Getting Started With Amazon SageMaker & Tecton’s Feature Platform



SageMaker has emerged as a leading machine learning platform for enterprises running on AWS. Similarly, Tecton has emerged as the feature platform of choice for enterprises running machine learning (ML) in production. Tecton makes it very easy to productionize feature pipelines (the process of transforming raw data into features). This lets you serve polished features for consumption by both data scientists (for training) and models running in production (for inference).
A common question we get is: How can I integrate Tecton’s feature platform with SageMaker?
The answer is two-fold:
- For model training, data scientists can use Tecton’s SDK within their SageMaker notebooks to retrieve historical features.
- For production models doing online inference, the Tecton feature platform integrates with any SageMaker endpoint via our low-latency, feature-serving API.
This post explains how to use Tecton with Amazon SageMaker. We’ll walk through how you can train and deploy your first model using Tecton without leaving the SageMaker environment.
Note that this isn’t a comparison between the Tecton platform and the AWS SageMaker feature store. If you’re looking for that, read our blog on how to choose the right feature store on AWS.
Connecting SageMaker to the Tecton SDK
Tecton’s SDK allows users to interact with Tecton directly via SageMaker notebook instances. For example, a data scientist can quickly fetch training data for a model by calling get_historical_features.
Tecton leverages Apache Spark on Amazon EMR to generate very large training data sets. In order to use the Tecton SDK, you’ll need to connect SageMaker to a Tecton-managed EMR cluster.
Fortunately, AWS released an easy integration path for SageMaker and EMR that consists of the following steps:
- Initiate a CloudFormation EMR template
- Create a product for the EMR template in AWS Service Catalog
- Set up and connect to the EMR cluster in SageMaker
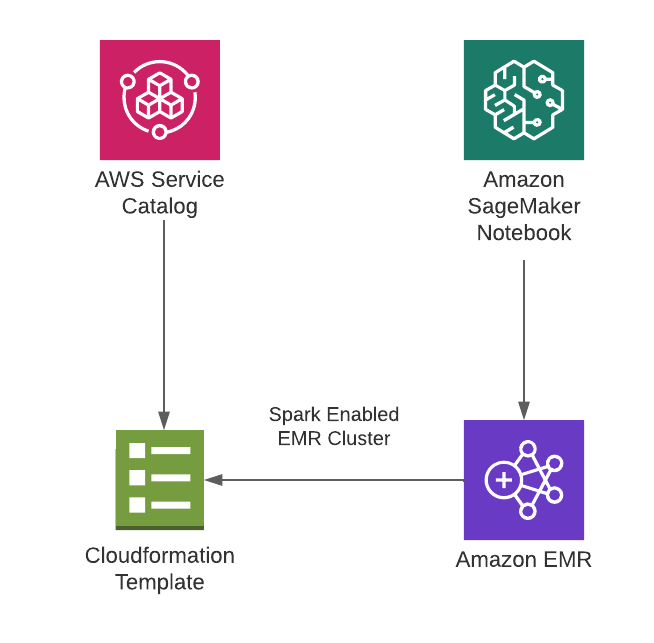
A solutions architect at Tecton will provide the necessary CloudFormation template for a Tecton-managed EMR cluster. You can further customize the template by adding bootstrap scripts or using custom AMIs per your organization’s requirements.
After setting up the EMR template in AWS Service Catalog, you’ll just need to connect it to your SageMaker notebook. In the notebook’s SageMaker resources pane, you’ll see a dropdown labeled Clusters. From here, you can view (and, if necessary, create) EMR clusters directly through the SageMaker notebook. You should see the Tecton-managed EMR cluster in the list.
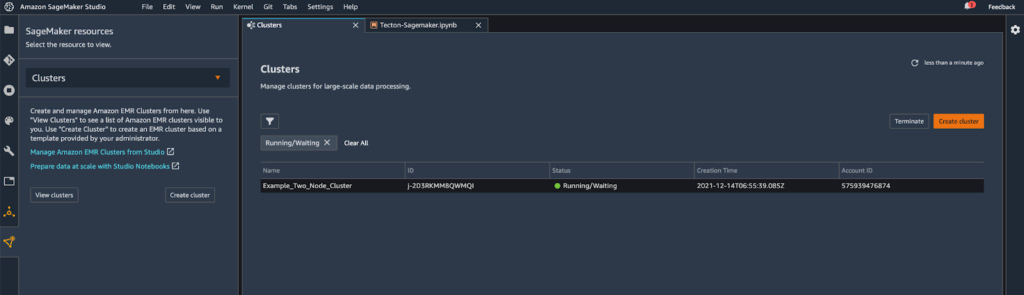
In order to use the Tecton-managed EMR cluster, you’ll need a kernel that has PySpark (SparkMagic) enabled. Follow the instructions here to connect to the cluster. Once connected, you can simply import the Tecton SDK and start working with it.
