How to Use Snowflake With Tecton


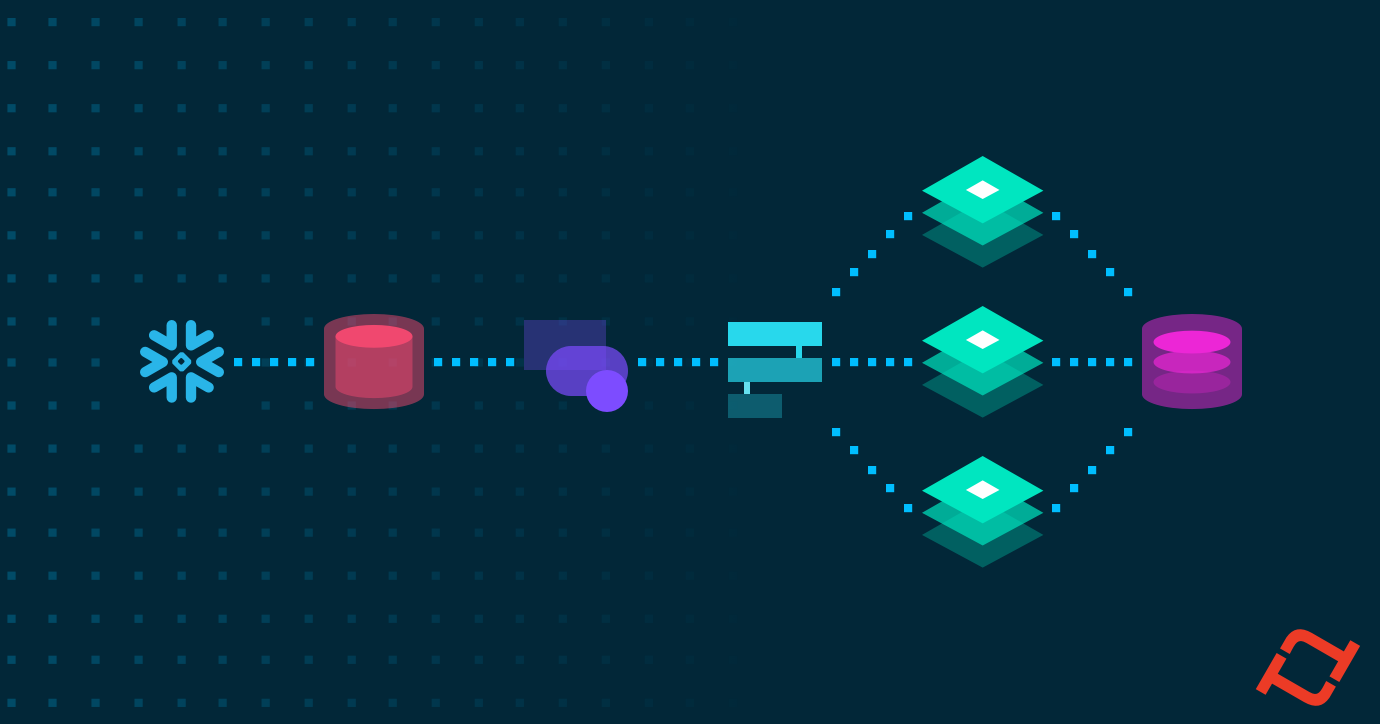
You want to build production machine learning on top of Snowflake. So how do you do that?
If you’re a Snowflake user who wants to put machine learning into production, great news — we recently announced that Tecton is introducing a first-class integration with Snowflake. You can check out the blog post here for an overview of what benefits the integration brings to Snowflake users.
This article is an in-depth tutorial on how to use the two platforms together. We’ve prepared sample code for a demo fraud detection model below, so you can see the integration in action.
