What Is a Feature Store?


Updated: May 1, 2023
About the authors:
Mike Del Balso, CEO & Co-Founder of Tecton
Willem Pienaar, Creator of Feast
Data teams are starting to realize that operational machine learning requires solving data problems that extend far beyond the creation of data pipelines.
In a previous post, Why We Need DevOps for ML Data, we highlighted some of the key data challenges that teams face when productionizing ML systems.
- Accessing the right raw data
- Building features from raw data
- Combining features into training data
- Calculating and serving features in production
- Monitoring features in production
Production data systems, whether for large-scale analytics or real-time streaming, aren’t new. However, operational machine learning — ML-driven intelligence built into customer-facing applications — is new for most teams. The challenge of deploying machine learning to production for operational purposes (e.g., recommender systems, fraud detection, personalization, etc.) introduces new requirements for our data tools.
A new kind of ML-specific data infrastructure is emerging to make that possible.
Increasingly Data Science and Data Engineering teams are turning towards feature stores to manage the data sets and data pipelines needed to productionize their ML applications. This post describes the key components of a modern feature store and how the sum of these parts act as a force multiplier on organizations by reducing duplication of data engineering efforts, speeding up the machine learning lifecycle, and unlocking a new kind of collaboration across data science teams.
| Quick refresher: in ML, a feature is data used as an input signal to a predictive model. |
| For example, if a credit card company is trying to predict whether a transaction is fraudulent, a useful feature might be whether the transaction is happening in a foreign country, or how the size of this transaction compares to the customer’s typical transaction. When we refer to a feature, we’re usually referring to the concept of that signal (e.g. “transaction_in_foreign_country”), not a specific value of the feature (e.g. not “transaction #1364 was in a foreign country”). |
 |
What Is the Primary Purpose of a Feature Store
“The interface between models and data”
We first introduced feature stores in our blog post describing Uber’s Michelangelo platform. Feature stores have since emerged as a necessary component of the operational machine learning stack.
Feature store benefits include:
- Productionize new features without extensive engineering support
- Automate feature computation, backfills, and logging
- Share and reuse feature pipelines across teams
- Track feature versions, lineage, and metadata
- Achieve consistency between training and serving data
- Monitor the health of feature pipelines in production
Feature stores aim to solve the full set of data management problems encountered when building and operating operational ML applications.
A feature store is an ML-specific data system that:
- Runs data pipelines that transform raw data into feature values
- Stores and manages the feature data itself, and
- Serves feature data consistently for training and inference purposes

To support simple feature management, feature stores provide data abstractions that make it easy to build, deploy, and reason about feature pipelines across environments. For example, they make it easy to define a feature transformation once, then calculate and serve its values consistently across both the development environment (for training on historical values) and the production environment (for inference with fresh feature values).
Feature stores act as a central hub for feature data and metadata across an ML project’s lifecycle. Data in a feature store is used for:
- Feature exploration and engineering
- Model iteration, training, and debugging
- Feature discovery and sharing
- Production serving to a model for inference
- Operational health monitoring
Feature stores bring economies of scale to ML organizations by enabling collaboration. When a feature is registered in a feature store, it becomes available for immediate reuse by other models across the organization. This reduces duplication of data engineering efforts and allows new ML projects to bootstrap with a library of curated production-ready features.

