Integrating Tecton’s Feature Platform With Google Cloud Platform



Tecton and Google Cloud Platform (GCP) just announced the availability of the Tecton feature platform on Google Cloud. Tecton provides a fully managed way to build and orchestrate the complete lifecycle of features, from transformation to online serving, for real-time machine learning (ML). With this new partnership, GCP users can now bring their ML use cases into production by seamlessly integrating a number of Google Cloud services with Tecton’s feature platform.
In this article, I’ll go into more detail about these integrations and how they can be utilized with Tecton to build a complete enterprise-grade feature platform.
Connecting data sources with Tecton: BigQuery, Google Cloud Storage & Pub/Sub
A good feature platform will allow you to build features from a variety of different data sources and standardize access to them so that you are not constantly rewriting ETL jobs to pull from them.
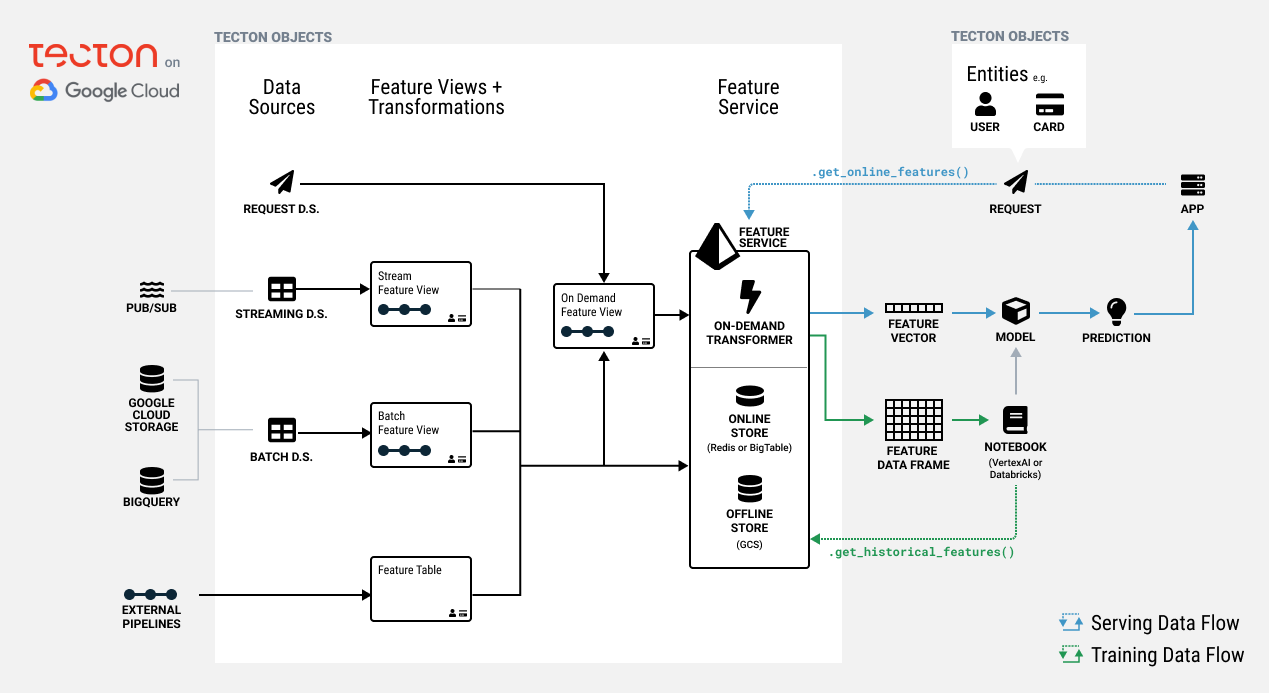
Tecton automates the connection to and maintenance of fresh data from a variety of Google Cloud batch and streaming data services, including BigQuery, Google Cloud Storage (GCS), and Pub/Sub. Non-GCP data sources, such as Redshift, Snowflake, and Apache Kafka, can be used with Tecton as well. For a full list of compatible data sources, see our docs, “Connecting to Data Sources.”
Automatic orchestration with Dataproc or Databricks
Once the proper data sources have been defined in Tecton, Tecton will need a distributed compute platform to perform the aggregations and transformations necessary to translate incoming data into features, which will then be placed in offline and online stores.
For Tecton on GCP, this will either be Databricks or Dataproc. Both options use Spark to distribute the materialization of features across multiple jobs and compute resources in a fast, scalable, and cost-effective manner. Tecton automates the creation and orchestration of these jobs, defining and running the physical data pipelines required to materialize and serve features. Tecton also monitors these pipelines for successful completion, feature data quality, and operational service levels. After data is materialized, it is curated in an offline store for training dataset generation and in an online store to serve features to machine learning models in real time, at high scale, and with enterprise-grade service levels.