Example Use Case: Fraud Detection Model
We’ll walk through how to productionize an example ML use case: a fraud detection model that scores the risk of credit card transactions to identify fraud. The model is fed data in real-time, as transactions are occurring, and makes extremely fast predictions to determine whether each transaction is fraudulent or not. We’ll show you how to build three different types of features using Tecton:
- Simple batch features that will create binary values: (1) whether the user has a credit score higher than 670 and (2) whether they have a credit score higher than 740.
- Batch features with a windowed aggregation to compute the user’s average transaction amount for the last day, 3 days, and 7 days. Another set of batch features will compute the sum of all transactions for the same time windows.
- A real-time or on-demand feature, which determines whether the transaction that’s happening in real-time is higher than the user’s average transaction amount over the last 24 hours.
Productionizing an ML Use Case in 5 Steps
Using our example use case above, we’ll now walk through the five steps to productionizing ML pipelines with Tecton and Snowflake:
- Connect Tecton to a Snowflake data source
- Define your features via Python files that live in a Git repository
- Apply the definitions to Tecton
- Generate accurate training data via the Tecton Python SDK
- Retrieve serving data via a Tecton REST API
1. Connect to a Snowflake Data Source
Let’s start by defining our data sources and features in Python. Later, we’ll show you how to “apply” these definitions to tell Tecton to process and generate features.
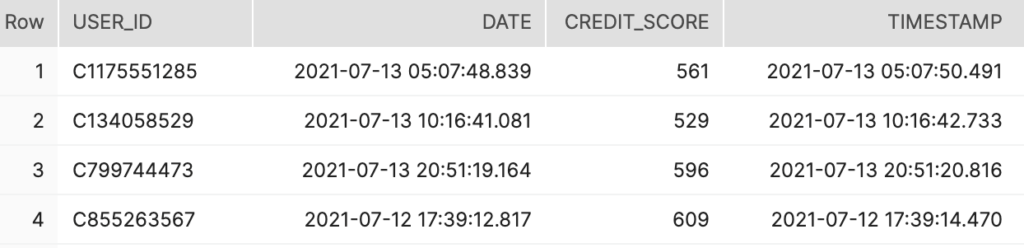
First, we’ll need to define a Data Source to connect Tecton to data in Snowflake. Tecton can connect to a table, view, or query in the Snowflake Data Cloud. Here, we define a table as a data source that contains historical records of user credit scores:
credit_scores = BatchDataSource(
name='credit_scores',
batch_ds_config=SnowflakeDSConfig(
database='FRAUD',
schema='PUBLIC',
table='CREDIT_SCORES',
timestamp_column_name='TIMESTAMP'
)
)This will allow Tecton to connect to the following Snowflake table and data:
Now we’re ready to start building features.
2. Define Features and a Feature Service
2.1 Simple Batch Feature
A Batch Feature View in Tecton defines one or more features from a batch data source. These feature values are calculated on a scheduled basis (hourly, daily, weekly, etc.). The following examples will all be attributes of a user, as specified by USER_ID. Features are calculated at a specific TIMESTAMP, which ensures the feature data corresponds to the state of the world at that time.