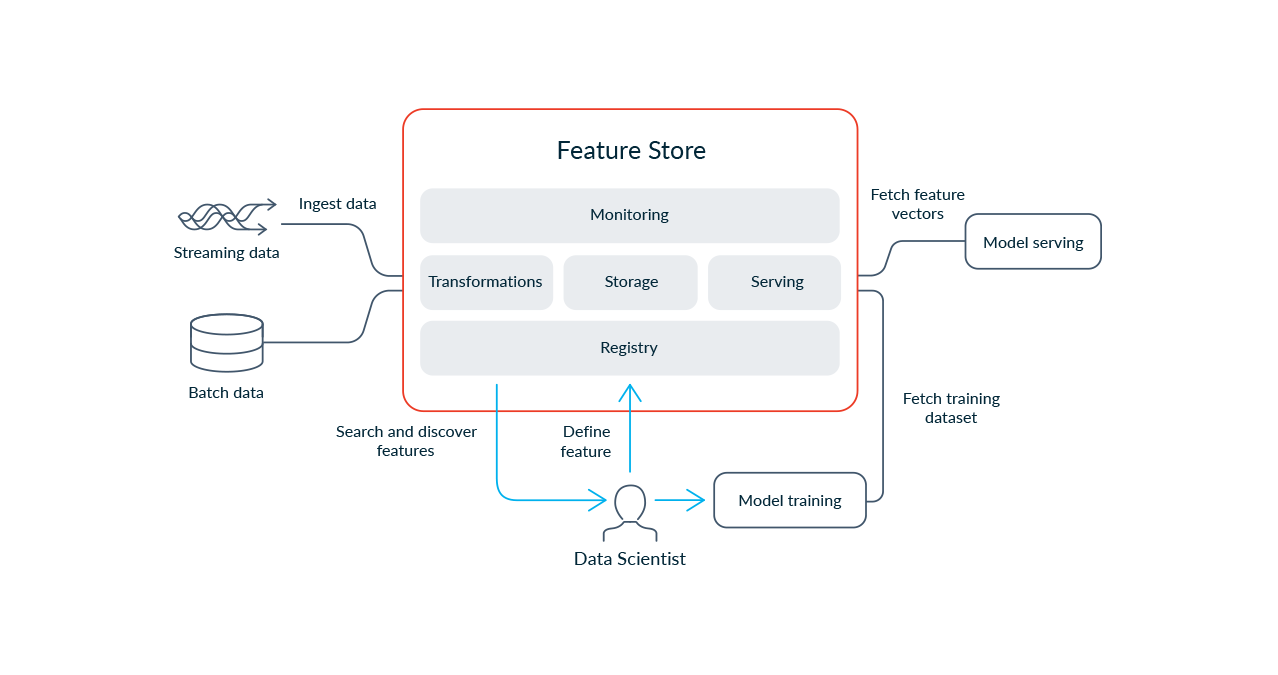
Effective feature stores are designed to be modular systems that can be adapted to the environment in which they’re deployed. There are five primary components that typically make up a feature store. In the rest of this post, we will walk through those components and describe their role in powering operational ML applications.
What Are the Components of a Feature Store
There are 5 main components of a modern feature store: Transformation, Storage, Serving, Monitoring, and Feature Registry.

In the following sections we’ll give an overview of the purpose and typical capabilities of each of these sections.
Serving Feature Data
Feature stores serve feature data to models. Those models require a consistent view of features across training and serving. The definitions of features used to train a model must exactly match the features provided in online serving. When they don’t match, training-serving skew is introduced, which can cause catastrophic and hard-to-debug model performance problems.

Feature stores abstract away the logic and processing used to generate a feature, providing users an easy and canonical way to access all features in a company consistently across all environments in which they’re needed.
When retrieving data offline (e.g., for training), feature values are commonly accessed through notebook-friendly feature store SDKs. They provide point-in-time correct views of the state of the world for each example used to train a model (a.k.a. “time-travel”).
For online serving, a feature store delivers a single vector of features at a time made up of the freshest feature values. Responses are served through a high-performance API backed by a low-latency database.

Data Storage for Machine Learning
Feature stores persist feature data to support retrieval through feature serving layers. They typically contain both an online and offline storage layer to support the requirements of different feature serving systems.

Offline storage layers are typically used to store months’ or years’ worth of feature data for training purposes. Offline feature store data is often stored in data warehouses or data lakes like S3, BigQuery, Snowflake, Redshift. Extending an existing data lake or data warehouse for offline feature storage is typically preferred to prevent data silos.
Online storage layers are used to persist feature values for low-latency lookup during inference. They typically only store the latest feature values for each entity, essentially modeling the current state of the world. Online stores are usually eventually consistent, and do not have strict consistency requirements for most ML use cases. They are usually implemented with key-value stores like DynamoDB, Redis, or Cassandra.

Feature stores use an entity-based data model where each feature value is associated with an entity (e.g., a user) and a timestamp. An entity-based data model provides minimal structure to support standardized feature management, fits naturally with common feature engineering workflows, and allows for simple retrieval queries in production.
Data Transformation in Machine Learning

Operational ML applications require regular processing of new data into feature values so models can make predictions using an up-to-date view of the world. Feature stores both manage and orchestrate data transformations that produce these values, as well as ingest values produced by external systems. Transformations managed by feature stores are configured by definitions in a common feature registry (described below).
| Most teams getting started with feature stores already have existing data pipelines producing feature values. This makes it very important for feature stores to be gradually adoptable and have first class integrations with existing data platforms, allowing teams to immediately operationalize existing ETL pipelines for their ML use cases. |
Feature stores commonly interact with three main types of data transformations:
| Feature Type | Definition | Common input data source | Example |
| Batch Transform | Transformations that are applied only to data at rest | Data warehouse, data lake, database | User country, product category |
| Streaming Transform | Transformations that are applied to streaming sources | Kafka, Kinesis, PubSub | # of clicks per vertical per user in last 30 minutes, # of views per listing in past hour |
| On-Demand Transform | Transformations that are used to produce features based on data that is only available at the time of the prediction. These features cannot be pre-computed. | User-facing application | Is the user currently in a supported location? Similarity score between listing and search query |
A key benefit is to make it easy to use different types of features together in the same models.

