Managing the Flywheel of Machine Learning Data


Today, many companies have machine learning product teams, and some even have machine learning platform teams that work to build reusable components across their machine learning (ML) stack. However, despite teams’ best efforts and hundreds of MLOps tools that exist on the market, it’s still hard to do operational ML successfully.
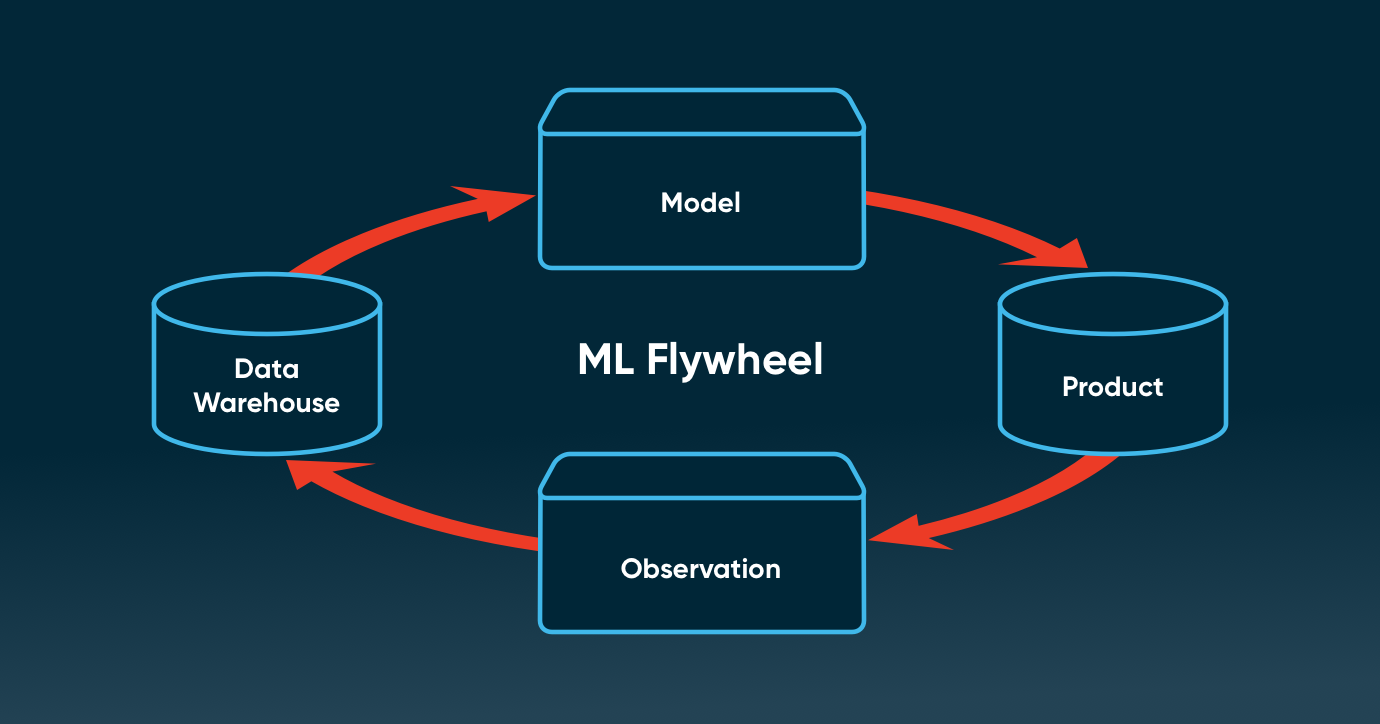
We all want to achieve the flywheel effect with ML: where we can quickly iterate on models and create a compounding effect that results in high performance and reliability. In this post, I’ll explain what the machine learning flywheel is and what the challenges are today—particularly around ML data, which is the lifeblood of any ML application.
This article is based on a talk I gave at apply(conf) 2022—you can view the recording here.
What is the machine learning flywheel?
