

Taking a model from research to production is hard — and keeping it there is even harder! As more machine learning models are deployed into production, it is imperative to have tools to monitor, troubleshoot, and explain model decisions. Join Amber …

ralf: Real-time, Accuracy Aware Feature Store Maintenance
Feature stores are becoming ubiquitous in real-time model serving systems, however there has been limited work in understanding how features should be maintained over changing data. In this talk, we present ongoing research at the RISELab on …

More ethical machine learning using model cards at Wikimedia
First proposed by Mitchell et al. in 2018, model cards are a form of transparent reporting of machine learning models, their uses, and performance for public audiences. As part of a broader effort to strengthen our ethical approaches to machine …

Machine Learning in Production: What I learned from monitoring 30+ models
It’s a software monitoring best practice to alert on symptoms, not on causes. “Customer Order Rate dropped to 0” is a great alert: it alerts directly on a bad outcome. For machine learning stacks, this means we should focus monitoring on the output …

Wild Wild Tests: Monitoring Recommender Systems in the Wild
As with most Machine Learning systems, recommender systems are typically evaluated through performance metrics computed over held-out data points. However, real-world behavior is undoubtedly nuanced, and case-specific tests must be employed to ensure …

Data Observability for Machine Learning Teams
Once models go to production, observability becomes key to ensuring reliable performance over time. But what’s the difference between “ML Observability” and “Data Observability”, and how can ML Engineering teams apply them to maintain model …

Machine Learning Platform for Online Prediction and Continual Learning
This talk breaks down stage-by-stage requirements and challenges for online prediction and fully automated, on-demand continual learning. We’ll also discuss key design decisions a company might face when building or adopting a machine learning …