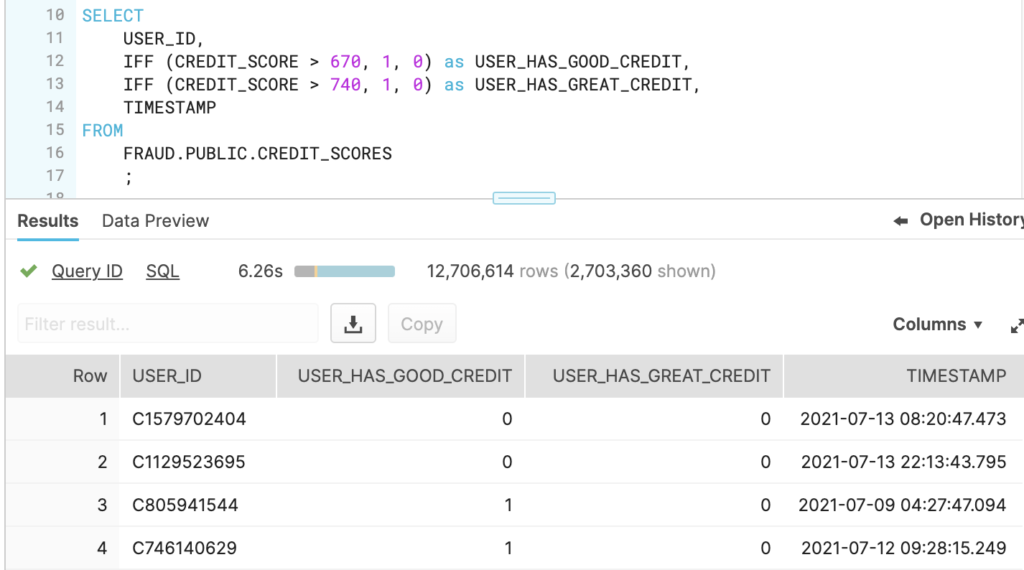
This feature view defines two features: USER_HAS_GOOD_CREDIT and USER_HAS_GREAT_CREDIT. These can be defined in native Snowflake SQL with the IFF function as follows:
To define the features with Tecton, we simply wrap the SQL statement with a Python function and annotate it with a batch_feature_view decorator. The decorator specifies the data source and includes metadata that is used to catalog the features and construct data pipelines. For example, this decorator instructs Tecton to run a batch job every day and to persist the features to the online store (a DynamoDB or Redis database) for serving via Tecton’s serving API. Tecton also takes care of automatically backfilling feature data to the specified feature_start_time.
@batch_feature_view(
sources=[credit_scores],
entities=[user],
mode='snowflake_sql',
online=True,
feature_start_time=datetime(2020, 10, 1),
batch_schedule='1d'
)
def user_credit_quality(credit_scores):
return f'''
SELECT
USER_ID,
IFF (CREDIT_SCORE > 670, 1, 0) AS USER_HAS_GOOD_CREDIT,
IFF (CREDIT_SCORE > 740, 1, 0) AS USER_HAS_GREAT_CREDIT,
TIMESTAMP
FROM
{credit_scores}
'''With just this simple code, Tecton will create and orchestrate all the infrastructure we need to serve the credit score features to our models:

2.2 Batch Feature with a Time-Window Aggregation
A very common type of feature in machine learning is a time-window aggregation. In the next feature view, we compute six features:
- Average transaction amount for last [1d, 3d, 7d]
- Sum of transaction amount for last [1d, 3d, 7d]
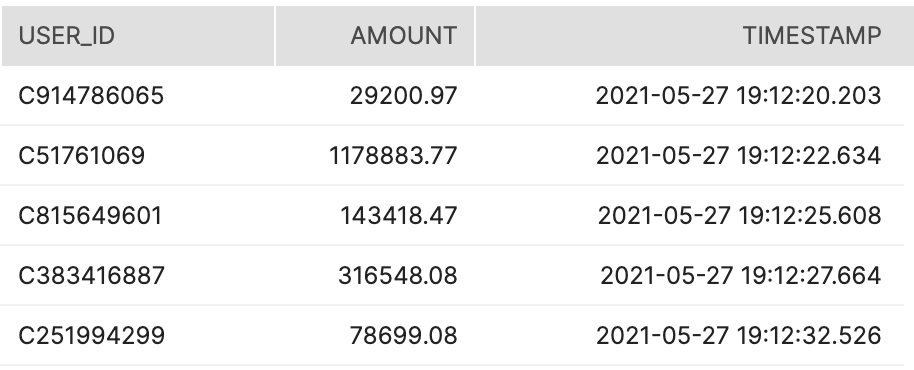
The data source we’ll now use is a table containing all of the transactions for our users. The table includes USER_ID, AMOUNT of transaction, and TIMESTAMP.