Models need access to fresh feature values for inference. Feature stores accomplish this by regularly recomputing features on an ongoing basis. Transformation jobs are orchestrated to ensure new data is processed and turned into fresh new feature values. These jobs are executed on data processing engines (e.g., Spark or Pandas) to which the feature store is connected.
Model development introduces different transformation requirements. When iterating on a model, new features are often engineered to be used in training datasets that correspond to historical events (e.g., all purchases in the past 6 months). To support these use cases, feature stores make it easy to run “backfill jobs” that generate and persist historical values of a feature for training. Some feature stores automatically backfill newly registered features for preconfigured time ranges for registered training datasets.
Transformation code is reused across environments preventing training-serving skew and frees teams from having to rewrite code from one environment to the next.
| Feature stores manage all feature-related resources (compute, storage, serving) holistically across the feature lifecycle. Automating repetitive engineering tasks needed to productionize a feature, they enable a simple and fast path-to-production. Management optimizations (e.g. retiring features that aren’t being used by any models, or deduplicating feature transformations across models) can bring significant efficiencies, especially as teams grow increasingly the complexity of managing features manually. |
Machine Learning Monitoring
When something goes wrong in an ML system, it’s usually a data problem. Feature stores are uniquely positioned to detect and surface such issues. They can calculate metrics on the features they store and serve that describe correctness and quality. Feature stores monitor these metrics to provide a signal of the overall health of an ML application.

Feature data can be validated based on user defined schemas or other structural criteria. Data quality is tracked by monitoring for drift and training-serving skew. E.g. feature data served to models are compared to data on which the model was trained to detect inconsistencies that could degrade model performance.
When running production systems, it’s also important to monitor operational metrics. Feature stores track operational metrics relating to core functionality—for example, metrics relating to feature storage (availability, capacity, utilization, staleness) or feature serving (throughput, latency, error rates). Other metrics describe the operations of important adjacent system components, such as operational metrics for external data processing engines (e.g., job success rate, throughput, processing lag and rate).
Feature stores make these metrics available to existing monitoring infrastructure. This allows ML application health to be monitored and managed with existing observability tools in the production stack.
Having visibility into which features are used by which models, feature stores can automatically aggregate alerts and health metrics into views relevant to specific users, models, or consumers.
| It’s not essential that all feature stores implement such monitoring internally, but they should at least provide the interfaces into which data quality monitoring systems can plug. Different ML use cases can have different, specialized monitoring needs so pluggability here is important. |
Machine Learning Model Registry
A critical component in all feature stores is a centralized registry of standardized feature definitions and metadata. The registry acts as a single source of truth for information about a feature in an organization.
The registry is a central interface for user interactions with the feature store. Teams use the registry as a common catalog to explore, develop, collaborate on, and publish new definitions within and across teams.
The definitions in the registry configure feature store system behavior. Automated jobs use the registry to schedule and configure data ingestion, transformation, and storage. It forms the basis of what data is stored in the feature store and how it is organized. Serving APIs use the registry for a consistent understanding of which feature values should be available, who should be able to access them, and how they should be served.
The registry allows for important metadata to be attached to feature definitions. This provides a route for tracking ownership, project or domain specific information, and a path to easily integrate with adjacent systems. This includes information about dependencies and versions which is used for lineage tracking.
To help with common debugging, compliance, and auditing workflows, the registry acts as an immutable record of what’s available analytically and what’s actually running in production.
So far, we’ve looked at the core minimal components of a feature store. In practice, companies often have needs like compliance, governance, and security that require additional enterprise-focused capabilities. That will be the topic of a future blog post.
Getting Started With Feature Stores
We see features stores as the heart of the data flow in modern ML applications. They are quickly proving to be critical infrastructure for data science teams putting ML into production. We expect the number of organizations to use feature stores to quadruple by 2028
There are a few options for getting started with feature stores:
- Feast is a great option if you already have transformation pipelines to compute your features, but need a great storage and serving layer to help you use them in production. Feast is GCP only today, but we’re working hard to make Feast available as a light-weight feature store for all environments. Stay tuned.
- Tecton is a feature-platform-as-a-service. A big difference between Feast and Tecton is that Tecton supports transformations, so feature pipelines can be managed end-to-end within Tecton. Tecton is a managed offering, and a great feature store choice if you need production SLAs, hosting, advanced collaboration, managed transformations (batch/streaming/real-time), and/or enterprise capabilities.
We wrote this blog post to provide a common definition of feature stores as they emerge as a primary component of the operational ML stack. We believe the industry is about to see an explosion of activity in this space.
If you think we got anything wrong above or have any questions, we’d love to hear from you, just shoot us an email at hello@tecton.ai or come and say hello in the Feast community. We’d love to hear from you!