The purpose of machine learning is to make a decision in the product. From the point of view of the product team that uses the model, you can think of the model as providing a decision API, such as `get_recommendation`, `get_price`, or `get_fraud_score`.

Powering this API and ensuring our decision-making is reliable, repeatable, and accurate, requires a feedback loop.
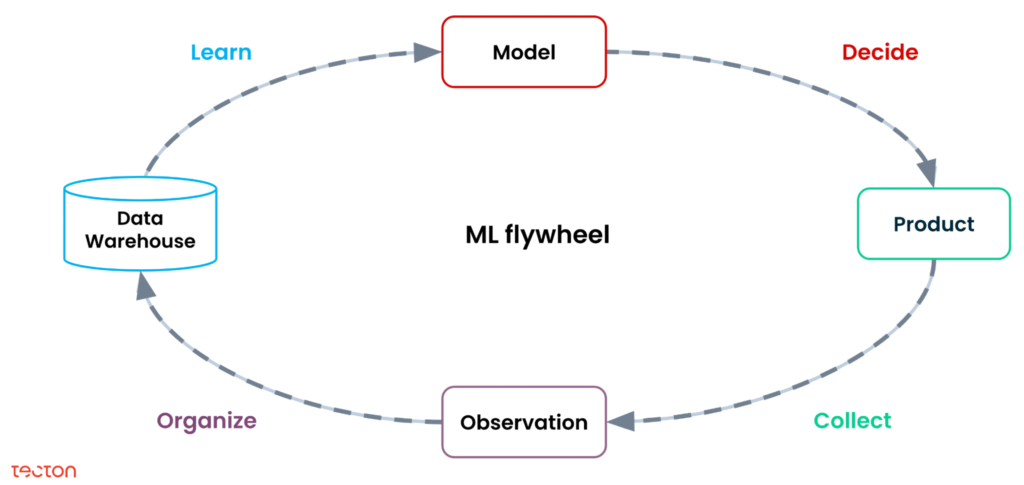
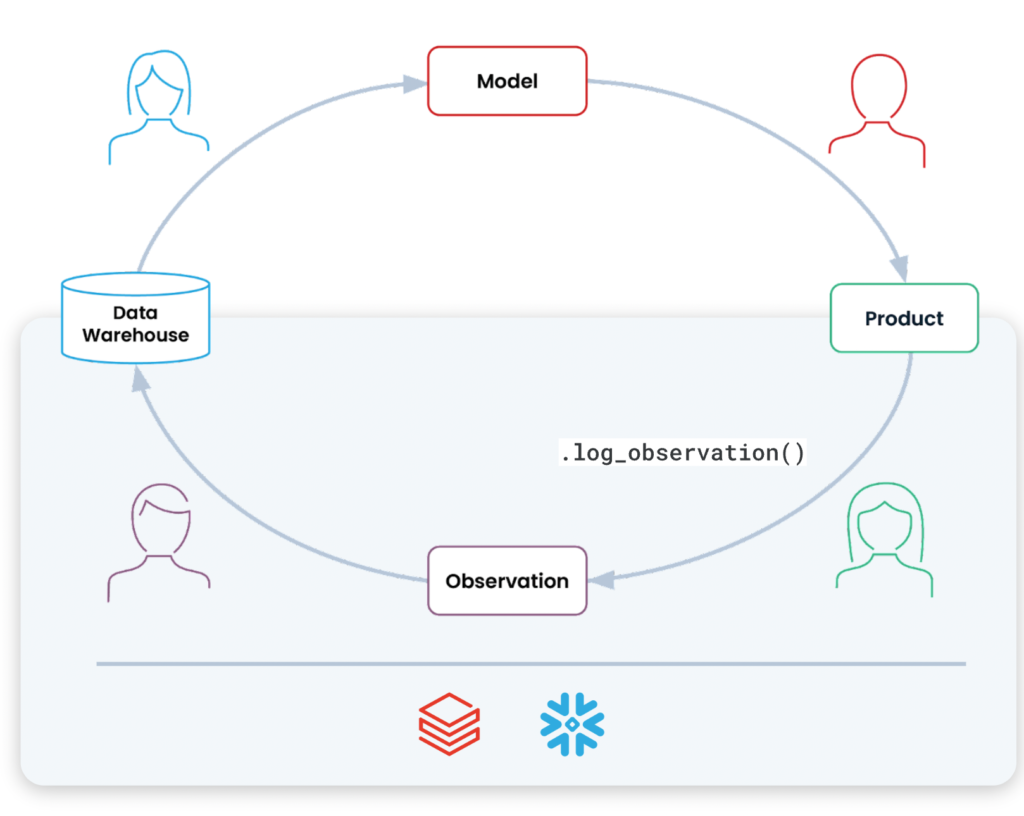
Let’s break down the four stages of this cycle:
- Decide. When decisions are needed, the latest data and models are used to generate an accurate prediction.
