objective which most organizations haven’t reached yet—at least not in a scalable and cost-efficient manner. What’s holding them back? A multitude of changes are required to evolve from the world of traditional analytics to real-time ML:
- Data science expertise: The most obvious—and perhaps easiest change to implement—is bringing data science expertise into the organization. You need a team of data scientists who can explore data, engineer features, train models, and evaluate them.
- ML engineering expertise and processes: Models need to be deployed to production quickly and reliably, which requires developing an operational muscle. Many organizations are developing a new function to bridge the gap between data science and engineering: the ML Engineer or MLOps Engineer. They are responsible for deploying and managing ML in production while infusing engineering best practices (DevOps for ML) into the team’s processes.
- MLOps tooling: On the tooling side, data teams need new tooling to build production ML systems. There’s a whole ecosystem of new MLOps tools being developed, the most critical of which are model serving platforms, feature stores, and ML monitoring tools. Adopting these tools and integrating them into development processes takes time and resources.
Journey to real-time ML
The adoption of real-time machine learning is complex and requires deep changes within an organization. Instead of jumping straight into real-time ML, most organizations follow a multi-step transition as they tackle the many different requirements along the way.
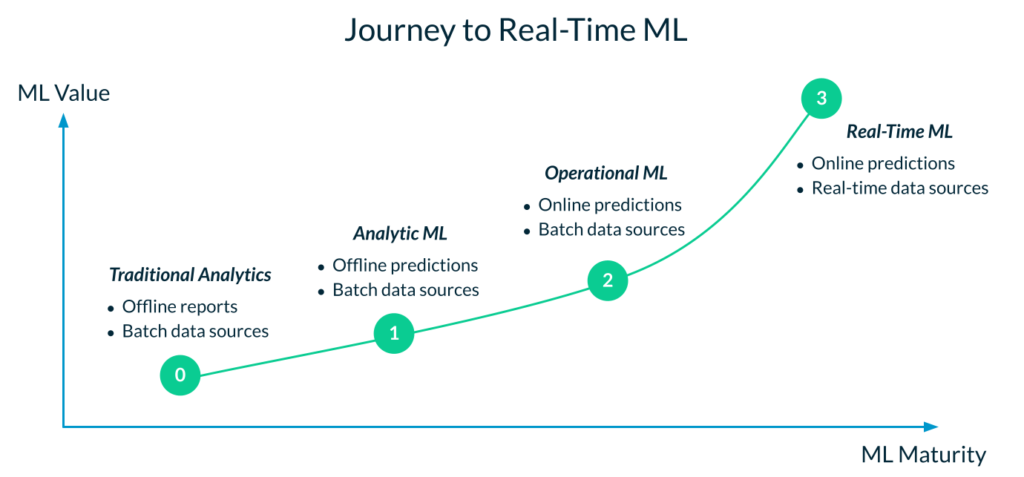
- Step 0: Traditional analytics. This is the starting point for most enterprises, and consists in generating offline analytics (e.g., daily reports, dashboards and visualizations) for human decision makers. For example, an analytics team may provide daily sales updates, inventory status, or customer churn data to the General Manager of a Department.
- Step 1: Analytical ML. This is typically the first—and simplest—step on an organization’s ML journey. It complements traditional analytics with offline ML predictions, still supporting human decision-making. In addition to daily analytics reports, data teams provide daily, batch-generated ML predictions. Because analytical ML is limited to informing decisions, data teams don’t need to invest in reliability. If the job fails to run or the results are unintuitive, a data scientist can fix the report later in the day with minimal cost to the business.
Most importantly, this also means that data teams can continue to operate with their existing organizational structure and processes. Data scientists can be mostly self-sufficient with their data and ML models, as long as they have access to the raw data (preferably in a centralized data platform). The emphasis is on data science, with MLOps or ML engineering mostly an afterthought. Likewise, tooling is mostly focused on data science workflows, for example for data exploration, batch data preparation, model training and optimization. There is limited emphasis on model serving, production data pipelines, and ML monitoring. - Step 2: Operational ML. Operational ML consists in generating online predictions to power ML applications. For example, an online retailer can use operational ML to provide online product recommendations to its customers. In the early stages of the transition to operational ML, teams often experiment with a relatively small number of models and applications.
The transition to operational ML is complex because it requires deploying models to production and serving features online, which in turn requires new tooling and processes. Specific to data, operational ML requires production-grade data pipelines and the ability to serve features with enterprise SLAs. In the early stages of operational ML, pipelines are kept relatively simple by using only batch data sources to pre-compute feature values. These features are then stored in an online store for low-latency serving with production SLAs. This is where feature stores typically first come into the picture to simplify the process of serving features online. - Step 3: Real-time ML. As organizations mature in their use of operational ML, they often uncover a multitude of use cases that require real-time features, often with data freshness requirements in the order of milliseconds. Due to the tight freshness requirement, these features can’t be processed from batch data, but instead are built using streaming or real-time data sources.
Building features from real-time data sources introduces additional complexity, because data teams now have to operationalize more complex data pipelines. These pipelines have to process data at low latency, manage backfills to eliminate training / serving skew, while performing complex operations like time window aggregations. This is where a complete feature store like Tecton can accelerate the process significantly by orchestrating low-latency streaming pipelines for ML.

Conclusion
The journey to real-time ML is complex and introduces many requirements on data teams. Not only do organizations need to develop data science expertise, they also need to build the operational muscle to deploy and manage models and features in production. This requires the introduction of ML engineers, engineering best practices like DevOps, and new MLOps tooling. The data side of this transition is particularly challenging because it requires complex data pipelines that can process features with sub-second freshness. Organizations embarking on their ML journey should assess their current capabilities and plan their evolution to enable real-time machine learning at scale.