Defining correct time-window aggregations for sliding time intervals can be error-prone and inefficient. Tecton’s built-in aggregations framework makes this very easy. All we need to do is define the function and time windows under the FeatureAggregation parameters below.
@batch_feature_view(
sources=[transactions]
entities=[user],
mode='snowflake_sql',
online=True,
feature_start_time=datetime(2020, 10, 1), aggregation_slide_period='1d',
aggregations=[
FeatureAggregation(column='AMOUNT', function='mean', time_windows=['1d', '3d', '7d']),
FeatureAggregation(column='AMOUNT', function='sum', time_windows=['1d', '3d', '7d'])
]
)
def transaction_counts(transactions):
return f'''
SELECT
USER_ID,
AMOUNT,
TIMESTAMP
FROM
{transactions}
'''With just this .py file, Tecton will create the full pipeline to orchestrate the computation of these features:
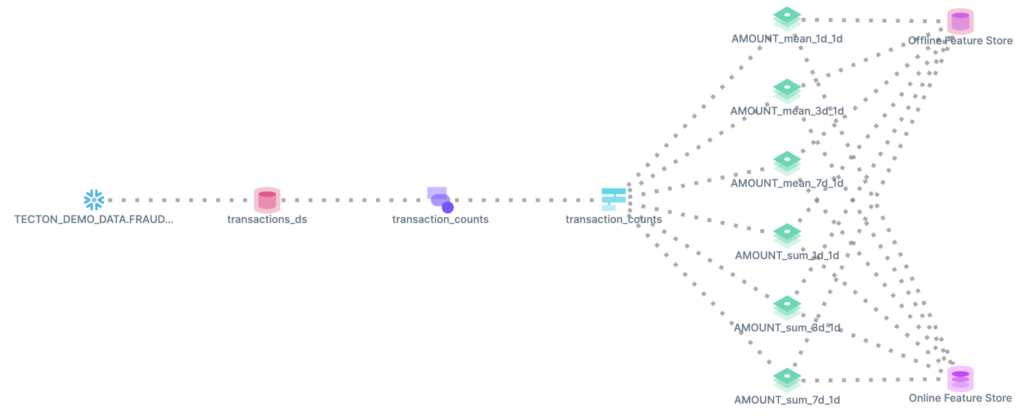
Note all of the complexity abstracted and simplified by Tecton: creating, scheduling, running, and maintaining these jobs is simply a matter of defining the types of aggregates and windows we’re interested in. Additionally, we were able to create 6 features at once. What can be done in minutes with Tecton would typically take weeks to develop and put into production with alternative methods.
2.3 Request-Time (On-Demand) Feature
Tecton has the ability to construct features that run on-demand, using data that can only be known at request time. The data to compute these features comes directly from an application and is not available in the batch data source or the feature store.
In our fraud detection example, we need to determine, in a matter of milliseconds, whether the transaction that is being processed is fraudulent. In order to do so, we need to take information about the transaction, compute a set of features, and return those features to the model in real-time.
For our example, we’ll create a feature that determines whether the amount of the transaction is unusually high for the cardholder. Specifically, we’ll determine whether the transaction amount is higher than the average transaction amount for that user in the last 24 hours. We’ll need to combine historical and real-time information about the user to compute our feature.
On-Demand Features in Tecton are written using Python. In the code below, we define an input schema with the transaction amount and an output schema with the feature we want to build, in this case, transaction_amount_is_higher_than_average.
Our on-demand feature might also need access to pre-computed features that already live in the feature store. We can specify those directly as inputs as well, as we do here with user_transaction_amount_metrics.