- Collect. To ensure that models can be improved over time, we need to log what happened as a result of the model’s predictions. For instance, did the customer click on the item that was recommended?
- Organize. Since these logs might exist in different formats across different parts of the system, they need to be collated and turned into modeled data sets (e.g., the fact and dimension tables in your warehouse).
- Learn. Data scientists take the organized observations, extract new features, assemble a training data set, and build or update the model.
This cycle mirrors what we do as humans every day: We make decisions in the real world, observe the results, combine that with everything we know, and update our understanding. Fundamentally, all ML applications—from product recommendations, to fraud detection, to real-time pricing—rely on this feedback loop.
This is the ML flywheel.
Great machine learning apps require a great machine learning flywheel
Teams that are very successful with machine learning are very intentional about this machine learning flywheel. They build tools to design and manage the entire loop, end-to-end. On the other hand, teams that are not as successful with ML tend to struggle with the flywheel. Without realizing it, they may ignore the bottom half of the flywheel (the Collect and Organize stages). Or they may be oversimplifying the flywheel and choosing a one-size-fits-all approach that doesn’t work for their use case.
When teams have their ML flywheel working, ML feels natural and easy because:
- There’s clear ownership and agency across the entire ML lifecycle.
- The whole ML application becomes much more debuggable and reliable.
- Because you know who owns each part of the flywheel, it becomes much easier to make decisions and implement changes.
- With faster iterations, your models get better and more accurate much quicker.
When the ML flywheel isn’t working, things move slower and break more often because:
- There aren’t clear owners for each stage.
- The impact of changes is harder to understand.
- Unclear dependencies mean more breakages and less reliability.
- Small changes become big tasks. For example, adding a new feature to a model might mean logging new data. This is simple in theory, but if it requires a lot of coordination and owners aren’t clearly defined, it’s easy for this work to stall or never happen.
Why is building a great machine learning flywheel so difficult?
The biggest hurdle for building an ML flywheel today is the large, diverse number of tools on the market. These tools all use a different stack and getting them to work together to support a reliable, repeatable ML application is a major challenge. Compared to a mature field where every company might be using the same set of 5 or 10 interoperable tools, MLOps is still very much a Wild West.

Source: https://mattturck.com/data2021/
What’s needed is an easy way for all stakeholders to build and orchestrate ML and data tools into coherent ML flywheels.
This means simple abstractions to define an ML flywheel and manage its infrastructure and artifacts. The flywheel should also fit in naturally with best-practice engineering and data science workflows.
Data flows are at the core of the ML flywheel
Let’s look at the central dimension of an ML flywheel: data. From making predictions based on live and historical data, to logging metrics and organizing them into training data, many data sets have to be managed throughout the flywheel.
