
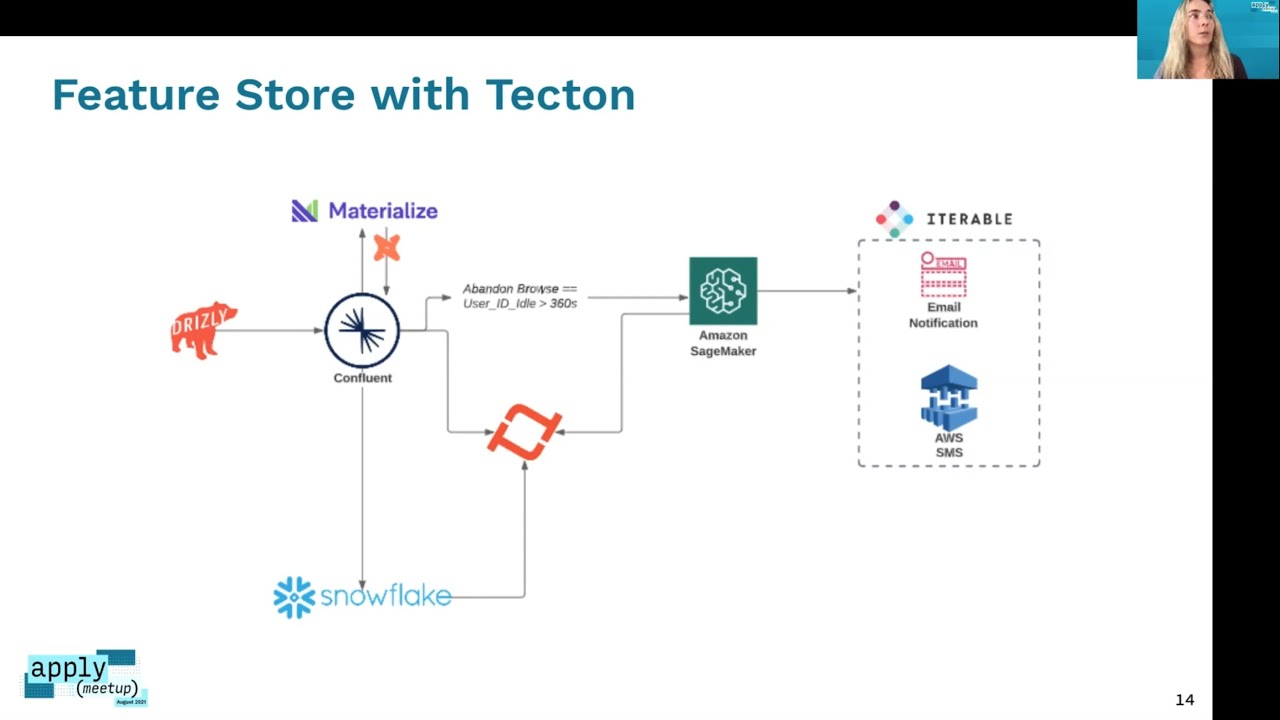
Drizly is building out our Data Science stack and streaming infrastructure to match the success we’ve had with the modern data stack on BI. We are currently standing up our architecture using Kafka, Materialize, and dbt. We are planning on adding …

ML Design Patterns for Data Engineers
As machine learning moves from being a research discipline to a software one, it is useful to catalog tried-and-proven methods to help engineers tackle frequently occurring problems that crop up during the ML process. In this talk, I will cover three …

Real-time Personalization of QuickBooks using Clickstream Data
In this session, we will talk about Intuit’s real-time personalization ML pipeline. We will use a self-help use case to show how Intuit provides proactive self-help to millions of users by personalizing content based on user behavior to increase …

Building a Best-in-Class Customer Experience Platform – The Hux Journey – Deloitte Digital
New technologies have been advancing rapidly across the areas of frictionless data ingestion, customer data management, identity resolution, feature stores, MLOps and customer interaction orchestration. Over the same period many large enterprises …

Exploiting the Data Code: Duality Applying Modern Software Development Practices to Data with Dali
Most large software projects in existence today are the result of the collaborative efforts of hundreds or even thousands of developers. These projects consist of millions of lines of code and leverage a plethora of reusable libraries and services …

Towards a Unified Real-Time ML Data Pipeline, from Training to Serving
On a global marketplace like Etsy where buyers come to buy unique, varied items from sellers from around the globe, the inventory of items is constantly changing. User preferences also change in real time as they discover the latest selection being …

The Only Truly Hard Problem in MLOps
MLOps solutions are often presented as addressing particularly challenging problems. This is mostly untrue. The majority of the problems solved by MLOps solutions have their origins in pre-ML data processing systems and are well addressed by the …

Reusability in Machine Learning
In this session we will explore modern techniques and tooling which empower reusability in data and analytics solutions. Creating and leveraging reusable machine-learning code has many similarities with traditional software engineering but is also …

Best Practices for Productionalizing Data & ML Projects
This talk will briefly explore the development lifecycle for data engineering & ML projects before delving into some of the friction points most common when productionalizing those projects. We’ll provide an overview of how large companies like …

Redis as an Online Feature Store
Feature stores are becoming an important component in any ML/AI architecture today. What is a feature store? – In a nutshell, the feature store allows you to build and manage the features for your training phase (offline feature store) and inference …

A Point in Time: Mutable Data in Online Inference
Most business applications mutate relational data. Online inference is often done on this mutable data, so training data should reflect the state at the prediction’s “point in time” for each object. There are a number of data architecture / domain …

Apache Kafka, Tiered Storage and TensorFlow for Streaming Machine Learning Without a Data Lake
Machine Learning (ML) is separated into model training and model inference. ML frameworks typically use a data lake like HDFS or S3 to process historical data and train analytic models. But it’s possible to completely avoid such a data store, using …