The feature transaction_amount_is_higher_than_average is defined as a binary value, and set to 1 if the transaction amount happening in real-time is greater than the amount_mean_24h_10m, the average transaction amount over the last 24 hours (calculated every 10 minutes).
transaction_request = RequestDataSource(request_schema=[Field('amount', FLOAT64)])
@on_demand_feature_view(
sources=[transaction_request, user_transaction_amount_metrics],
mode='python',
output_schema=[Field('transaction_amount_is_higher_than_average', INT64)]
)
def transaction_amount_is_higher_than_average(transaction_request, user_transaction_amount_metrics):
return {'transaction_amount_is_higher_than_average', int(transaction_request['amount'] > user_transaction_amount_metrics['AMOUNT_MEAN_24h_1d'])}The feature logic will be applied in Snowflake as a Python User Defined Function (UDF) within Snowpark for Python. This UDF will be leveraged when creating batch data sets, whether for training or inference. On-Demand Features are executed in real-time during API requests.

2.4 Creating a Feature Service to Serve the Features
In Tecton, a Feature Service groups features together to be used by a model. Each feature service has a 1:1 mapping to a model. Here we’ll define a feature service which includes the features created above, as well as some existing features already available in Tecton to support this use case.
snowflake_service = FeatureService(
name='snowflake_service',
description='A Feature Service providing features for a model that predicts if a transaction is fraudulent.',
features=[
last_transaction_amount_sql,
transaction_amount_is_higher_than_average,
user_credit_quality,
user_transaction_amount_metrics,
transaction_counts
]
)
3. Apply Definitions to Tecton
Now that we’ve defined a set of features and a Feature Service using declarative code, it’s time to apply those definitions into the Tecton environment. Remember that all the definitions above live in .py files in a Git repository. Once we’re ready, we can push these files into the Tecton server by running tecton apply from the Tecton CLI.
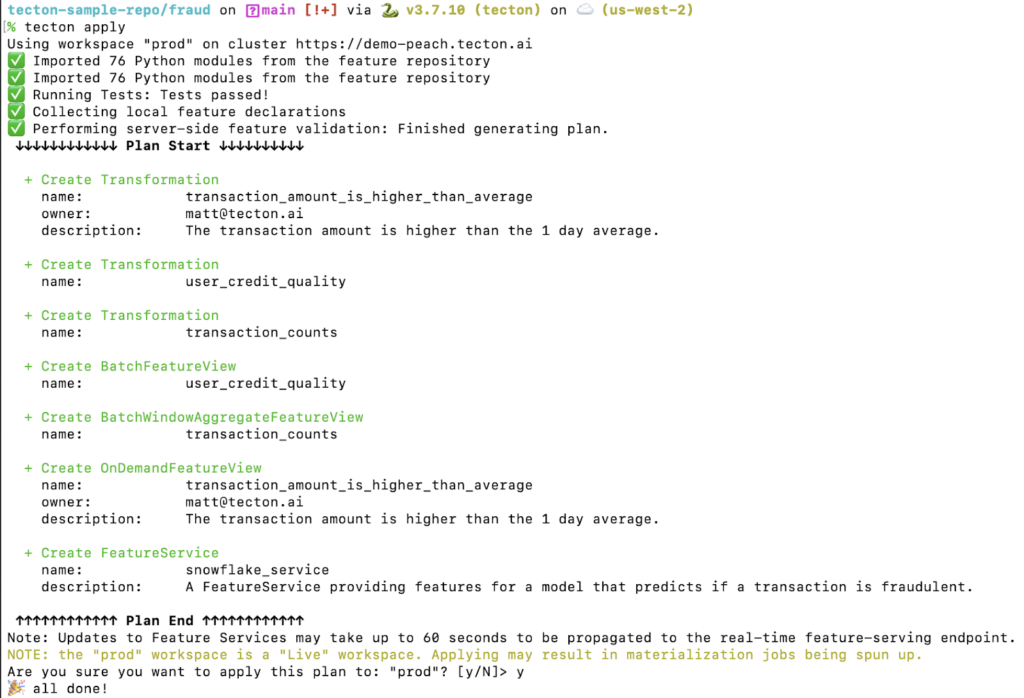
By running tecton apply, Tecton will spin up resources to run data pipelines, populating the features in both the offline and online stores. Tecton’s CLI commands can be automatically run via CI/CD systems for production applications.