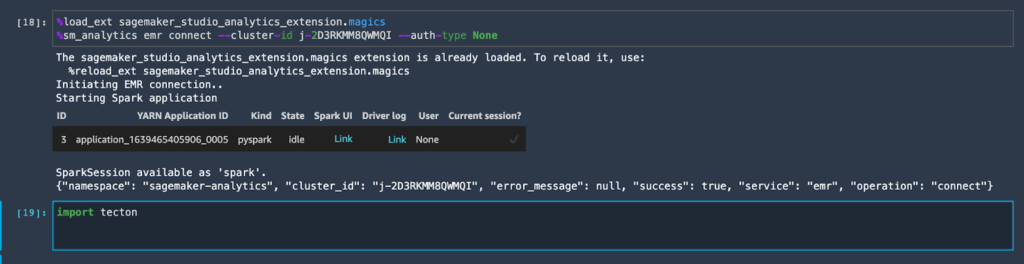
Understanding the Tecton SDK
The Tecton SDK has APIs that you can use for both data exploration and model training. For example, the SDK allows you to visualize and work with raw data sources that have been registered in Tecton.
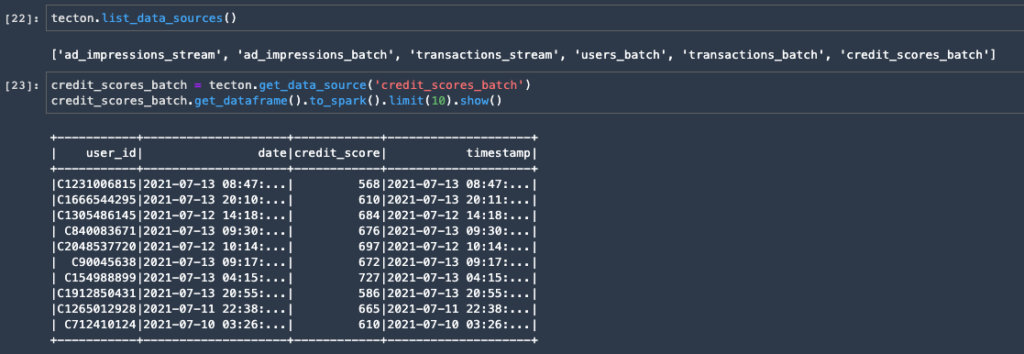
In order to understand the SDK methods, it’s important to review the terminology Tecton uses: Data Sources, Transformations, Feature Views, and Feature Services. We’ll describe each briefly below (see our documentation for more details).
Data Sources: Raw data can either be streaming data sources like Kafka and Kinesis, or batch data sources like Redshift, Snowflake, Hive tables, and S3.
Transformations: Features are often the result of a transformation that is applied to raw data. For example, aggregations are a common kind of transformation. In Tecton, transformations can be as simple as a SQL statement or basic Python code, or as complex as PySpark code.
Feature Views: A transformation can emit one or more features. The features that result from one transformation are grouped into a Feature View.
Feature Service: A Feature Service is a grouping of Feature Views, and there is a one-to-one relationship between a Feature Service and a model.
Training a model
In order to train a model, you’ll want to use get_historical_features from a specific Feature Service. This method requires as input a dataframe that contains entity IDs and timestamps. Tecton will then augment the dataframe with all the features associated with the model, resulting in the data set you need for training.
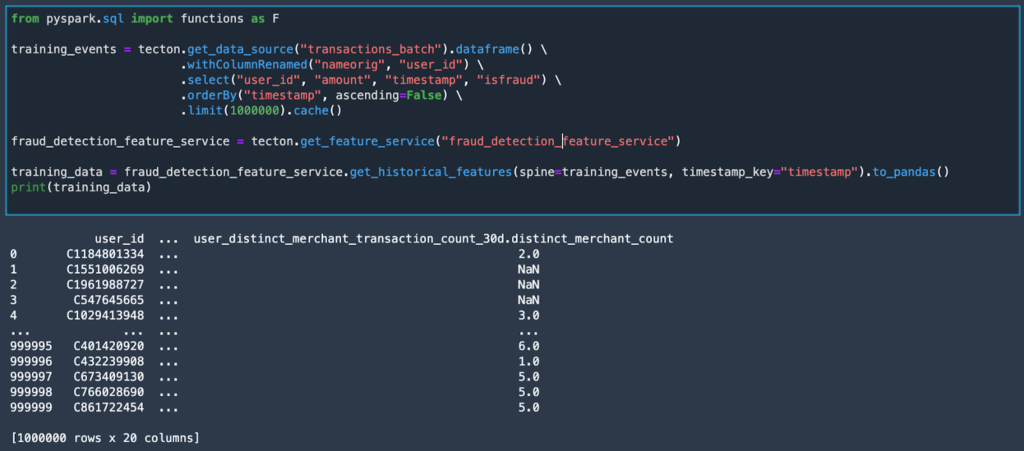
While the processing of the data is done in Spark, the resulting training data set can be cast to either a Spark or Pandas Dataframe. This provides the flexibility to build models with your framework of choice.
Tecton automatically backfills training data up to a date specified by the user. This is a popular feature with data scientists because it allows them to develop new features quickly. Tecton also supports “time travel,” which allows you to generate training data from historical features with point-in-time correctness. These capabilities allow us to instantly generate accurate training data with confidence.