Building training datasets from GCS
Offline and online stores provide specialized storage for features so they can be used effectively and efficiently for model training and at serving time. When running on Google Cloud, Tecton will materialize features to the offline store as files in GCS. Based on the feature definitions provided, Tecton will automatically perform the joins and aggregations necessary to transform data from various sources into features that can be used to build training datasets used to fine-tune ML models.
Real-time feature retrieval on Redis & Bigtable
Tecton also stores the freshest data in an online store so ML models can retrieve features in real-time production environments. Tecton is designed to meet enterprise scale and security requirements, allowing retrieval of hundreds of thousands of queries per second at median latencies of ~5ms. Redis and Bigtable can be used as an online store on GCP; Tecton automates the process of keeping the offline and online store consistent with each other.
Notebook-driven development with Vertex AI Workbench JupyterLab
Development and testing of Tecton features takes place in Python notebooks (more on Tecton’s Development Workflow can be found here)—and with Google Cloud’s Vertex AI Workbench, you can easily launch a JupyterLab notebook instance running a Dataproc kernel to work with Tecton. Tecton allows you to define features as code and manage feature definitions in a central Git-backed repository. Batch, streaming, or on-demand feature views can be created with standardized functions for complex but common ML data aggregations such as last_n.
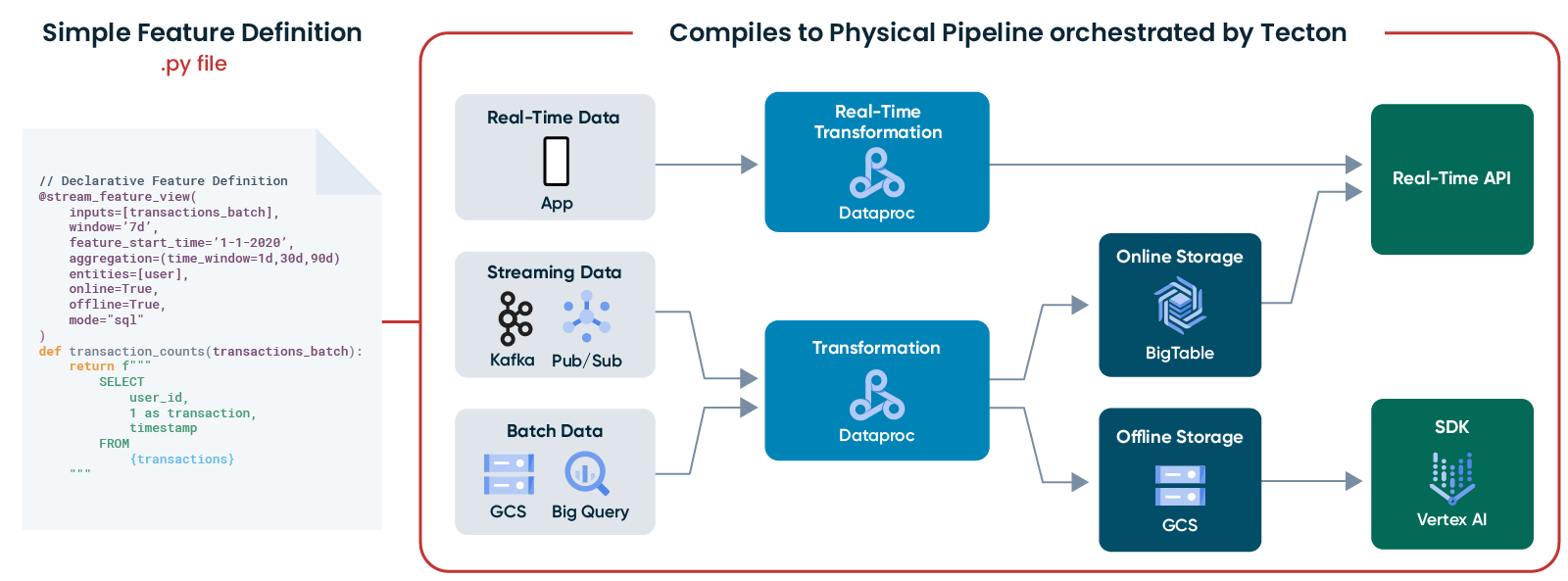
We have provided an example notebook and instructions on how to create features with Tecton on GCP here. Once your initial set of features have been developed and tested, you can iterate on them in a production environment with CI/CD tools.
Google Cloud Build for features-as-code
A CI/CD tool like Google Cloud Build allows you to manage your Tecton features-as-code, centrally managing code for easy sharing and collaboration, just as you would manage infrastructure-as-code or models-as-code. Tecton recommends applying features into production through a CI/CD tool like Build to provide production best practices, including unit testing, version control, validation, alerting, and monitoring. Many other CI/CD tools can be used with Tecton, such as GitHub Actions—for an example, please see our docs on “Connecting CI/CD.”