Once the features have been applied, they will show up in the Tecton Web UI, where you can share those features with other members of your team.
4. Generate Accurate Training Data
Once our features live in the Tecton environment, we can use the Python SDK to retrieve a training dataframe that contains all of our features.
We’ll first fetch a series of USER_ID and TIMESTAMP values from our Snowflake database. This is the training data set we want to enrich with the appropriate feature values.
df_training_events="SELECT USER_ID, AMOUNT, TIMESTAMP, FRAUD_LABEL FROM TXN_SAMPLE"
SnowflakeContext.get_instance().get_session().sql(df_training_events).toPandas()Running the code returns this table:
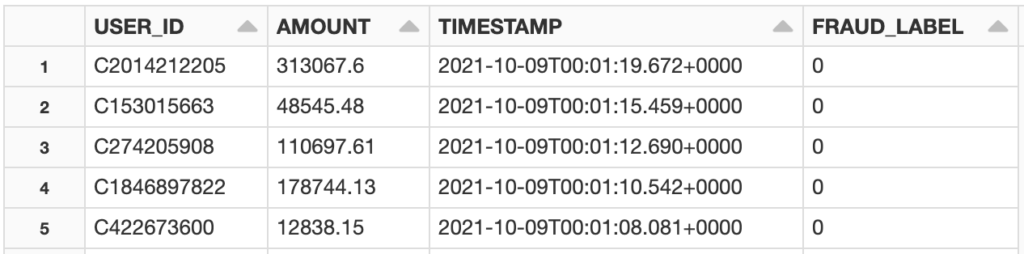
The dataframe above contains information about the users and their transactions, as well as labels that determine whether each transaction was indeed fraudulent. We can call our Feature Service to populate features.
snowflake_service = tecton.get_feature_service("snowflake_service")
df_training_data = snowflake_service.get_historical_features(spine=df_training_events, timestamp_key="TIMESTAMP")
df_training_data.to_pandas().head()We now have an accurate data set that can be used to train our model:

Note that the only thing Tecton needs is a dataframe with IDs, timestamps, and the name of the feature service. Once features have been defined and applied into Tecton, generating an accurate training set is done in two lines of code.
5. Retrieve Serving Data
Real-time model inference requires access to feature data at low-latency. Features can be retrieved in real time via Tecton’s REST API, which has been tested to scale up to 100,000 feature vector requests per second. A sample request is shown below using cURL.
curl -X POST https://YOUR_ACCOUNT.tecton.ai/api/v1/feature-service/get-features\
-H "Authorization: Tecton-key $TECTON_API_KEY" -d\
'{
"params": {
"feature_service_name": "snowflake_service",
"join_key_map": {
"user_id": "C439568470"
},
"request_context_map": {
"amount": 1122.14
}
}
}'
Passing this request to Tecton’s feature server will return the set of features for the model to score the transaction. Tecton will return the request in under 100ms.
{"result":{"features":[12070,0,1,null,4152.34,7310,null,100,230]}}Conclusion
In this tutorial we’ve shown how you can build production-grade ML pipelines in a matter of minutes with Tecton and Snowflake. Tecton continues investing to improve the infrastructure options available to use with our platform, allowing customers the flexibility to choose what works best for their own data needs.
Snowflake provides a powerful processing engine for both SQL and Python, as well as an efficient and scalable solution to store your features for consistent governance and security across data teams . Together with Tecton, Snowflake users can now build production-ready ML data pipelines using simple, declarative Python code.
How To Get Started?
Request a free trial and our team will reach out to provide a sandbox Tecton environment to evaluate the product. This will consist of a fully-featured and managed Tecton instance for you to explore the platform and all of its capabilities. If you don’t already have a Snowflake account, you can start your free trial here.