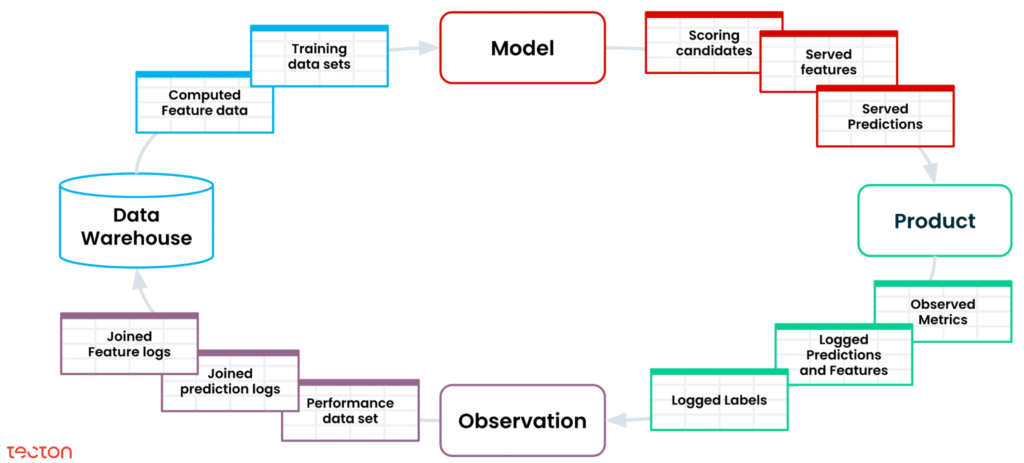
Managing this data is incredibly hard. Fortunately, by managing the data flows that happen at the Learn and Decide stage, feature platforms have had a big impact on part of the flywheel.
Here’s how Tecton does it: In a simple Python file, you can declaratively provide a feature definition, metadata, and feature transformation logic. Then, Tecton compiles this file into a physical pipeline, spinning up production-ready infrastructure to process and store the feature. It orchestrates the data flows on that infrastructure and backfills your features into your offline feature store for access at training time. And it loads up the most recent features into the online feature store, so it can serve your model at scale in real time.
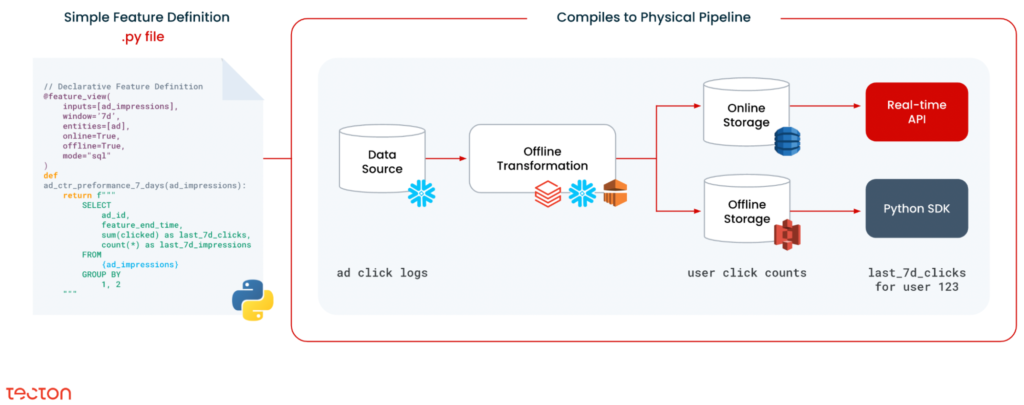
By managing the infrastructure and artifacts end-to-end, a feature platform can have a really big impact on the top path of the loop. But what about the Collect and Organize stages of the cycle?
Extending data management to the entire ML flywheel
Feature platforms solve for part of the ML flywheel, but the lower half—collecting and organizing data for ML—is often left out. How do we bring those same data management patterns to the whole ML flywheel? It boils down to three main recommendations.
1. Close the loop
The first recommendation is simple: close the loop. This doesn’t mean that ML teams have to be directly responsible for collecting and organizing data; instead, they should know who the owners are. Can you identify who is responsible for logging what happens in the product and delivering that data into your data warehouse?