Model Calibration in the Etsy Ads Marketplace
When displaying relevant first-party ads to buyers in the Etsy marketplace, ads are ranked using a combination of outputs from ML models. The relevance of ads displayed to buyers and costs charged to sellers are highly sensitive to the output …
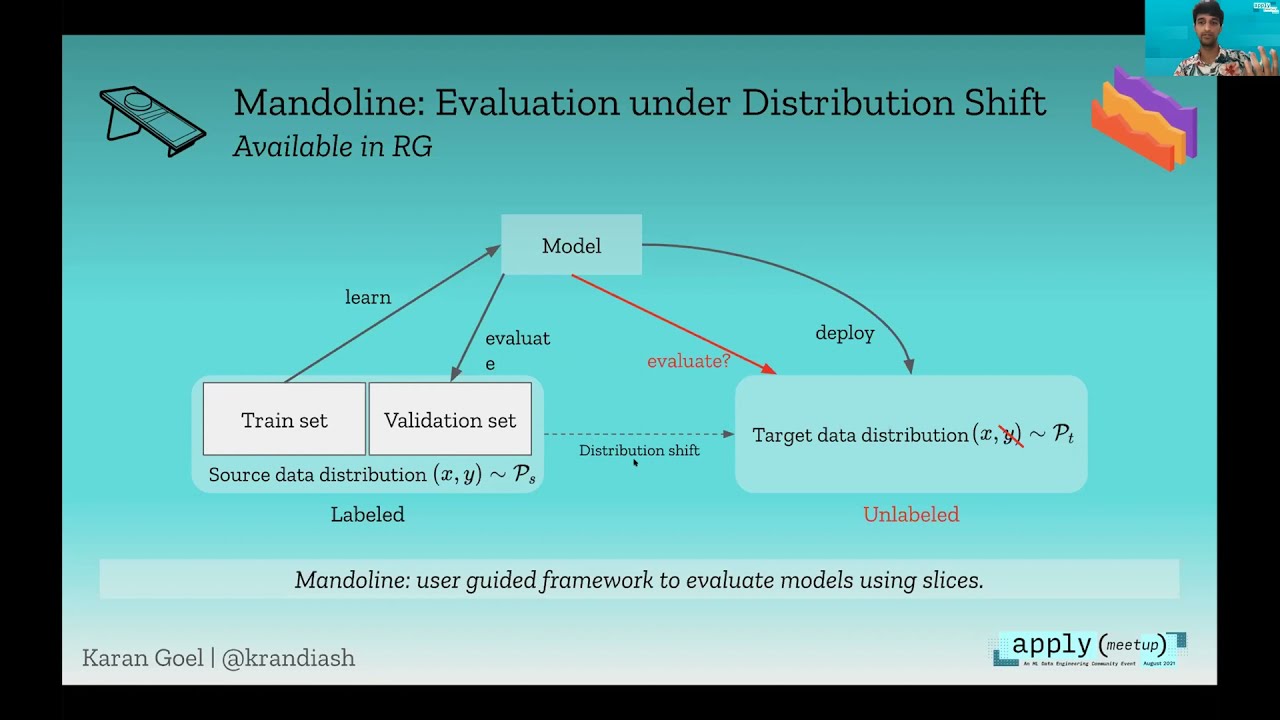
Building Malleable ML Systems through Measurement, Monitoring & Maintenance
Machine learning systems are now easier to build than ever, but they still don’t perform as well as we would hope on real applications. I’ll explore a simple idea in this talk: if ML systems were more malleable and could be maintained like …
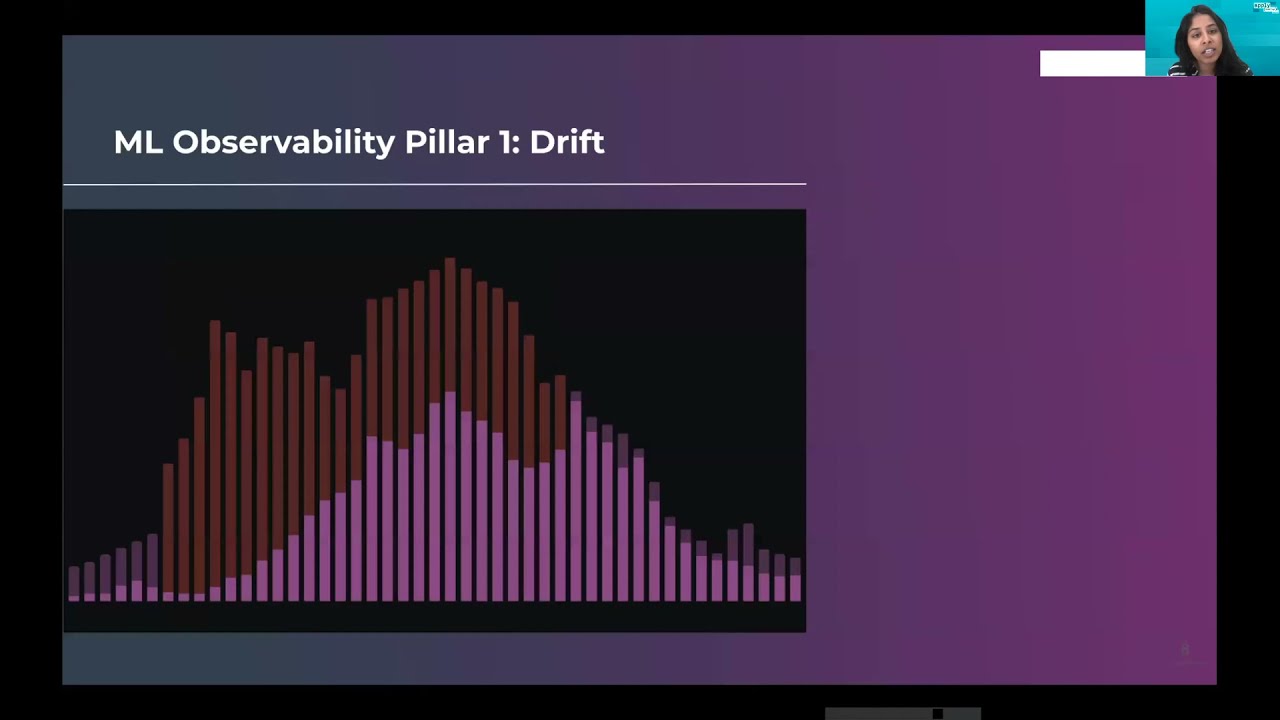
ML Observability: Critical Piece of the ML Stack
As more and more machine learning models are deployed into production, it is imperative we have better observability tools to monitor, troubleshoot, and explain their decisions. In this talk, Aparna Dhinakaran, Co-Founder, CPO of Arize AI (Ex-Uber …

MLOps Done Right with Centralized Model Performance Management Powered by XAI
Machine Learning brings success to any business through additional revenue and competitive advantages. But due to its high reliance on data, it is natural for ML models to degrade in performance over time. Whether it be from data drift or integrity, …

Data Observability: The Next Frontier of Data Engineering
As companies become increasingly data driven, the technologies underlying these rich insights have grown more nuanced and complex. While our ability to collect, store, aggregate, and visualize this data has largely kept up with the needs of modern …