Putting it all together
Google Cloud provides both advanced data infrastructure and industry-leading services for building and running ML-powered applications. Tecton is the interface between your data and your ML applications. It is the central hub to build, process, share, and serve ML features across your applications on top of Google Cloud.
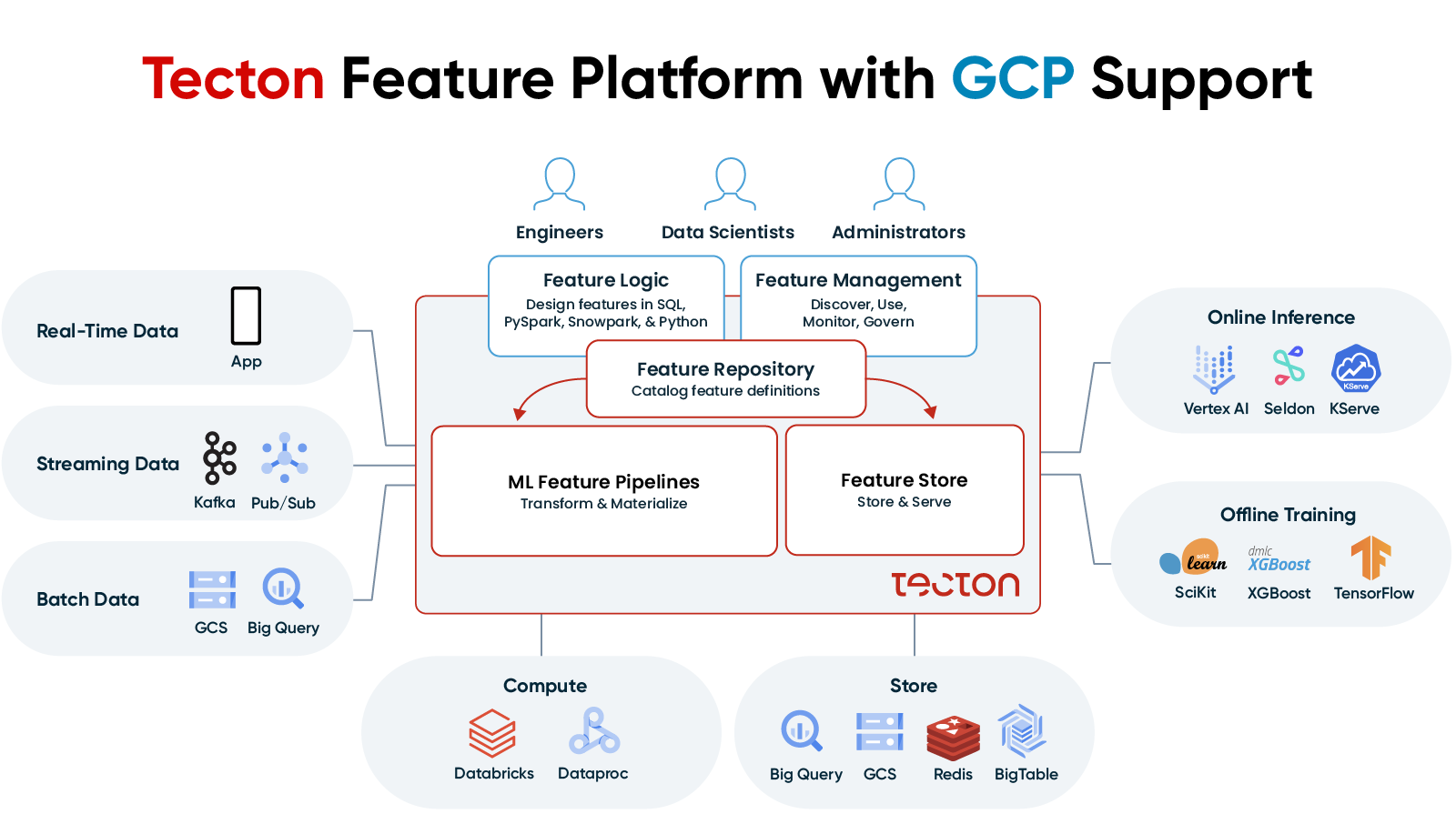
Tecton is more than just a feature store—it’s an end-to-end feature platform that automates every step involved in building production-grade ML features and orchestrating all the GCP services needed to do so.
Multiple Google Cloud data sources can be utilized by Tecton, and once the connections are established they can be reused for different use cases and by different teams. Tecton then automatically creates and orchestrates Spark jobs with Databricks or Dataproc to transform and materialize features into offline (GCS) and online (Redis, Bigtable) stores hosted on Google Cloud for offline training and online inference. These features can be defined in JupyterLab notebook on Vertex AI Workbench and deployed with Google Cloud Build.
Using Tecton to orchestrate the lifecycle of ML features can help your organization to deploy new ML applications faster, increase model accuracy, improve collaboration between teams, and optimize your costs. You can request a free Tecton trial with Google Cloud here.