Longer term, the ideal state is having a `log_observation` API that makes it easy to capture and observe new events that could power a feature for ML. The entire loop should be implemented on top of your existing cloud data warehouse or lakehouse. In other words, you don’t want to spin up a new data stack; your ML data should be merged with the rest of your business so teams can quickly access your freshest, most accurate data for building models.
2. Establish a unified flywheel data model
In addition to easily logging events, it’s important to have a unified data model throughout the entire ML flywheel. This ensures that data from different parts of the system is coherent, compatible, and fresh.
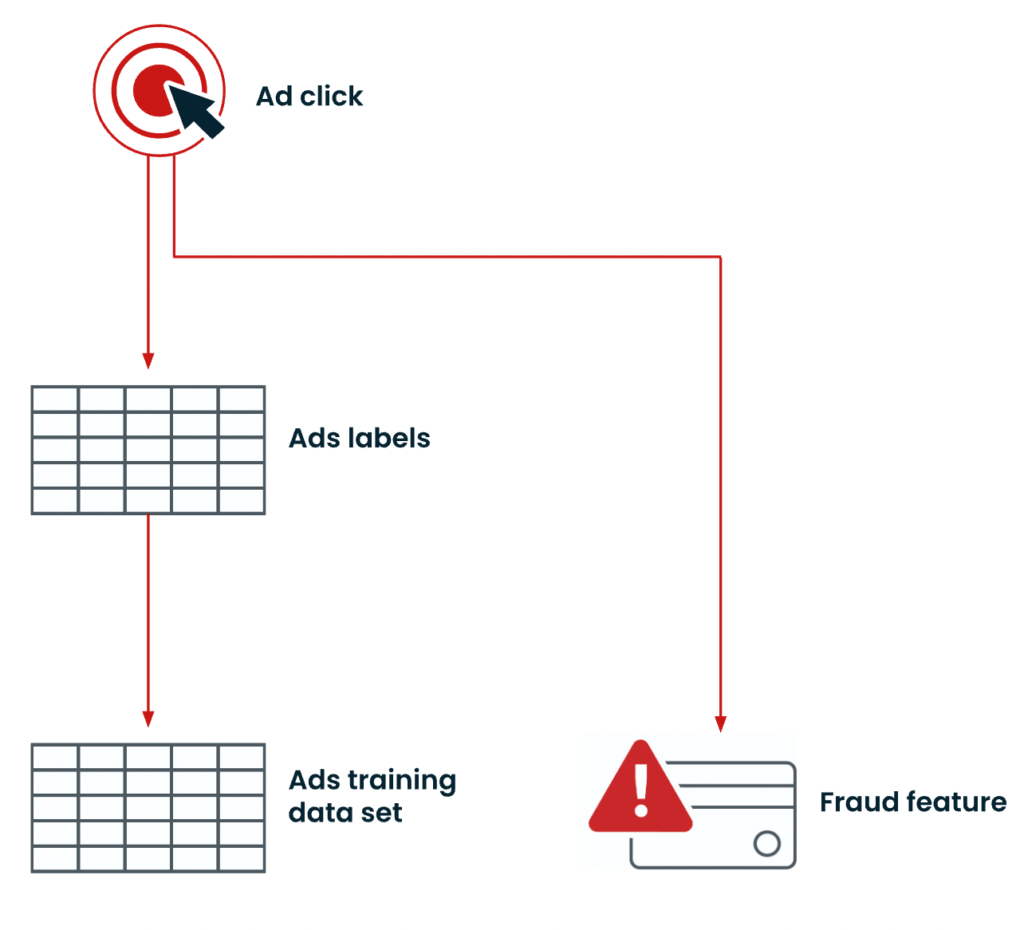
Imagine that a user clicks on an ad that your model recommended. It’s important for that event to quickly update all of the relevant data sets within the flywheel. For example, the click event should update the ads feature labels, which should then update the ads training data set. We might also want that ad click to update a fraud feature. To achieve all this, we need to make sure that the data schemas are consistent across every element of the infrastructure throughout the flywheel.