Serving features for online inference
For models in production, Tecton supports serving features for real-time inference use cases through a low-latency REST API. We’ve benchmarked our performance and have reliably run 100,000 requests per second. You can use Tecton and SageMaker to deploy a complete ML application in production running real-time inference. Tecton serves the features, and SageMaker hosts the deployed model.
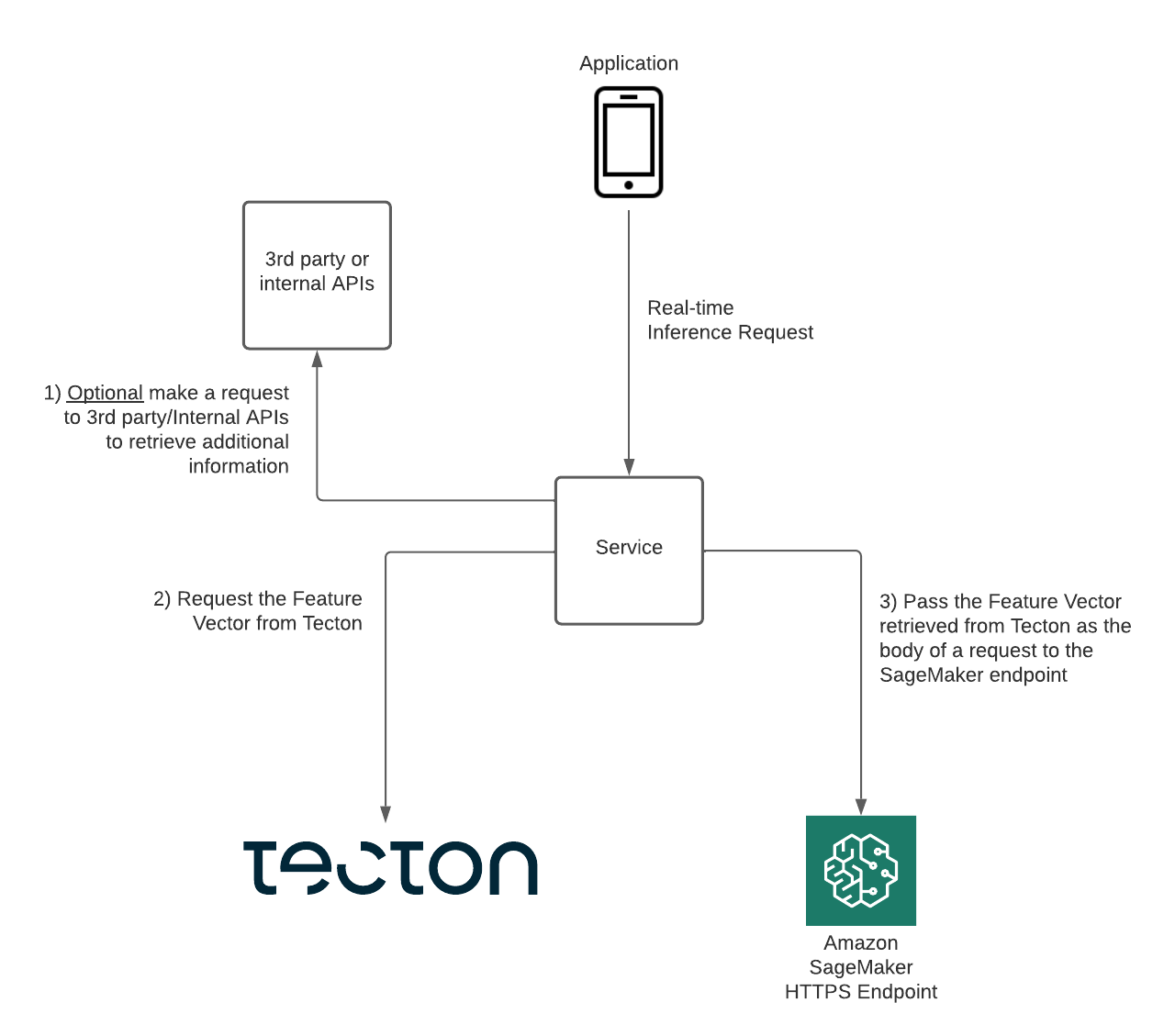
Let’s explore how a simple integration would work, in which you have a service that responds to real-time inference requests from your application by sending information to your model and retrieving the results.
- When a real-time inference request comes from your application, your service might optionally make a request to third-party or internal APIs to retrieve additional information.
- Next, your service would make a GetFeatures request to Tecton to retrieve the Feature Vector containing the relevant features for the model.
- Your service passes the Feature Vector retrieved from Tecton to request inferences from the model deployed at your SageMaker endpoint.
Conclusion
Tecton combines production ML capabilities with the convenience of doing everything from within Amazon SageMaker, whether that’s at the development stage for training models or doing real-time inference in production. Generally, Tecton affords you the flexibility of working with the ML frameworks of your choice.
If you’re interested in what Tecton can do for you, we encourage you to reach out for an in-depth demonstration and sign up for free trial.