3. Support use-case-specific architectures
Finally, the ML flywheel isn’t one-size-fits-all. It needs to support the right architecture for the use case. If you’re building a batch lead-scoring model, your needs will be very different compared to building a real-time recommendation system.
For real-time recommendations or ranking, for instance, it’s not as simple as a model service that takes in some features and makes a prediction. There are a number of steps that the machine learning application performs online. It takes in a query, generates candidates, filters those candidates, generates features of each candidate, scores the candidates, and finally determines a ranking.
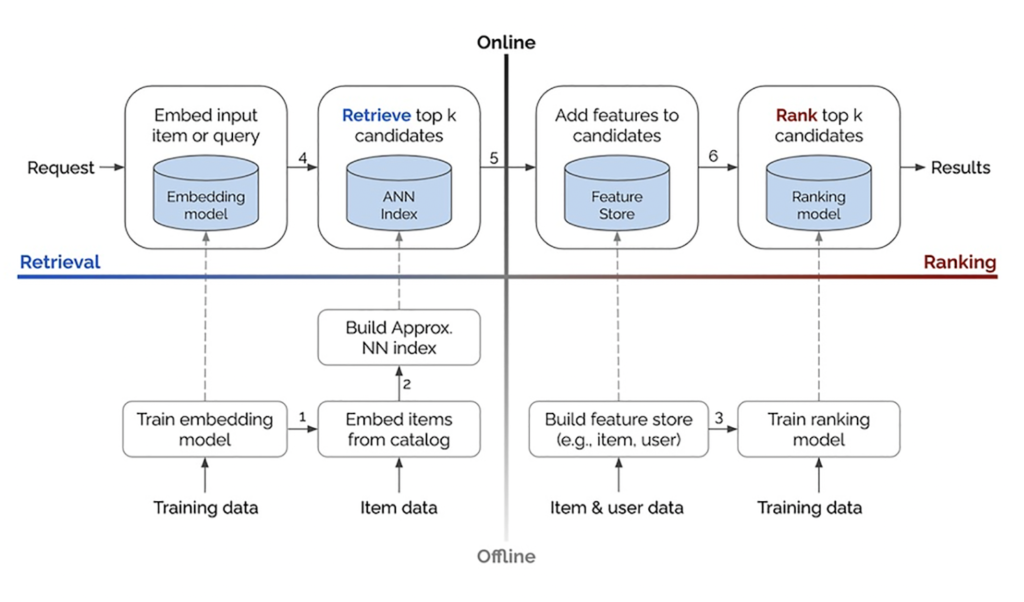
This is just one example of how a particular use case would need additional infrastructure. Every ML team should be thinking about how they will implement their specific flywheel architecture—whether it’s for fraud detection, gaming, security, enterprise SaaS, ranking, or any number of ML use cases. Otherwise, you risk either having the wrong infrastructure (which will be inefficient and expensive) or excluding important pieces from your flywheel.
What you can achieve with a unified ML flywheel
The ML flywheel brings you closer to that ideal state of being a reliable, repeatable, and accurate decision API for the product—which is what we all want to get to eventually. With a unified flywheel, ML platform teams can support ML product teams using fewer resources. ML product teams can iterate, build, and deploy faster, with less glue code, making for fewer mistakes. There’s a lot less maintenance overall, so systems become more reliable without straining resources.
At Tecton, we’re focused on helping teams manage the end-to-end data lifecycle for ML applications. This means simple, declarative definitions become managed infrastructure and managed data sets throughout the flywheel. We also provide use-case-optimized architectures. All of this is implemented on your data stack so that it fits seamlessly into your DevOps and data science workflows.
As you’re thinking about the flywheel and how it maps to your world, we’re always around to help out. You can learn more about Tecton by requesting a free trial or dropping us a note in our community Slack!